百度AI进阶实战营第九期:机械手抓取

Day 0
第一步:创建Notebook模型任务
**step1:**进入BML主页,点击立即使用
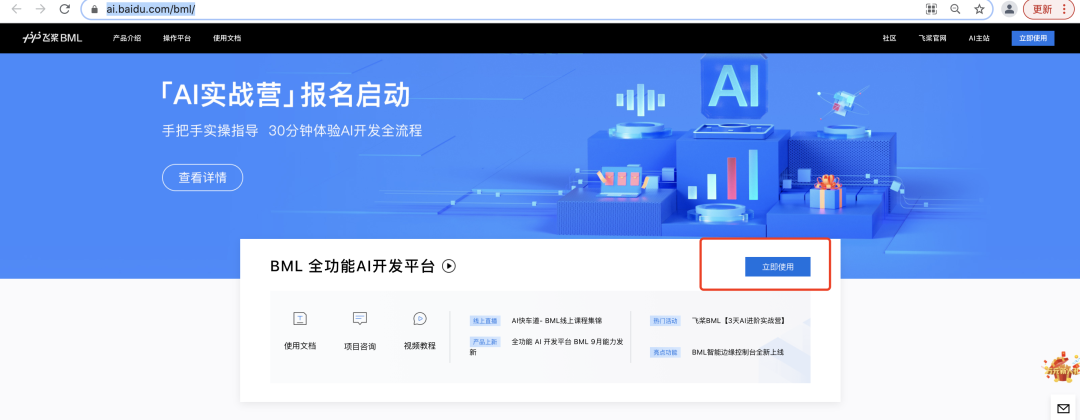
**step2:**点击Notebook,创建“通用任务”
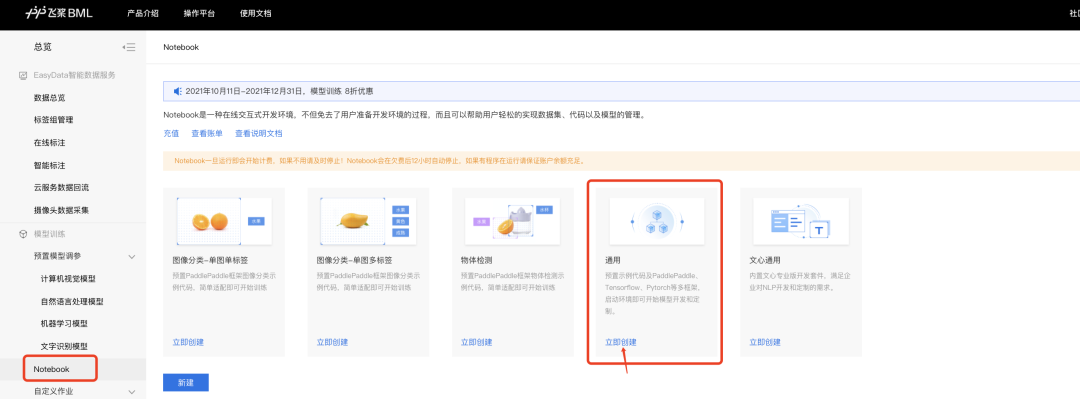
**step3:**填写任务信息
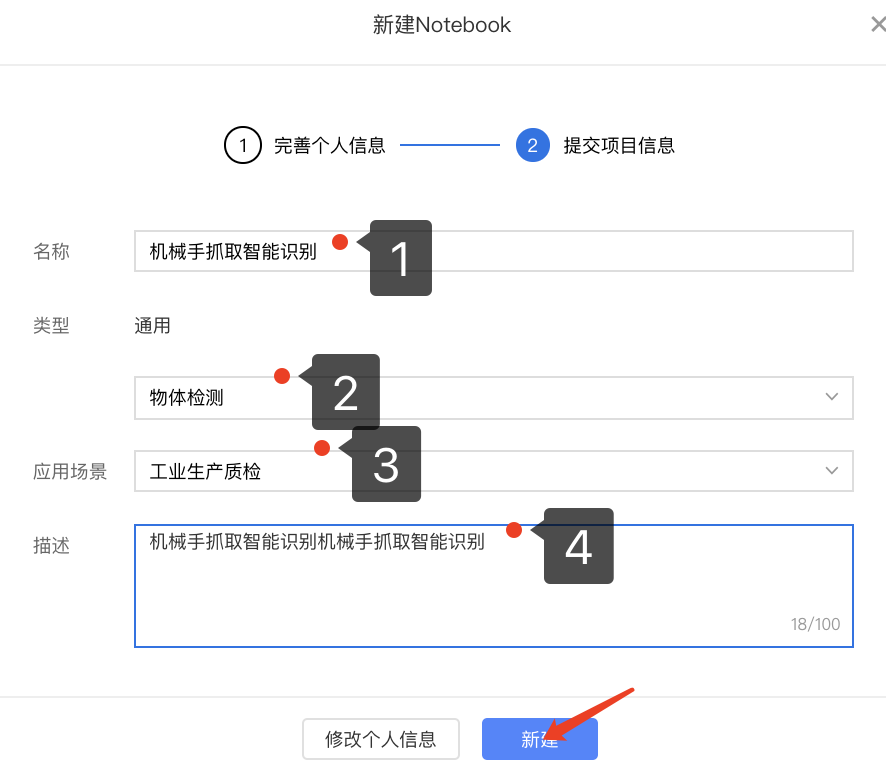
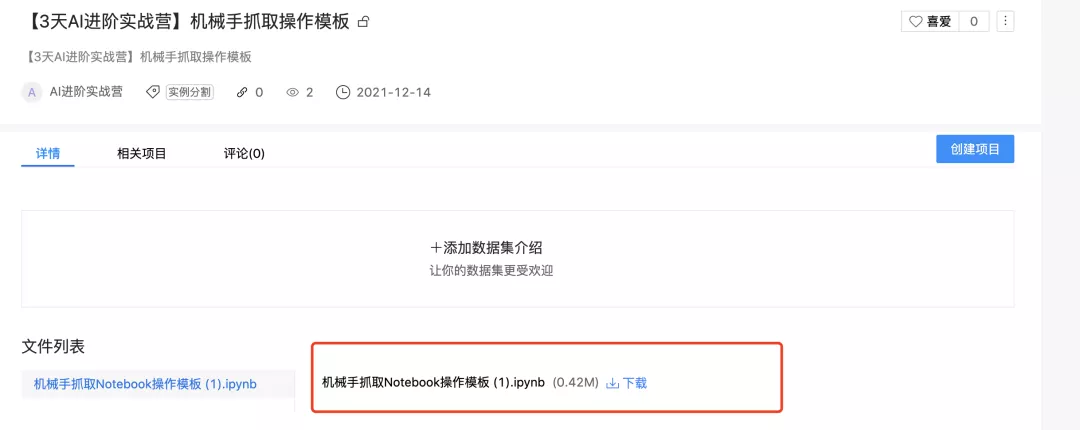
第二步:下载任务操作模板
下载链接:https://aistudio.baidu.com/aistudio/datasetdetail/121560
Day 1
第一步:配置Notebook
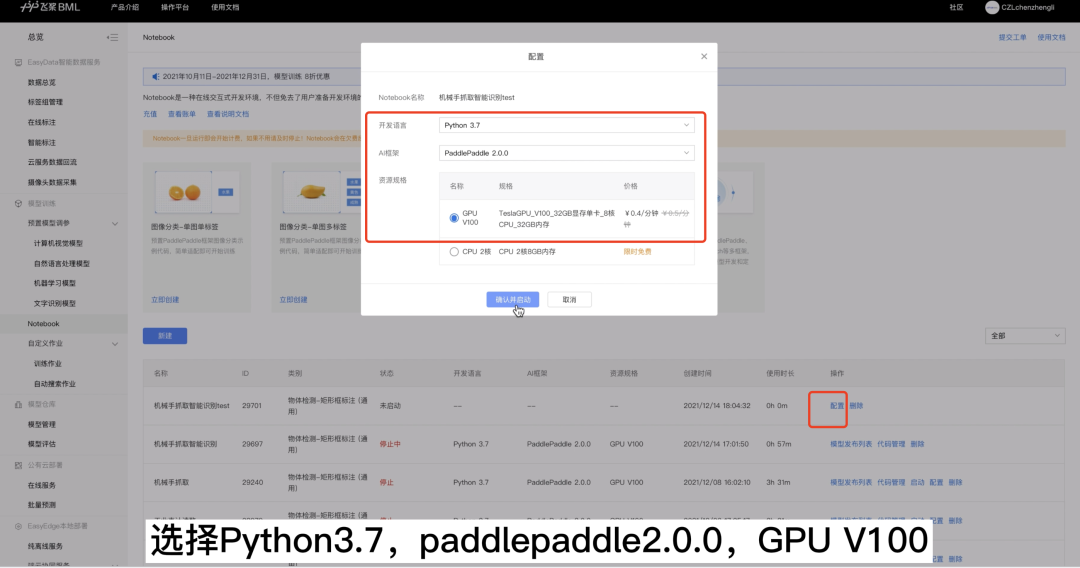
1.找到昨天创建的Notebook任务,点击配置
- 开发语言:Python3.7
- AI框架:PaddlePaddle2.0.0
- 资源规格:GPU V100
