还在为模型加速推理发愁吗?不如看看这篇吧。手把手教你把pytorch模型转化为TensorRT,加速推理

@[toc]
摘要
最近,学习了一些模型转化和加速推理的知识,本文是对学习成果的总结。
对模型的转化,本文实现了pytorch模型转onnx模型和onnx转TensorRT,在转为TensorRT模型的过程中,实现了模型单精度的压缩。
对于加速推理,本文实现GPU环境下的onnxruntime推理、TensorRT动态推理和TensorRT静态推理。
希望本文能帮助大家。
环境配置
CUDA版本:11.3.1
cuDNN版本:8.2.1
TensorRT版本:8.0.3.4
显卡:1650
pytorch:1.10.2
模型的转化和推理对版本有要求,如果版本对应不上很可能出现千奇百怪的问题,所以我把我的版本信息列出来给大家做参考。
ONNX
ONNX,全称:Open Neural Network Exchange(ONNX,开放神经网络交换),是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。—维基百科
onnx模型可以看作是模型转化之间的中间模型,同时也是支持做推理的。一般来说,onnx的推理速度要比pytorch快上一倍。
模型转化
onnx模型转换和推理需要安装Python包,如下:
pip install onnx
pip install onnxruntime-gpu
import torch
from torch.autograd import Variable
import onnx
import netron
print(torch.__version__)
input_name = ['input']
output_name = ['output']
input = Variable(torch.randn(1, 3, 224, 224)).cuda()
model = torch.load('model.pth', map_location="cuda:0")
torch.onnx.export(model, input, 'model_onnx.onnx',opset_version=13, input_names=input_name, output_names=output_name, verbose=True)
# 模型可视化
netron.start('model_onnx.onnx')
导入需要的包。
打印pytorch版本。
定义input_name和output_name变量。
定义输入格式。
加载pytorch模型。
导出onnx模型,这里注意一下参数opset_version在8.X版本中设置为13,在7.X版本中设置为12。
yolov5中这么写的。
if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
grid = model.model[-1].anchor_grid
model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
export_onnx(model, im, file, 12, train, False, simplify) # opset 12
model.model[-1].anchor_grid = grid
else: # TensorRT >= 8
check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
export_onnx(model, im, file, 13, train, False, simplify) # opset 13
查看转化后的模型,如下图:
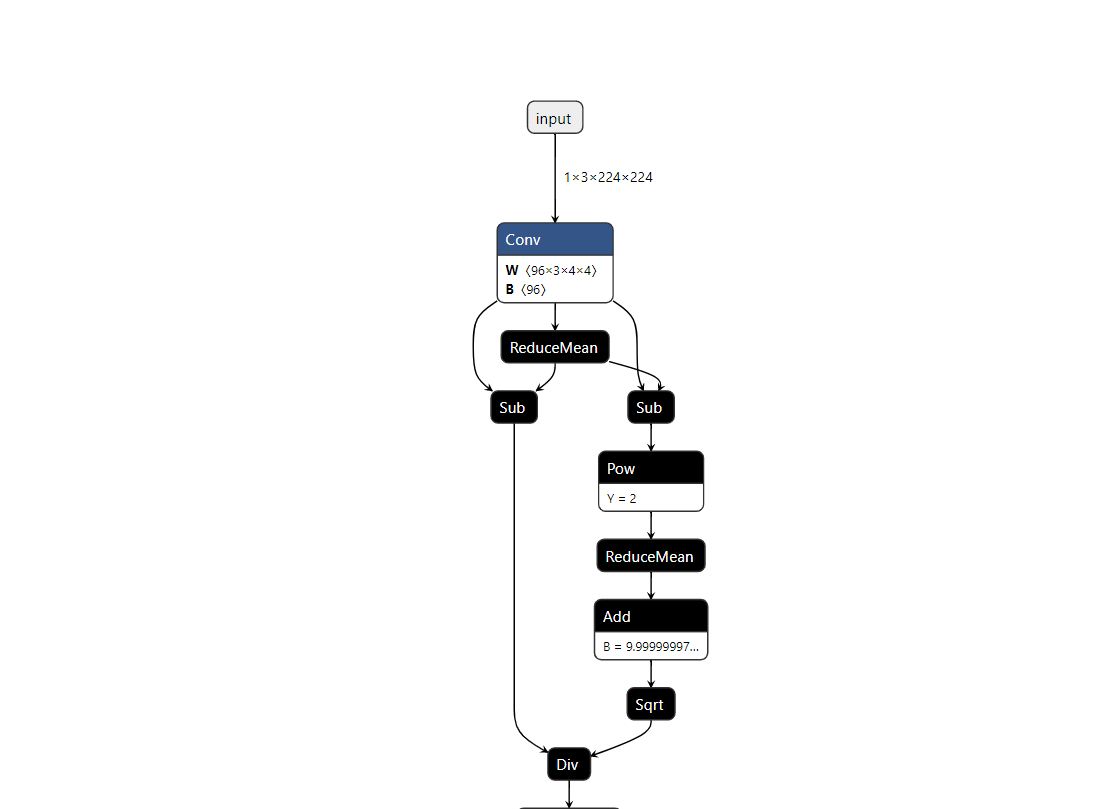
推理的写法有两种,一种直接写,另一种将其封装为通用的推理类。
第一种推理写法
先看第一种写法,新建test_onnx.py,插入下面的代码:
import os, sys
import time
sys.path.append(os.getcwd())
import onnxruntime
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
导入包
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open('11.jpg') # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0) # -> NCHW, 1,3,224,224
print("input img mean {} and std {}".format(img.mean(), img.std()))
img = np.array(img)
定义get_test_transform函数,实现图像的归一化和resize。
读取图像。
对图像做resize和归一化。
增加一维batchsize。
将图片转为数组。
onnx_model_path = "model_onnx.onnx"
##onnx测试
session = onnxruntime.InferenceSession(onnx_model_path,providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])
#compute ONNX Runtime output prediction
