Flink和Spark读写avro文件

【摘要】 前面文章基于Java实现Avro文件读写功能我们说到如何使用java读写avro文件,本文基于上述文章进行扩展,展示flink和spark如何读取avro文件。 Flink读写avro文件flink支持avro文件格式,内置如下依赖:<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-avro</artif...
前面文章基于Java实现Avro文件读写功能我们说到如何使用java读写avro文件,本文基于上述文章进行扩展,展示flink和spark如何读取avro文件。
Flink读写avro文件
flink支持avro文件格式,内置如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>
使用flink sql将数据以avro文件写入本地。首先创建t1表
CREATE TABLE t1(
uuid VARCHAR(20),
name VARCHAR(20),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITION BY (`partition`)
WITH (
'connector' = 'filesystem',
'path' = 'file:///e:/code/data/t1',
'format' = 'avro'
)
将数据写入t1表中
INSERT INTO t1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');
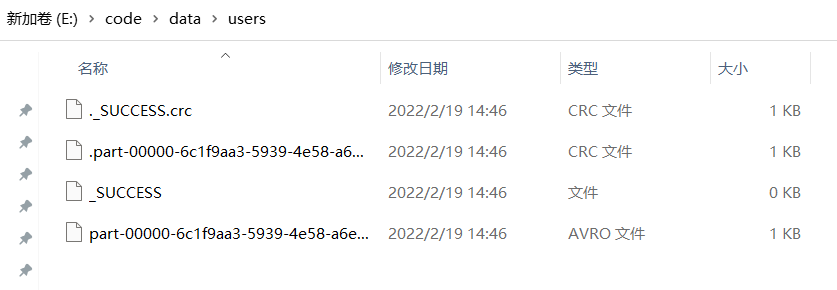
查看本地文件:
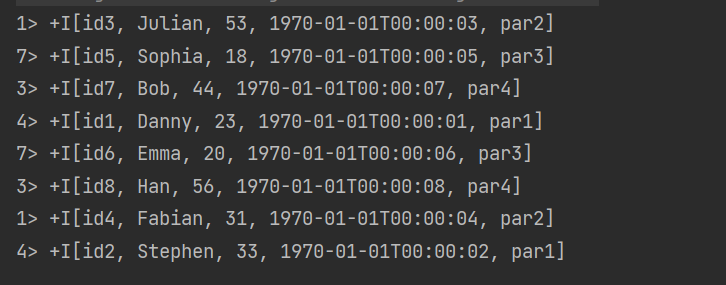
数据读取:
select * from t1;
得到:
Spark读写avro文件
在文章基于Java实现Avro文件读写功能中我们使用java写了一个users.avro文件,现在使用spark读取该文件并重新将其写入新文件中:
SparkConf sparkConf = new SparkConf()
.setMaster("local")
.setAppName("Java Spark SQL basic example");
SparkContext sparkContext = new SparkContext(sparkConf);
SparkSession spark = SparkSession
.builder()
.sparkContext(sparkContext)
.getOrCreate();
Dataset<Row> usersDF = spark.read().format("avro").load("users.avro");
usersDF.select("name", "favorite_color").write().format("avro").save("file:///e:/code/data/users");
得到:

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)