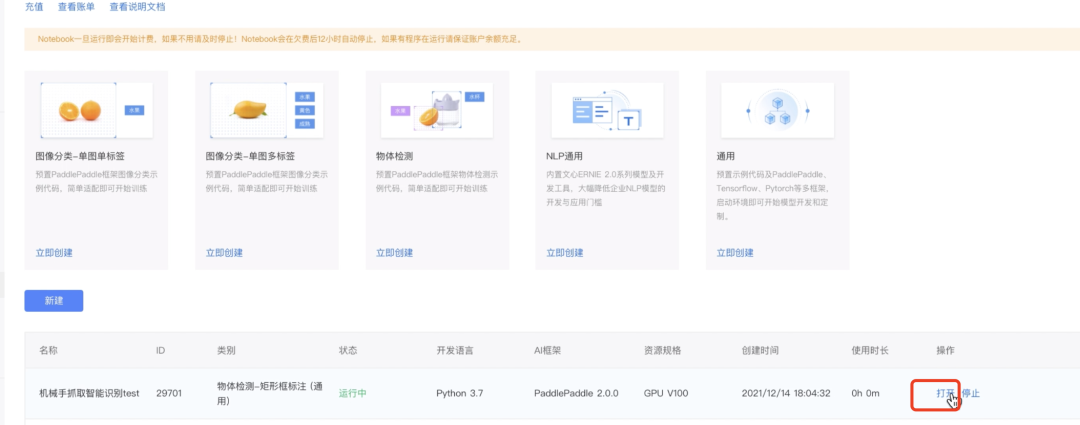
2.打开Notebook
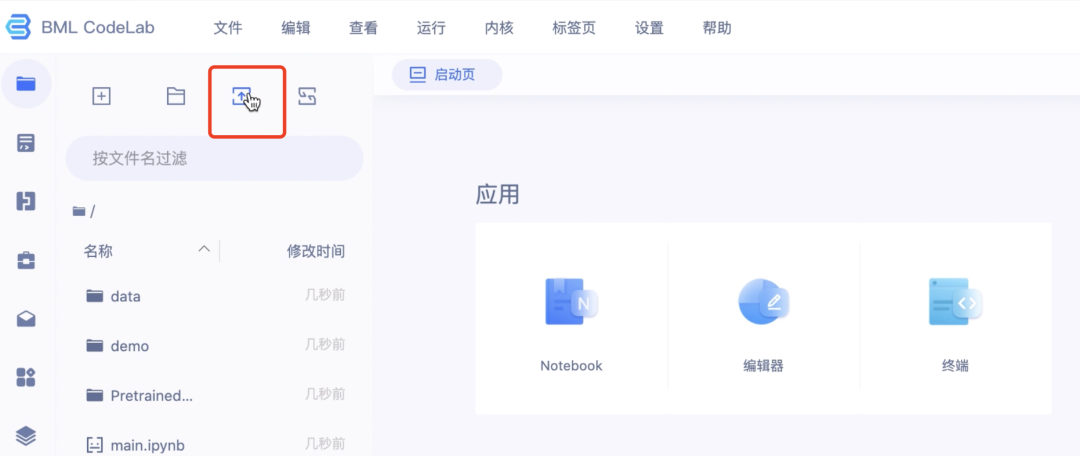
3.上传本次Notebook操作模型
若没来得及下载,请点击链接下载:https://aistudio.baidu.com/aistudio/datasetdetail/121560
第二步:环境准备
1.安装paddlex
!pip install paddlex #安装paddlex

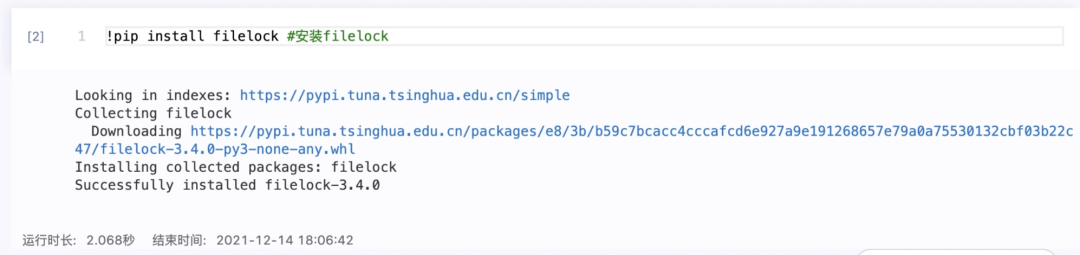
2.安装filelock
!pip install filelock #安装filelock
3.将paddlepaddle升级至2.2.1版本
!pip install paddlepaddle-gpu==2.2.1.post101 -f https://www.paddlepaddle.org.cn/whl/linux/mkl/avx/stable.html #升级paadlepaddle-gpu


第三步:数据准备
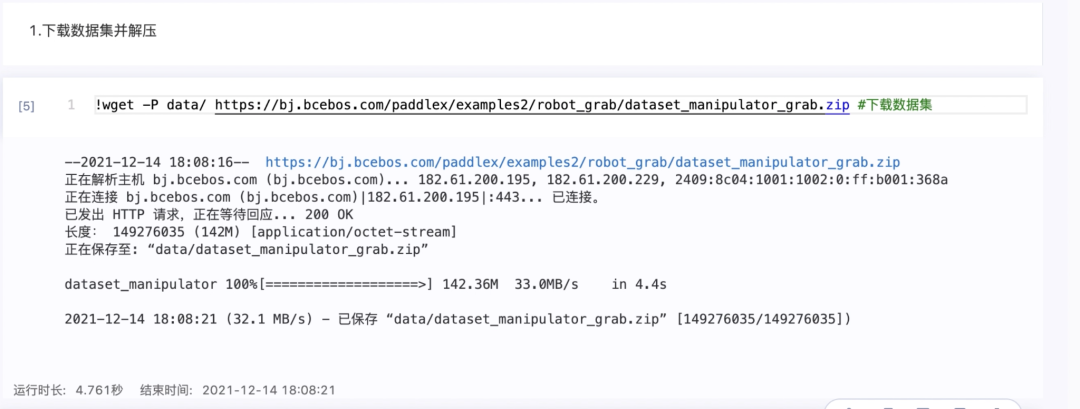
