每日算法&面试题,大厂特训二十八天——第十六天(链表)

导读
肥友们为了更好的去帮助新同学适应算法和面试题,最近我们开始进行专项突击一步一步来。上一期我们完成了动态规划二十一天现在我们进行下一项对各类算法进行二十八天的一个小总结。还在等什么快来一起肥学进行二十八天挑战吧!!
特别介绍
📣小白练手专栏,适合刚入手的新人欢迎订阅编程小白进阶
📣python有趣练手项目里面包括了像《机器人尬聊》《恶搞程序》这样的有趣文章,可以让你快乐学python练手项目专栏
📣另外想学JavaWeb进厂的同学可以看看这个专栏:传送们
📣这是个冲刺大厂面试专栏还有算法比赛练习我们一起加油 上岸之路
算法特训二十八天
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos
来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。如果链表中存在环 ,则返回 true 。 否则,返回 false 。
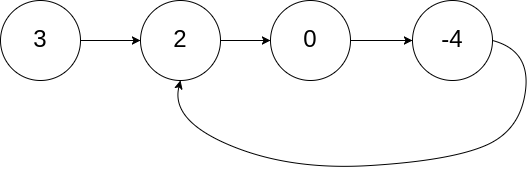
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
- 1
- 2
- 3
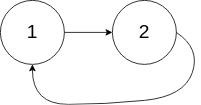
输入:head = [1,2], pos = 0
输出:true
解释:链表中有一个环,其尾部连接到第一个节点。
- 1
- 2
- 3

输入:head = [1], pos = -1
输出:false
解释:链表中没有环。
- 1
- 2
- 3
思路:最容易想到的方法是遍历所有节点,每次遍历到一个节点时,判断该节点此前是否被访问过。
具体地,我们可以使用哈希表来存储所有已经访问过的节点。每次我们到达一个节点,如果该节点已经存在于哈希表中,则说明该链表是环形链表,否则就将该节点加入哈希表中。重复这一过程,直到我们遍历完整个链表即可。
public class Solution {
public boolean hasCycle(ListNode head) {
Set<ListNode> seen = new HashSet<ListNode>();
while (head != null) {
if (!seen.add(head)) {
return true;
}
head = head.next;
}
return false;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。

输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]
- 1
- 2
输入:l1 = [], l2 = []
输出:[]
- 1
- 2
输入:l1 = [], l2 = [0]
输出:[0]
- 1
- 2
思路:t 是 ss 的异位词等价于「两个字符串排序后相等」。因此我们可以对字符串 ss 和 tt
分别排序,看排序后的字符串是否相等即可判断。此外,如果 ss 和 tt 的长度不同,tt 必然不是 ss 的异位词。
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode prehead = new ListNode(-1);
ListNode prev = prehead;
while (l1 != null && l2 != null) {
if (l1.val <= l2.val) {
prev.next = l1;
l1 = l1.next;
} else {
prev.next = l2;
l2 = l2.next;
}
prev = prev.next;
}
// 合并后 l1 和 l2 最多只有一个还未被合并完,我们直接将链表末尾指向未合并完的链表即可
prev.next = l1 == null ? l2 : l1;
return prehead.next;
}
}

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
面试题
Redis 持久化 RDB 和 AOF 优缺点
RDB
RDB 持久化方式,是将 Redis 某一时刻的数据持久化到磁盘中,是一种快照式的持久化方
法。
RDB 优点:
RDB 是一个非常紧凑(有压缩)的文件,它保存了某个时间点的数据,非常适用于数据的备
份。
RDB 作为一个非常紧凑(有压缩)的文件,可以很方便传送到另一个远端数据中心 ,非
常适用于灾难恢复。
RDB 在保存 RDB 文件时父进程唯一需要做的就是 fork 出一个子进程,接下来的工作全
部由子进程来做,父进程不需要再做其他 IO 操作,所以 RDB 持久化方式可以最大化
redis 的性能。
与 AOF 相比,在恢复大的数据集的时候,RDB 方式会更快一些。
RDB 缺点:
Redis 意外宕机时,会丢失部分数据。
当 Redis 数据量比较大时,fork 的过程是非常耗时的,fork 子进程时是会阻塞的,在这
期间 Redis 是不能响应客户端的请求的。
AOF
AOF 方式是将执行过的写指令记录下来,在数据恢复时按照从前到后的顺序再将指令都执行
一遍。
AOF 优点:
使用 AOF 会让你的 Redis 更加持久化。
AOF 文件是一个只进行追加的日志文件,不需要在写入时读取文件。
Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写 。
AOF 文件可读性高,分析容易。
AOF 缺点:
对于相同的数据来说,AOF 文件大小通常要大于 RDB 文件。
根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
点击直接资料领取
这里有python,Java学习资料还有有有趣好玩的编程项目,更有难寻的各种资源。反正看看也不亏。
文章来源: blog.csdn.net,作者:肥学,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jiahuiandxuehui/article/details/122714534

- 点赞
- 收藏
- 关注作者
评论(0)