inputs = {session.get_inputs()[0].name: img}
time3=time.time()
outs = session.run(None, inputs)[0]
y_pred_binary = np.argmax(outs, axis=1)
print("onnx prediction", y_pred_binary[0])
time4=time.time()
print(time4-time3)
定义onnx_model_path模型的路径。
加载onnx模型。
定义输入。
执行推理。
获取预测结果。
到这里第一种写法就完成了,是不是很简单,接下来看第二种写法。
第二种推理写法
新建onnx.py脚本,加入以下代码:
import onnxruntime
class ONNXModel():
def __init__(self, onnx_path):
"""
:param onnx_path:
"""
self.onnx_session = onnxruntime.InferenceSession(onnx_path,providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider'])
self.input_name = self.get_input_name(self.onnx_session)
self.output_name = self.get_output_name(self.onnx_session)
print("input_name:{}".format(self.input_name))
print("output_name:{}".format(self.output_name))
def get_output_name(self, onnx_session):
"""
output_name = onnx_session.get_outputs()[0].name
:param onnx_session:
:return:
"""
output_name = []
for node in onnx_session.get_outputs():
output_name.append(node.name)
return output_name
def get_input_name(self, onnx_session):
"""
input_name = onnx_session.get_inputs()[0].name
:param onnx_session:
:return:
"""
input_name = []
for node in onnx_session.get_inputs():
input_name.append(node.name)
return input_name
def get_input_feed(self, input_name, image_numpy):
"""
input_feed={self.input_name: image_numpy}
:param input_name:
:param image_numpy:
:return:
"""
input_feed = {}
for name in input_name:
input_feed[name] = image_numpy
return input_feed
def forward(self, image_numpy):
# 输入数据的类型必须与模型一致,以下三种写法都是可以的
# scores, boxes = self.onnx_session.run(None, {self.input_name: image_numpy})
# scores, boxes = self.onnx_session.run(self.output_name, input_feed={self.input_name: iimage_numpy})
input_feed = self.get_input_feed(self.input_name, image_numpy)
scores = self.onnx_session.run(self.output_name, input_feed=input_feed)
return scores
调用onnx.py实现推理,新建test_onnx1.py插入代码:
import os, sys
sys.path.append(os.getcwd())
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
from models.onnx import ONNXModel
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open('11.jpg') # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0) # -> NCHW, 1,3,224,224
print("input img mean {} and std {}".format(img.mean(), img.std()))
img = np.array(img)
onnx_model_path = "model_onnx.onnx"
model1 = ONNXModel(onnx_model_path)
out = model1.forward(img)