1.下载数据集
!wget -P data/ https://bj.bcebos.com/paddlex/examples2/robot_grab/dataset_manipulator_grab.zip #下载数据集
2.解压数据集
!cd 'data' && unzip -q dataset_manipulator_grab.zip #在data文件夹中解压数据集

3.将数据集转换为MSCOCO格式
!paddlex --data_conversion --source labelme --to MSCOCO --pics data/dataset_manipulator_grab/JPEGImages --annotations data/dataset_manipulator_grab/Annotations --save_dir dataset

4.使用paddlex进行数据切分
将训练集、验证集和测试集按照7:2:1的比例划分
!paddlex --split_dataset --format COCO --dataset_dir dataset --val_value 0.2 --test_value 0.1

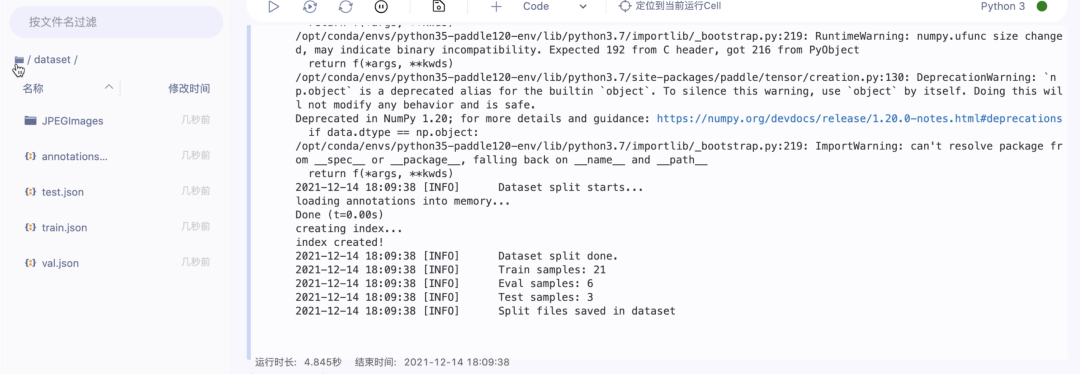
数据文件夹切分前后的状态如下:
dataset/ dataset/
├── JPEGImages/ --> ├── JPEGImages/
├── annotations.json ├── annotations.json
├── test.json
├── train.json
├── val.json
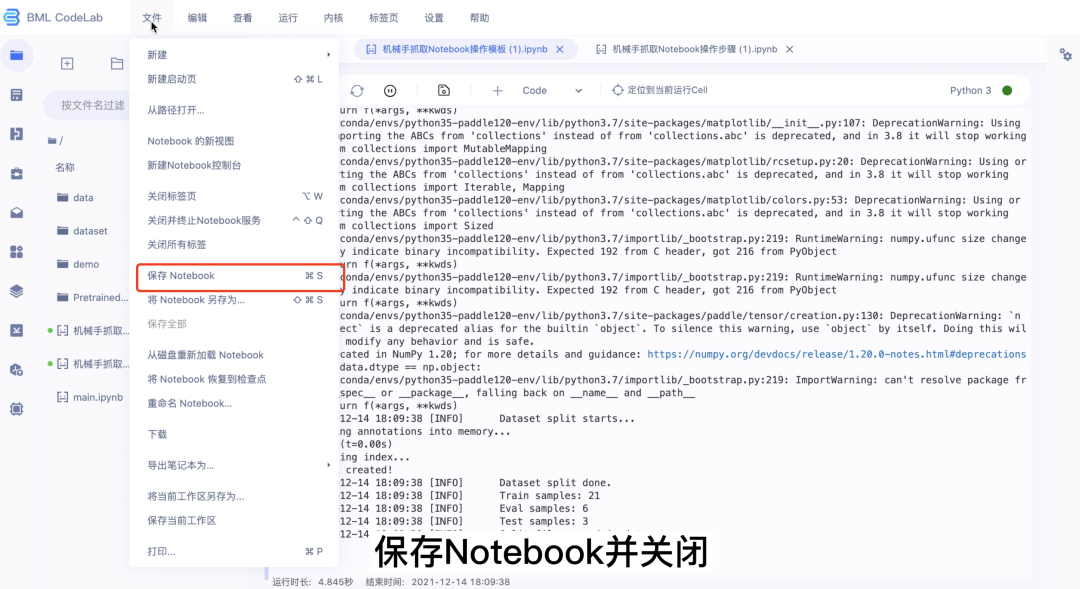
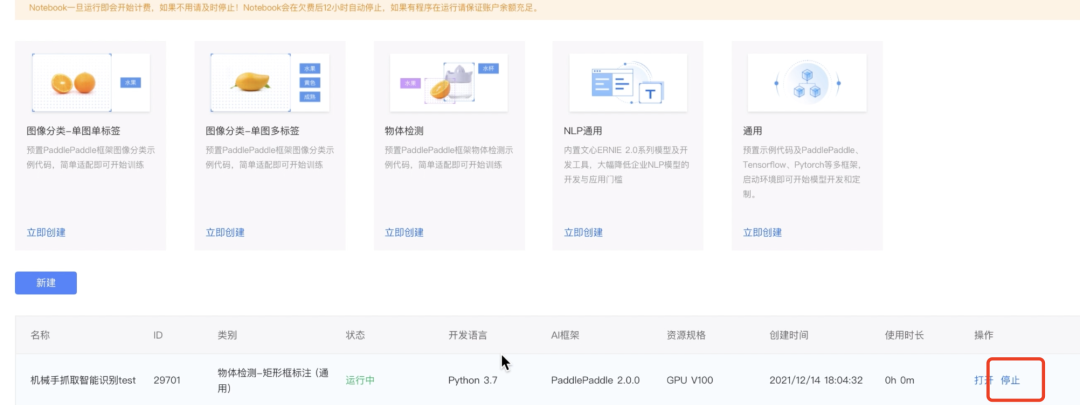
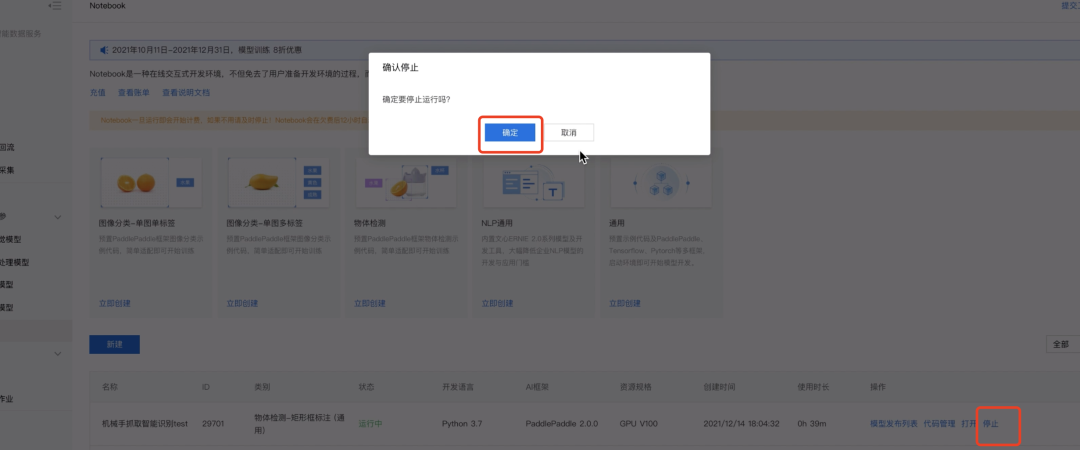
第四步:保存Notebook并关闭、停止运行
Day 2
第一步:重新安装环境
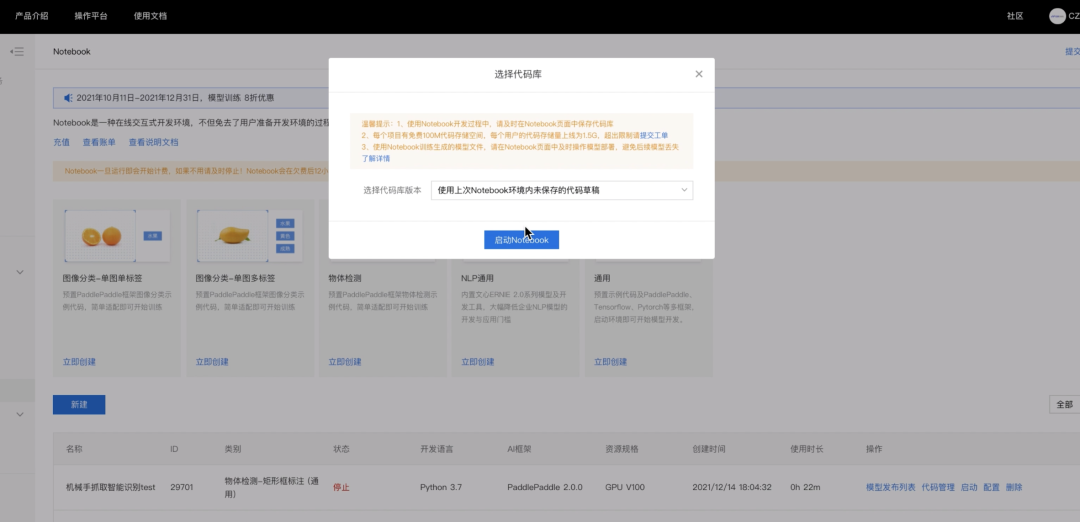
1.启动Notebook并打开
2.重新执行三条安装命令
第二步:模型训练
1.调用paddlex
import paddlex as pdxfrom paddlex import transforms as T

