mobileNetV2解析以及多个版本实现

mobileNetV2是对mobileNetV1的改进,是一种轻量级的神经网络。mobileNetV2保留了V1版本的深度可分离卷积,增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual)。
MobileNetV2的模型如下图所示,其中t为瓶颈层内部升维的倍数,c为特征的维数,n为该瓶颈层重复的次数,s为瓶颈层第一个conv的步幅。
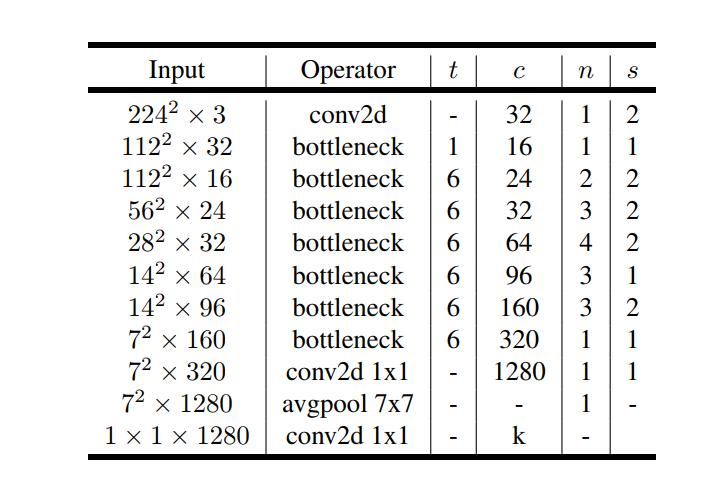
除第一层外,整个网络中使用恒定的扩展率。 在实验中,发现在 5 到 10 之间的扩展率会导致几乎相同的性能曲线,较小的网络在扩展率稍低的情况下效果更好,而较大的网络在扩展率较大的情况下性能稍好。
MobileNetV2主要使用 6 的扩展因子应用于输入张量的大小。 例如,对于采用 64 通道输入张量并产生具有 128 通道的张量的瓶颈层,则中间扩展层为 64×6 = 384 通道。
线性瓶颈
对于mobileNetV1的深度可分离卷积而言, 宽度乘数压缩后的M维空间后会通过一个非线性变换ReLU,根据ReLU的性质,输入特征若为负数,该通道的特征会被清零,本来特征已经经过压缩,这会进一步损失特征信息;若输入特征是正数,经过激活层输出特征是还原始的输入值,则相当于线性变换。
瓶颈层的具体结构如下表所示。输入通过1的conv+ReLU层将维度从k维增加到tk维,之后通过3×3conv+ReLU可分离卷积对图像进行降采样(stride>1时),此时特征维度已经为tk维度,最后通过1*1conv(无ReLU)进行降维,维度从tk降低到k维。

