域对抗(域适应)训练

在传统监督学习中,我们经常需要大量带标签的数据进行训练,并且需要保证训练集和测试集中的数据分布相似。如果训练集和测试集的数据具有不同的分布,训练后的分类器在测试集上就没有好的表现。这种情况下该怎么办呢?
域适应(Domain Adaption),也可称为域对抗(Domain Adversarial),是迁移学习中一个重要的分支,用以消除不同域之间的特征分布差异。其目的是把具有不同分布的源域(Source Domain) 和目标域 (Target Domain) 中的数据,映射到同一个特征空间,寻找某一种度量准则,使其在这个空间上的“距离”尽可能近。然后,我们在源域 (带标签) 上训练好的分类器,就可以直接用于目标域数据的分类。
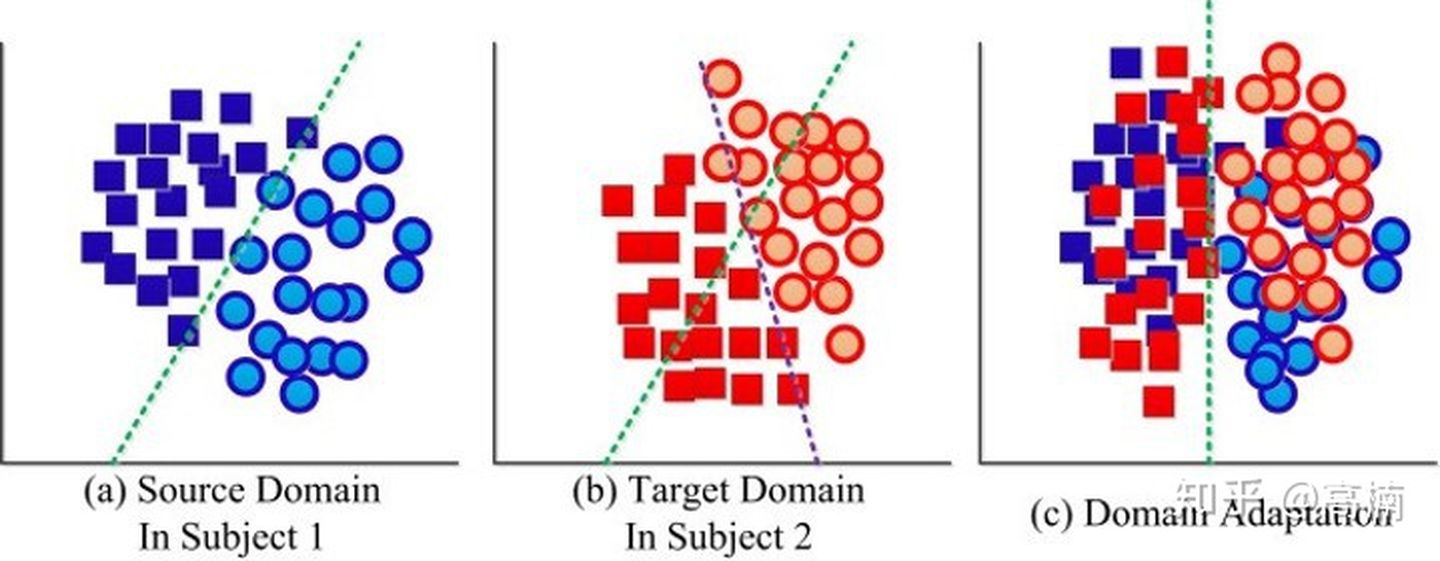
如上图所示,图a为源域样本分布(带标签),图b为目标域样本分布,它们具有共同的特征空间和标签空间,但源域和目标域通常具有不同的分布,这就意味着我们无法将源域训练好的分类器,直接用于目标域样本的分类。因此,在域适应问题中,我们尝试对两个域中的数据做一个映射,使得属于同一类(标签)的样本聚在一起。此时,我们就可以利用带标签的源域数据,训练分类器供目标域样本使用。
2. DANN简介(Domain-Adversarial Neural Networks)
Domain adaptation 过程中最关键的一点就是如何做到将源域样本和目标域样本混合在一起,并且还能保证被同时分开,DANN的主要任务之一就是这个。