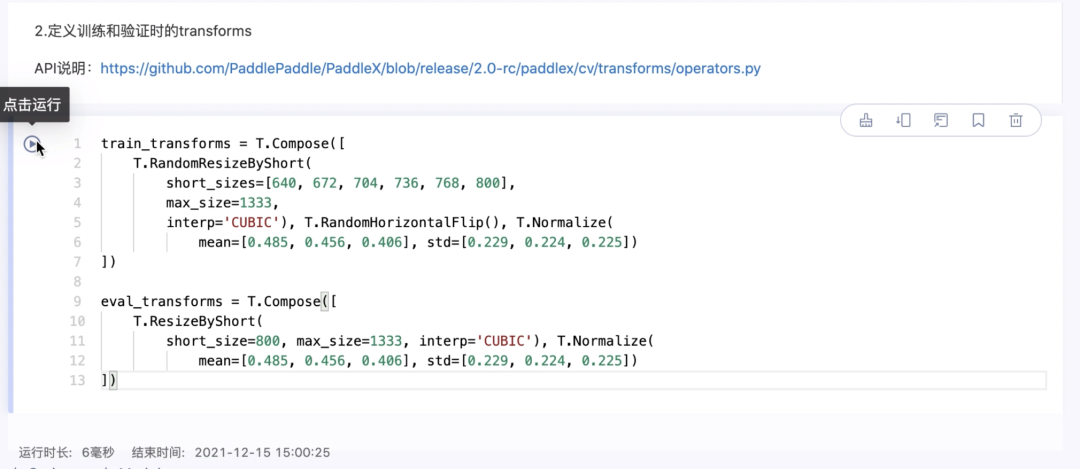
2.定义训练和验证时的transforms
API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/transforms/operators.py
train_transforms = T.Compose([ T.RandomResizeByShort( short_sizes=[640, 672, 704, 736, 768, 800], max_size=1333, interp='CUBIC'), T.RandomHorizontalFlip(), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
eval_transforms = T.Compose([ T.ResizeByShort( short_size=800, max_size=1333, interp='CUBIC'), T.Normalize( mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
