深入Ceph原理包含核心算法Crush说明和通信机制原理(五)【与云原生的故事】

【摘要】 CRUSH 算法,全称 Controlled Replication Under Scalable Hashing (可扩展哈希下的受控复制),它是一个可控的、可扩展的、分布式的副本数据放置算法, 通过CRUSH 算法来计算数据存储位置来确定如何存储和检索数据。
一、Crush算法与作用
CRUSH 算法,全称 Controlled Replication Under Scalable Hashing (可扩展哈希下的受控复制),它是一个可控的、可扩展的、分布式的副本数据放置算法, 通过CRUSH 算法来计算数据存储位置来确定如何存储和检索数据。
- 保障数据分布的均衡性
- 集群的灵活伸缩性
- 支持更大规模的集群
二、Crush算法说明
PG 到 OSD 的映射的过程算法称为 CRUSH 算法,它是一个伪随机的过程,可以从所有的 OSD 中,随机性选择一个OSD 集合。
Crush Map 将系统的所有硬件资源描述成一个树状结构,然后再基于这个结构按照一定的容错规则生成一个逻辑上的树形结构,树的末级叶子节点device 也就是 OSD ,其他节点称为 bucket 节点,根据物理结构抽象的虚拟节点,包含数据中心抽象、机房抽象、机架抽象、主机抽象。
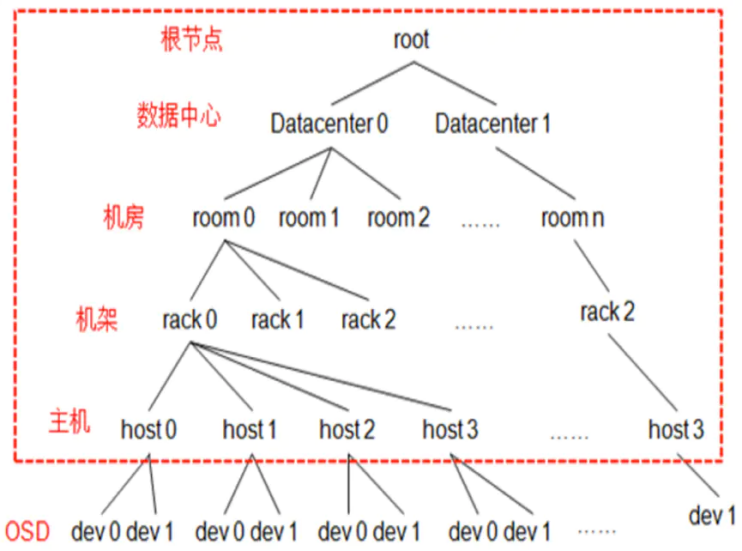
三、Crush算法原理
1、Ceph的存储结构
Ceph 为了保存对象,会先构建一个池( pool ),把 pool 可以比喻成一个仓库,一个新对象的保存就类似于把一个包裹放到仓库里面。
2、PG的分配存储
对象是如何保存至哪个 PG 上?假设 Pool 名称为 rbd ,共有 256 个 PG ,每个 PG 编个号分别叫做 0x0, 0x1, 0x2 ,... 0xFF 。 具体该如何分配?这里可以采用 Hash 方式计算。假设有两个对象名, 分别为bar 和 foo 的,根据对象名做 Hash 计算:
HASH ( ‘bar’ ) = 0x3E0A4162HASH ( ‘foo’ ) = 0x7FE391A0
通过 Hash 得到一串随机的十六进制的值, 对于同样的对象名,计算出的结果能够永远保持一致,但我们预分配的是256 个 PG ,这就需要再进行取模处理, 所得的结果会落在【 0x0 , 0xFF 】区间:
0x3E0A4162 % 0xFF ===> 0x620x7FE391A0 % 0xFF ===> 0xA0
实际在Ceph中, 存在很多个Pool,每个Pool里面存在若干个PG,如果两个Pool里面的PG编号相同,该如何标识区分?Ceph会对每个pool再进行编号,一个PG的实际编号是由pool_id + . + pg_id组成。
3、OSD的分配存储