y_pred_binary = np.argmax(out[0], axis=1)
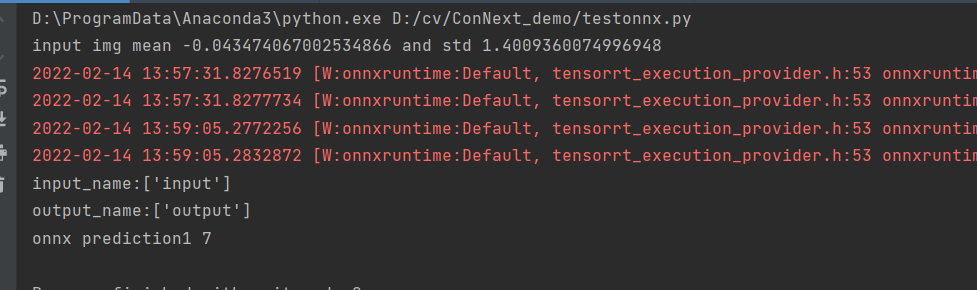
print("onnx prediction1", y_pred_binary[0])
输出结果如下:
TensorRT
TensorRT是英伟达推出的一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。
TensorRT 是一个C++库,从 TensorRT 3 开始提供C++ API和Python API,主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
TensorRT的安装可以参考我以前的文章:
https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/120360288。
本次用的8.X版本的,安装方式一样。
本文实现Python版本的 TensorRT 推理加速,需要安装tensorrt包文件。这个文件不能直接通过pip下载,我在下载的TensorRT安装包里,不过我下载的8.0.3.4版本中并没有,在8.2.1.8的版本中存在这个包文件。
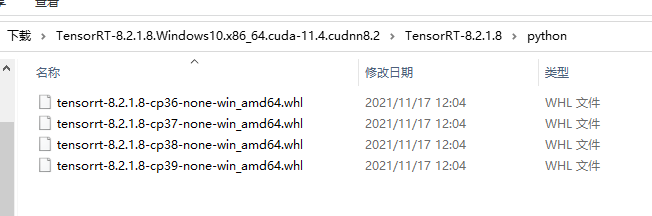
所以我安装了8.2.1.8中的whl文件。
安装方式,进入模型所在的目录,执行:
pip install tensorrt-8.2.1.8-cp39-none-win_amd64.whl
模型推理用到了pycuda,执行安装命令:
pip install pycuda
模型转化
将onnx模型转为TensorRT 模型,新建onnx2trt.py,插入代码:
import tensorrt as trt
def build_engine(onnx_file_path,engine_file_path,half=False):
"""Takes an ONNX file and creates a TensorRT engine to run inference with"""
logger = trt.Logger(trt.Logger.INFO)
builder = trt.Builder(logger)
config = builder.create_builder_config()
config.max_workspace_size = 4 * 1 << 30
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
network = builder.create_network(flag)
parser = trt.OnnxParser(network, logger)
if not parser.parse_from_file(str(onnx_file_path)):
raise RuntimeError(f'failed to load ONNX file: {onnx_file_path}')
half &= builder.platform_has_fast_fp16
if half:
config.set_flag(trt.BuilderFlag.FP16)
with builder.build_engine(network, config) as engine, open(engine_file_path, 'wb') as t:
t.write(engine.serialize())
return engine_file_path
if __name__ =="__main__":
onnx_path1 = 'model_onnx.onnx'
engine_path = 'model_trt.engine'
build_engine(onnx_path1,engine_path,True)
build_engine函数共有三个参数:
onnx_file_path:onnx模型的路径。
engine_file_path:TensorRT模型的路径。
half:是否使用单精度。
单精度的模型速度更快,所以我选择使用单精度。
通过上面的代码就可以完成模型的转化,下面开始实现推理部分,推理分为动态推理和静态推理。
动态推理
新建test_trt,py文件,插入代码:
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
导入需要的包。
def load_engine(engine_path):
# TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # INFO
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
# 2. 读取数据,数据处理为可以和网络结构输入对应起来的的shape,数据可增加预处理
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
定义load_engine函数和get_test_transform函数。
load_engine用于加载TensorRT模型。
get_test_transform实现图像的resize和归一化。
image = Image.open('11.jpg') # 289
image = get_test_transform()(image)