3.定义训练和验证所用的数据集
API:https://github.com/PaddlePaddle/PaddleX/blob/develop/paddlex/cv/datasets/coco.py#L26
train_dataset = pdx.datasets.CocoDetection( data_dir='dataset/JPEGImages', ann_file='dataset/train.json', transforms=train_transforms, shuffle=True)eval_dataset = pdx.datasets.CocoDetection( data_dir='dataset/JPEGImages', ann_file='dataset/val.json', transforms=eval_transforms)
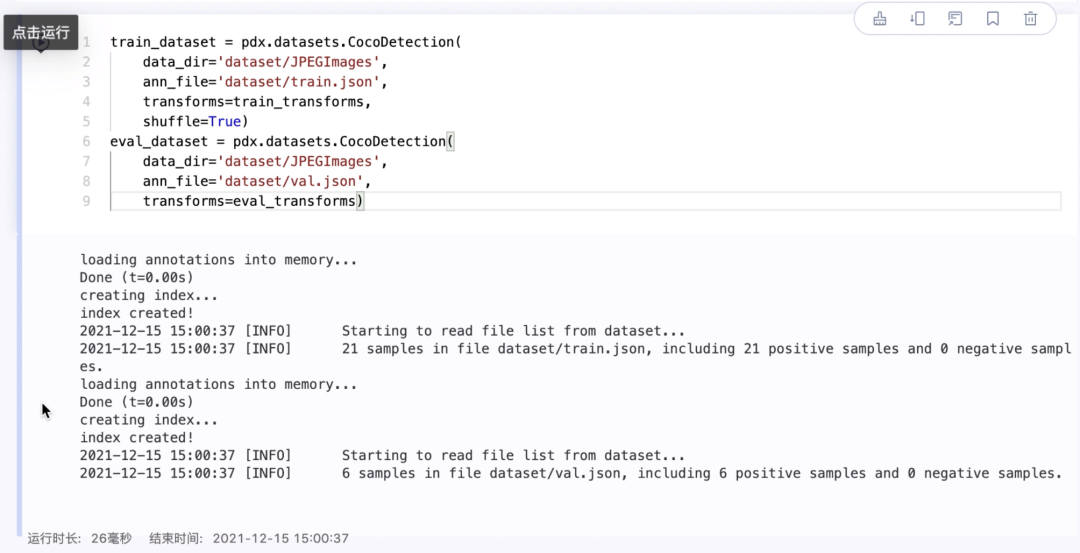
4.初始化模型
可使用VisualDL查看训练指标,参考https://github.com/PaddlePaddle/PaddleX/tree/release/2.0-rc/tutorials/train#visualdl可视化训练指标