Ceph 的物理层,对应的是服务器上的磁盘, Ceph 将一个磁盘或分区作为 OSD ,在逻辑层面,对象是保存至PG 内,现在需要打通 PG 与 OSD 之间的联系, Ceph 当中会存在较多的 PG 数量,如何将 PG平均分布各个OSD 上面,这就是 Crush 算法主要做的事情: 计算 PG -> OSD 的映射关系。
上述所知, 主要两个计算步骤:
POOL_ID (对象池) + HASH (‘对象名称 ’ ) % pg _ num (归置组)==> PG _ ID (完整的归置组编号)CRUSH ( PG _ ID )==> OSD (对象存储设备位置)
4、为什么需要采用Crush算法
如果把 CRUSH ( PG _ ID )改成 HASH ( PG_ID ) % OSD_NUM 能否适用? 是会存在一些问题。
1 )如果挂掉一个 OSD ,所有的 OSD_NUM 余数就会发生变化,之前的数据就可能需要重新打乱整理, 一个优秀的存储架构应当在出现故障时, 能够将数据迁移成本降到最低,CRUSH 则可以做到。2 )如果增加一个 OSD, OSD_NUM 数量增大, 同样会导致数据重新打乱整理,但是通过CRUSH可以保障数据向新增机器均匀的扩散, 且不需要重新打乱整理。3 )如果保存多个副本,就需要能够获取多个 OSD 结果的输出, 但是 HASH 方式只能获取一个, 但是通过CEPH 的 CRUSH 算法可以做到获取多个结果。
5、Crush算法如何实现
每个 OSD 有不同的容量,比如是 4T 还是 800G 的容量,可以根据每个 OSD 的容量定义它的权重,以 T为单位, 比如4T 权重设为 4 , 800G 则设为 0.8 。
那么如何将 PG 映射到不同权重的 OSD 上面?这里可以直接采用 CRUSH 里面的 Straw 抽签算法,这里面的抽签是指挑取一个最长的签,而这个签值就是OSD 的权重。
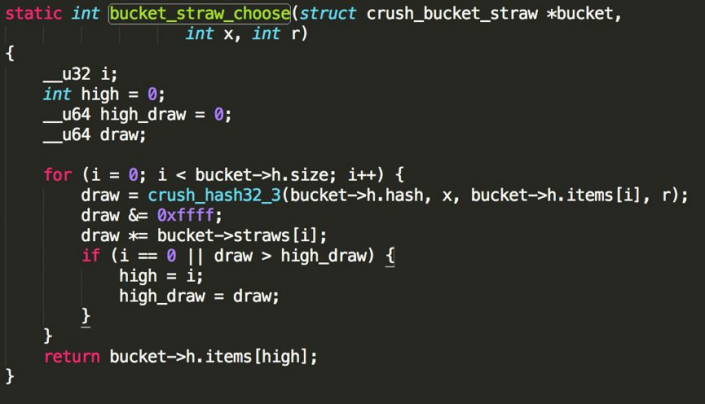
主要步骤:
- 计算HASH: CRUSH_HASH( PG_ID, OSD_ID, r ) ==> draw把r当做一个常数,将PG_ID, OSD_ID一起作为输入,得到一个HASH值。
- 增加OSD权重: ( draw &0xffff ) * osd_weight ==> osd_straw 将计算出的HASH值与OSD的权重放置一起,这样就能够得到每个OSD的签长, 权重越大的,数值越大。
- 遍历选取最高的权重:high_draw
Crush 目的是随机跳出一个 OSD ,并且要满足权重越大的 OSD ,挑中的概率越大。如果样本容量足够大, 随机数对选中的结果影响逐渐变小, 起决定性的是OSD 的权重, OSD 的权重越大, 被挑选的概率也就越大。
Crush 所计算出的随机数,是通过 HASH 得出来,可以保障相同的输入会得出同样的输出结果。 所以Crush 并不是真正的随机算法, 而是一个伪随机算法。
这里只是计算得出了一个 OSD ,在 Ceph 集群中是会存在多个副本,如何解决一个 PG 映射到多个OSD的问题?
