pytorch 多卡训练,模型保存的一些问题

【摘要】 单显卡先看单显卡如何实现训练:第一步:检查环境内是否有cuda环境,如果有则将device 设置为cuda,如果没有则设置为cpu device = torch.device("cuda" if torch.cuda.is_available() else "cpu")第二步:定义模型,并将模型放入device。model = mobilenet_v3_large(pretrained=T...
单显卡
先看单显卡如何实现训练:
第一步:检查环境内是否有cuda环境,如果有则将device 设置为cuda,如果没有则设置为cpu
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
第二步:定义模型,并将模型放入device。
model = mobilenet_v3_large(pretrained=True)
model.to(DEVICE)
第三步:将数据放入device中
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
第四步:保存模型
torch.save(model, 'model_.pth')
接下来,我们看看多显卡训练过程和单显卡有何不同
多显卡
第一步:检查环境内是否有cuda环境,如果有则将device 设置为cuda:0,如果没有则设置为cpu。
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
第二步:定义模型,并将模型放入device。如果环境中有多张显卡,则使用torch.nn.DataParallel方法加载模型,实现多卡训练。
model = mobilenet_v3_large(pretrained=True)
model.to(DEVICE)
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = torch.nn.DataParallel(model)
第三步:将数据放入device中。数据默认加载到第一张显卡上。
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
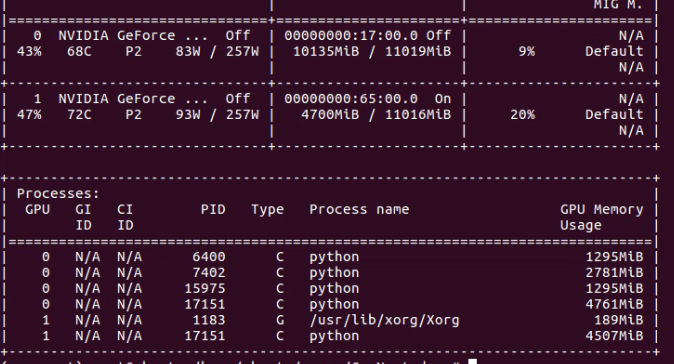
第四步:保存模型,判断是否是多张显卡训练出来的模型。如果是多张显卡训练的模型则要保存model.module。
if isinstance(model, torch.nn.DataParallel):
torch.save(model.module, 'model_.pth')
else:
torch.save(model, 'model_.pth')

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)