倒残差
残差块已经在ResNet中得到证明,有助于提高精度构建更深的网络,所以mobileNetV2也引入了类似的块。经典的残差块(residual block)的过程是:1x1(降维)–>3x3(卷积)–>1x1(升维), 但深度卷积层(Depthwise convolution layer)提取特征限制于输入特征维度,若采用残差块,先经过1x1的逐点卷积(Pointwise convolution)操作先将输入特征图压缩,再经过深度卷积后,提取的特征会更少。所以mobileNetV2是先经过1x1的逐点卷积操作将特征图的通道进行扩张,丰富特征数量,进而提高精度。这一过程刚好和残差块的顺序颠倒,这也就是倒残差的由来:1x1(升维)–>3x3(dw conv+relu)–>1x1(降维+线性变换)。
结合上面对线性瓶颈和倒残差的理解,我绘制了Block的结构图。如下图:
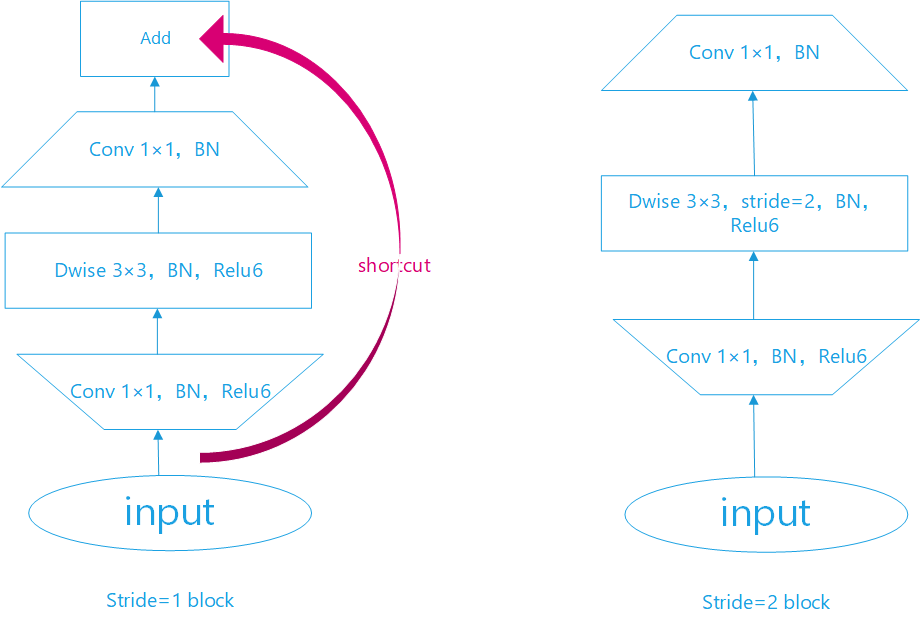
Block的代码实现:
pytorch版本
def Conv3x3BNReLU(in_channels,out_channels,stride,groups):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride, padding=1, groups=groups),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
def Conv1x1BNReLU(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expansion_factor=6):
super(InvertedResidual, self).__init__()
self.stride = stride
mid_channels = (in_channels * expansion_factor)
self.bottleneck = nn.Sequential(
Conv1x1BNReLU(in_channels, mid_channels),
Conv3x3BNReLU(mid_channels, mid_channels, stride,groups=mid_channels),
Conv1x1BN(mid_channels, out_channels)
)
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
out = self.bottleneck(x)
out = (out+self.shortcut(x)) if self.stride==1 else out
return out
keras版本
def relu6(x):
return K.relu(x, max_value=6)
# 保证特征层数为8的倍数
def make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v+divisor/2)//divisor*divisor) #//向下取整,除
if new_v<0.9*v:
new_v +=divisor
return new_v
def pad_size(inputs, kernel_size):
input_size = inputs.shape[1:3]
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if input_size[0] is None:
adjust = (1,1)
else:
adjust = (1- input_size[0]%2, 1-input_size[1]%2)
correct = (kernel_size[0]//2, kernel_size[1]//2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
def conv_block (x, nb_filter, kernel=(1,1), stride=(1,1), name=None):
x = Conv2D(nb_filter, kernel, strides=stride, padding='same', use_bias=False, name=name+'_expand')(x)
x = BatchNormalization(axis=3, name=name+'_expand_BN')(x)
x = Activation(relu6, name=name+'_expand_relu')(x)
return x
def depthwise_res_block(x, nb_filter, kernel, stride, t, alpha, resdiual=False, name=None):
input_tensor=x
exp_channels= x.shape[-1]*t #扩展维度
alpha_channels = int(nb_filter*alpha) #压缩维度
x = conv_block(x, exp_channels, (1,1), (1,1), name=name)
if stride[0]==2:
x = ZeroPadding2D(padding=pad_size(x, 3), name=name+'_pad')(x)
x = DepthwiseConv2D(kernel, padding='same' if stride[0]==1 else 'valid', strides=stride, depth_multiplier=1, use_bias=False, name=name+'_depthwise')(x)
x = BatchNormalization(axis=3, name=name+'_depthwise_BN')(x)
x = Activation(relu6, name=name+'_depthwise_relu')(x)
x = Conv2D(alpha_channels, (1,1), padding='same', use_bias=False, strides=(1,1), name=name+'_project')(x)
x = BatchNormalization(axis=3, name=name+'_project_BN')(x)
if resdiual:
x = layers.add([x, input_tensor], name=name+'_add')
return x

- 点赞
- 收藏
- 关注作者
评论(0)