num_classes = len(train_dataset.labels)model = pdx.det.MaskRCNN( num_classes=num_classes, backbone='ResNet50', with_fpn=True)

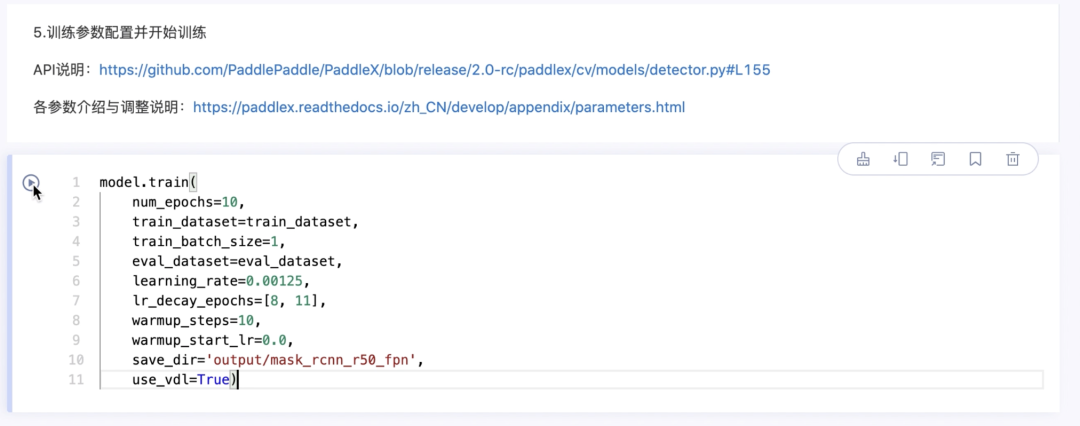
5.训练参数配置,并开始训练
API说明:https://github.com/PaddlePaddle/PaddleX/blob/release/2.0-rc/paddlex/cv/models/detector.py#L155
各参数介绍与调整说明:https://paddlex.readthedocs.io/zh_CN/develop/appendix/parameters.html
model.train( num_epochs=10, train_dataset=train_dataset, train_batch_size=1, eval_dataset=eval_dataset, learning_rate=0.00125, lr_decay_epochs=[8, 