image = image.unsqueeze_(0) # -> NCHW, 1,3,224,224
print("input img mean {} and std {}".format(image.mean(), image.std()))
image = np.array(image)
图片的预处理,和onnx一样,最后转为数组。
path = 'model_trt.engine'
# 1. 建立模型,构建上下文管理器
engine = load_engine(path)
context = engine.create_execution_context()
context.active_optimization_profile = 0
# 3.分配内存空间,并进行数据cpu到gpu的拷贝
# 动态尺寸,每次都要set一下模型输入的shape,0代表的就是输入,输出根据具体的网络结构而定,可以是0,1,2,3...其中的某个头。
context.set_binding_shape(0, image.shape)
d_input = cuda.mem_alloc(image.nbytes) # 分配输入的内存。
output_shape = context.get_binding_shape(1)
buffer = np.empty(output_shape, dtype=np.float32)
d_output = cuda.mem_alloc(buffer.nbytes) # 分配输出内存。
cuda.memcpy_htod(d_input, image)
bindings = [d_input, d_output]
# 4.进行推理,并将结果从gpu拷贝到cpu。
context.execute_v2(bindings) # 可异步和同步
cuda.memcpy_dtoh(buffer, d_output)
output = buffer.reshape(output_shape)
y_pred_binary = np.argmax(output, axis=1)
print(y_pred_binary[0])
输出结果:

静态推理
静态推理和动态推理的代码差不多,唯一不同的是不需要
import time
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import cv2
import time
import torchvision.transforms as transforms
from PIL import Image
def load_engine(engine_path):
# TRT_LOGGER = trt.Logger(trt.Logger.WARNING) # INFO
TRT_LOGGER = trt.Logger(trt.Logger.ERROR)
with open(engine_path, 'rb') as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
path = 'model_trt.engine'
engine = load_engine(path)
context = engine.create_execution_context()
outshape = context.get_binding_shape(1)
# 2. 读取数据,数据处理为可以和网络结构输入对应起来的的shape,数据可增加预处理
def get_test_transform():
return transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
image = Image.open('11.jpg')
image = get_test_transform()(image)
image = image.unsqueeze_(0) # -> NCHW, 1,3,224,224
print("input img mean {} and std {}".format(image.mean(), image.std()))
image = np.array(image)
# image = np.expand_dims(image, axis=1)
image = image.astype(np.float32)
image = image.ravel() # 数据平铺
output = np.empty((outshape), dtype=np.float32)
d_input = cuda.mem_alloc(1 * image.size * image.dtype.itemsize)
d_output = cuda.mem_alloc(1 * output.size * output.dtype.itemsize)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
cuda.memcpy_htod(d_input, image)
context.execute_v2(bindings)
cuda.memcpy_dtoh(output, d_output)
output = output.reshape(outshape)
y_pred_binary = np.argmax(output, axis=1)
print(y_pred_binary[0])
运行结果:


- 点赞
- 收藏
- 关注作者
评论(0)