将之前的常量 r 加 1 , 再去计算一遍,如果和之前的 OSD 编号不一样, 那么就选取它;如果一样的话,那么再把r+2 ,再重新计算,直到选出三个不一样的 OSD 编号。
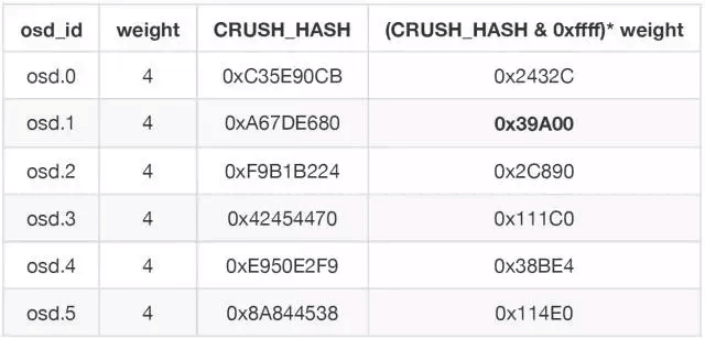
假设常数 r=0 ,根据算法 (CRUSH_HASH & 0xFFFF) * weight 计算最大的一个 OSD ,结果为 osd.1 的0x39A00,也就是选出的第一个 OSD ,然后再让 r=1 , 生成新的 CRUSH_HASH 随机值,取得第二个OSD,依次得到第三个 OSD 。
四、IO流程图
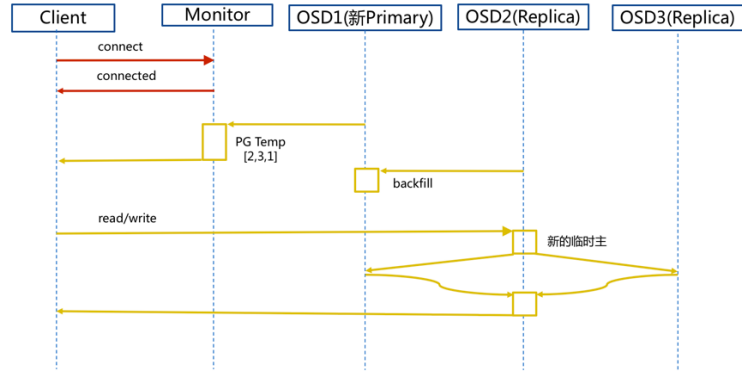
步骤:
1. client 连接 monitor 获取集群 map 信息。
2. 同时新主 osd1 由于没有 pg 数据会主动上报 monitor 告知让 osd2 临时接替为主。
3. 临时主 osd2 会把数据全量同步给新主 osd1 。
4. client IO 读写直接连接临时主 osd2 进行读写。
5. osd2 收到读写 io ,同时写入另外两副本节点。
6. 等待 osd2 以及另外两副本写入成功。
7. osd2 三份数据都写入成功返回给 client, 此时 client io 读写完毕。
8. 如果 osd1 数据同步完毕,临时主 osd2 会交出主角色。
9. osd1 成为主节点, osd2 变成副本。
五、Ceph 通信机制
网络通信框架三种不同的实现方式:
Simple线程模式
- 特点:每一个网络链接,都会创建两个线程,一个用于接收,一个用于发送。
- 缺点:大量的链接会产生大量的线程,会消耗CPU资源,影响性能。
Async事件的I/O多路复用模式
- 特点:这种是目前网络通信中广泛采用的方式。新版默认已经使用Asnyc异步方式了。
XIO方式使用了开源的网络通信库accelio来实现
- 特点:这种方式需要依赖第三方的库accelio稳定性,目前处于试验阶段。
消息的内容主要分为三部分:
header //消息头类型消息的信封
user data //需要发送的实际数据
- payload //操作保存元数据
- middle //预留字段
- data //读写数据
footer //消息的结束标记
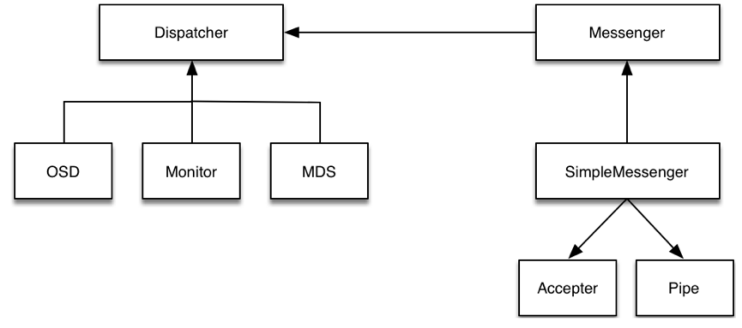
步骤:
- Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe, 给SimpleMessenger::pipes 来处理该请求。
- Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
- Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
- Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通处理。
- DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。
六、Ceph RBD 块存储 IO流程图
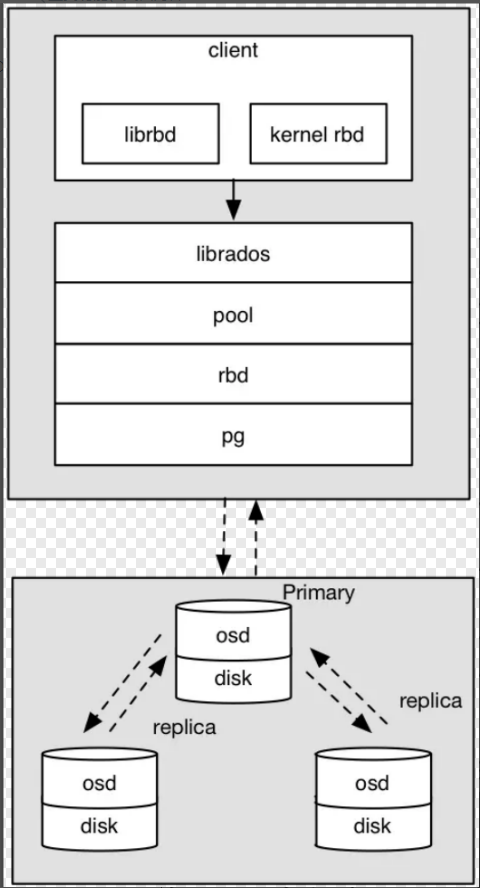
osd写入过程:
- 采用的是librbd的形式,使用librbd创建一个块设备,向这个块设备中写入数据。
- 在客户端本地通过调用librados接口,然后经过pool,rbd,object、pg进行层层映射,在PG这一层中,可以知道数据是保存在哪三个OSD上,这三个OSD分别为主从的关系。
- 客户端与primary OSD建立SOCKET 通信,将要写入的数据传给primary OSD,由primary OSD再将数据发送给其他replica OSD数据节点。
七、Ceph 心跳和故障检测机制
问题:
故障检测时间和心跳报文带来的负载 , 如何权衡降低压力 ?
- 心跳频率太高则过多的心跳报文会影响系统性能。
- 心跳频率过低则会延长发现故障节点的时间,从而影响系统的可用性。
故障检测策略应该能够做到:
及时性:节点发生异常如宕机或网络中断时,集群可以在可接受的时间范围内感知。
适当的压力:包括对节点的压力,和对网络的压力。
容忍网络抖动:网络偶尔延迟。
扩散机制:节点存活状态改变导致的元信息变化需要通过某种机制扩散到整个集群。
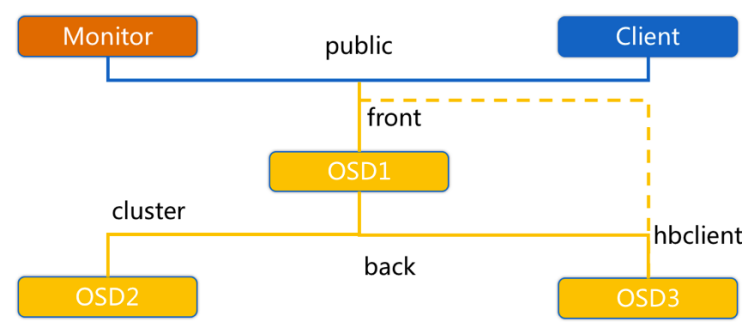
OSD节点会监听public、cluster、front和back四个端口
- public端口:监听来自Monitor和Client的连接。
- cluster端口:监听来自OSD Peer的连接。
- front端口:客户端连接集群使用的网卡, 这里临时给集群内部之间进行心跳。
- back端口:在集群内部使用的网卡。集群内部之间进行心跳。
- hbclient:发送ping心跳的messenger(送信者)。
【与云原生的故事】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/345260

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)