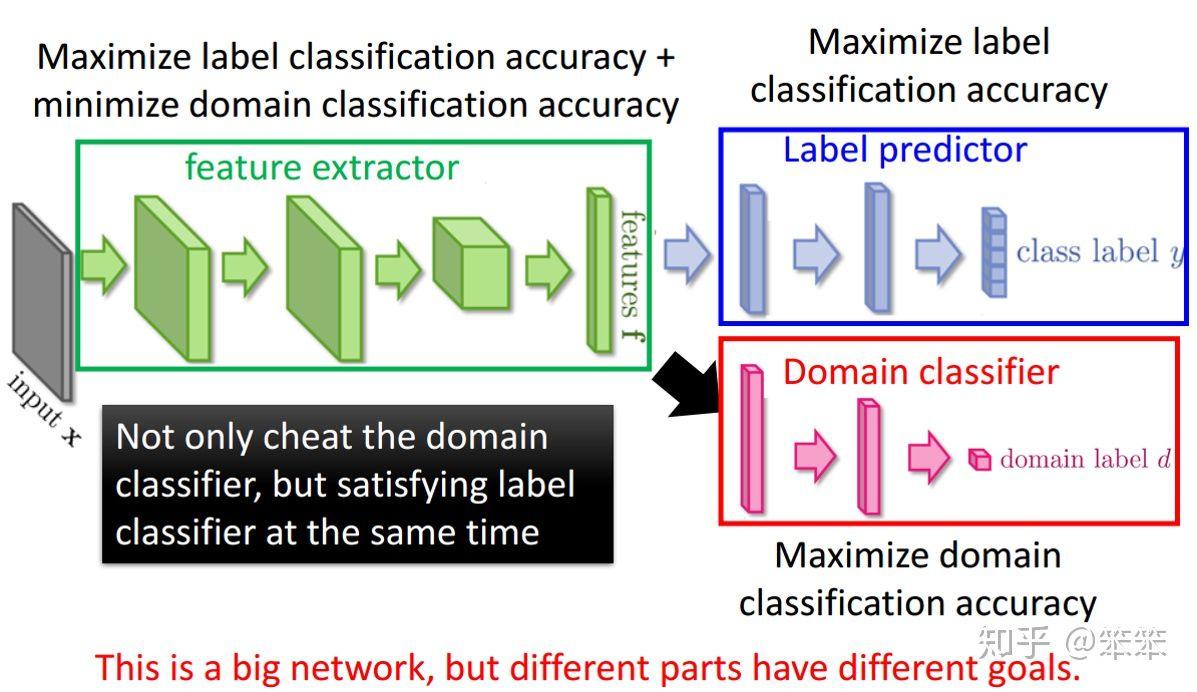
如上图所示,DANN结构主要包含3个部分:
特征提取器 (feature extractor) - 图示绿色部分:1)将源域样本和目标域样本进行映射和混合,使域判别器无法区分数据来自哪个域;2)提取后续网络完成任务所需要的特征,使标签预测器能够分辨出来自源域数据的类别
标签预测器 (label predictor) - 图示蓝色部分:对来自源域的数据进行分类,尽可能分出正确的标签。
域判别器(domain classifier)- 图示红色部分:对特征空间的数据进行分类,尽可能分出数据来自哪个域。
2.1 DANN整体流程
特征提取器提取的信息会传入域分类器,之后域分类器会判断传入的信息到底是来自源域还是目标域,并计算损失。域分类器的训练目标是尽量将输入的信息分到正确的域类别(源域还是目标域),而特征提取器的训练目标却恰恰相反(由于梯度反转层的存在),特征提取器所提取的特征(或者说映射的结果)目的是是域判别器不能正确的判断出信息来自哪一个域,因此形成一种对抗关系。
特征提取器提取的信息也会传入Label predictor (类别预测器)了,因为源域样本是有标记的,所以在提取特征时不仅仅要考虑后面的域判别器的情况,还要利用源域的带标记样本进行有监督训练从而兼顾分类的准确性。
2.2 梯度反转层(Gradient reversal layer)
在反向传播更新参数的过程中,梯度下降是最小化目标函数,而特征提取器任务是最大化label分类准确率但最小化域分类准确率,因此要最大化域判别器目标函数。因此,在域分类器和特征提取器中间有一个梯度反转层(Gradient reversal layer),在粉色部分的参数向Ld减小的方向优化,绿色部分的梯度向Ld增大的方向优化,用一个网络一个优化器就实现了两部分有不一样的优化目标,形成对抗的关系。
具体的:GRL就是将传到本层的误差乘以一个负数(-),这样就会使得GRL前后的网络其训练目标相反,以实现对抗的效果。
PyTorch代码实现:
-
import torch
-
from torch.autograd import Function
-
-
class GRL(Function):
-
def __init__(self,lambda_):
-
super(GRL, self).__init__()
-
self.lambda_=lambda_
-
-
def forward(self, input):
-
return input
-
-
def backward(self, grad_output):
-
grad_input = grad_output.neg()
-
return grad_input*self.lambda_
-
-
x = torch.tensor([1., 2., 3.], requires_grad=True)
-
y = torch.tensor([4., 5., 6.], requires_grad=True)
-
-
z = torch.pow(x, 2) + torch.pow(y, 2)
-
f = z + x + y
-
-
-
Grl = GRL(lambda_=1)
-
s = 6 * f.sum()
-
s = Grl(s)
-
-
print(s)
-
s.backward()
-
print(x.grad)
-
print(y.grad)
结果:
tensor(672., grad_fn=<GRL>)
tensor([-18., -30., -42.])
tensor([-54., -66., -78.])
这个运算过程对于tensor中的每个维度上的运算为:

那么对于x的导数为:
所以当输入x=[1,2,3]时,原本对应的梯度为:[18,30,42],由于GRL存在,梯度为:[-18,-30,-42]
2.3 损失计算
在训练的过程中,对来自源域的带标签数据,网络不断最小化标签预测器的损失 (loss)。对来自源域和目标域的全部数据,网络不断最小化域判别器的损失。
以单隐层为例,对于特征提取器就是一层简单的神经元(复杂任务中就是用多层):
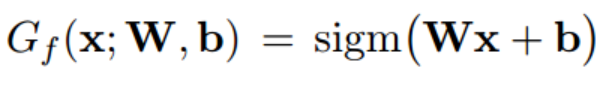
对于类别预测器:
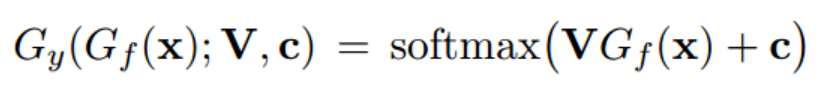
Loss:
因此在源域上,训练优化目标就是:

对于域分类器:
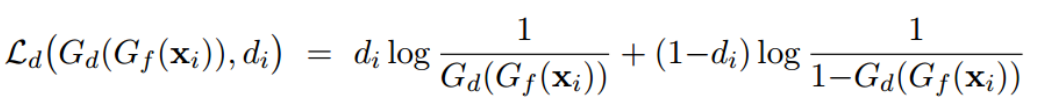
Loss:
训练优化目标是:

总体的损失函数是:
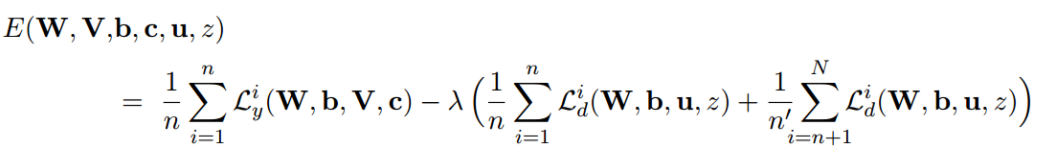
其中,迭代过程,通过最小化目标函数来更新标签预测器的参数,最大化目标函数来更新域判别器的参数。
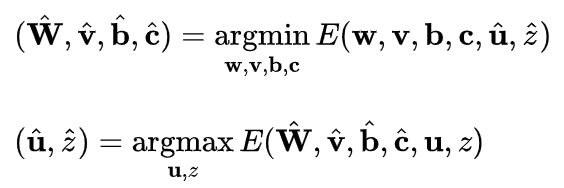
3. 与GAN对比

生成对抗网络包含一个生成器(Generator)和一个判别器(Discriminator)。生成器用来生成假图片,判别器则用来区分,输入的图片是真图片还是假图片。生成器希望生成的图片可以骗过判别器(以假乱真),而判别器则希望提高辨别能力防止被骗。两者互相博弈,直到系统达到一个稳定状态(纳什平衡)。
在域适应问题中, 存在一个源域和目标域。和生成对抗网络相比,域适应问题免去了生成样本的过程,直接将目标域中的数据看作生成的样本。因此,生成器的目的发生了变化,不再是生成样本,而是扮演了一个特征提取(feature extractor)的功能。
————————————————
版权声明:本文为CSDN博主「Janie.Wei」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weijie_home/article/details/119921964
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/123844308

- 点赞
- 收藏
- 关注作者
评论(0)