11], warmup_steps=10, warmup_start_lr=0.0, save_dir='output/mask_rcnn_r50_fpn', use_vdl=True)

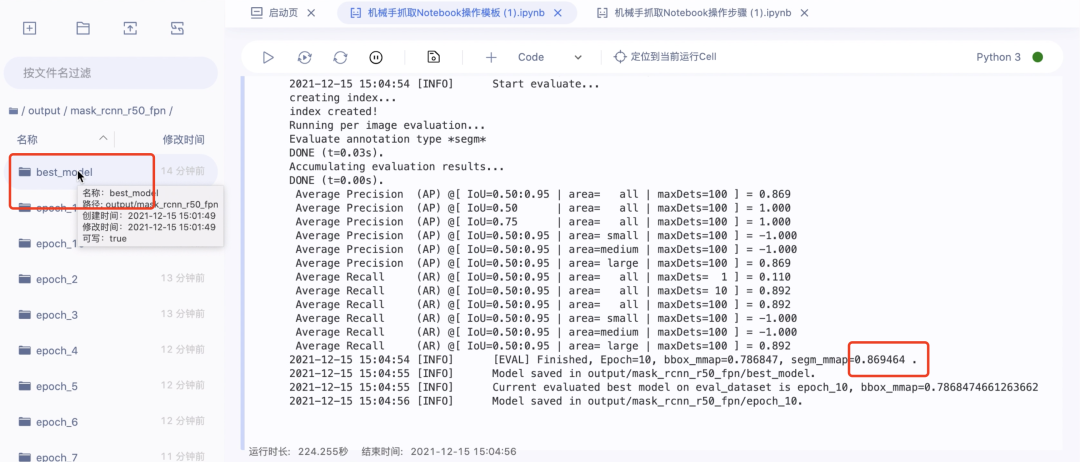
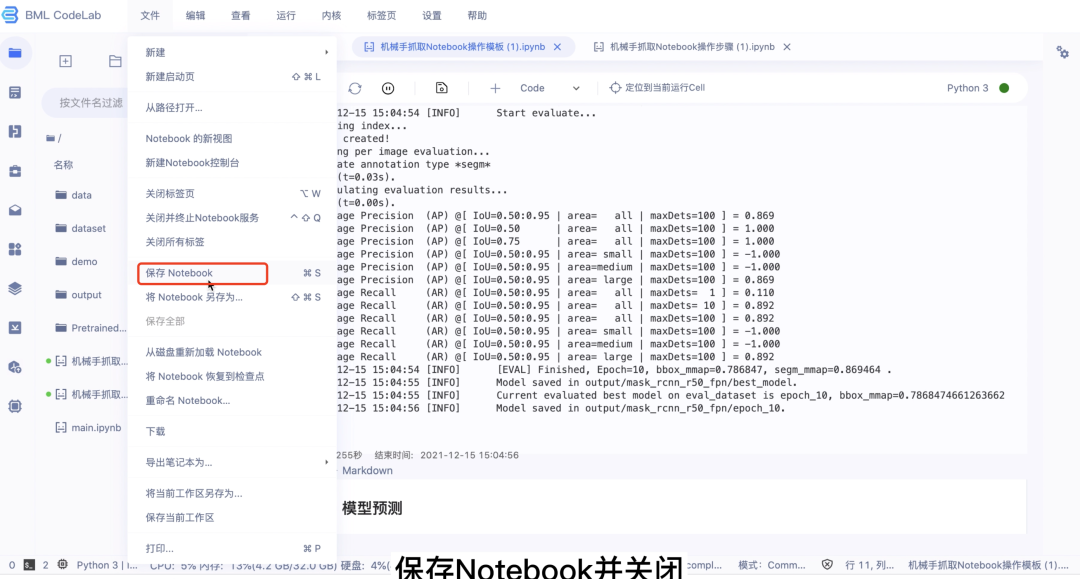
第三步:保存Notebook并关闭、停止运行
Day 3
第一步:重新安装环境
1.启动Notebook并打开
2.重新执行三条安装命令

第二步:重新安装环境
import glob
import numpy as np
import threading
import time
import random
import os
import base64
import cv2
import json
import paddlex as pdx
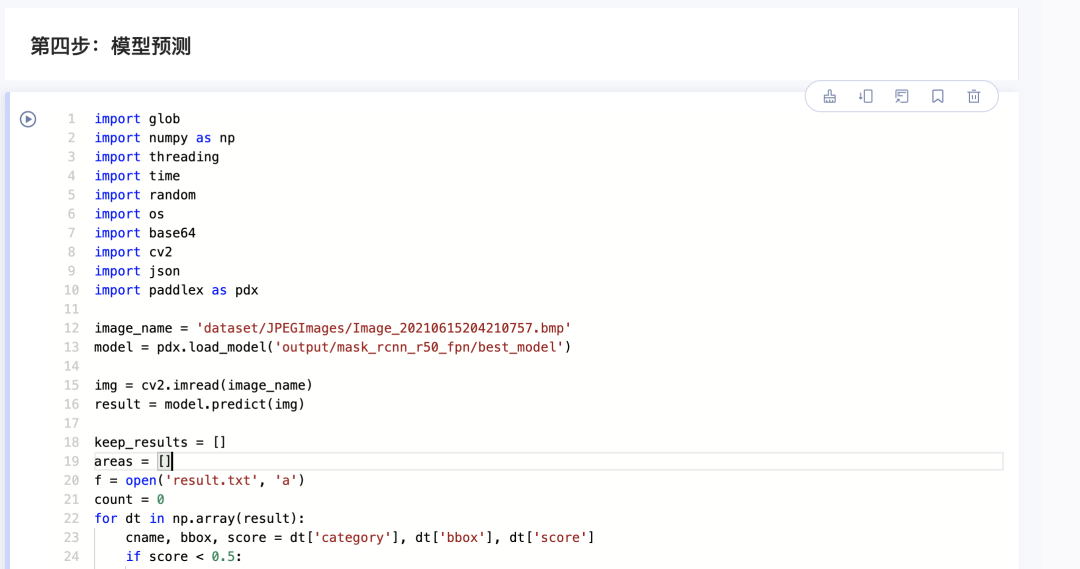
image_name = 'dataset/JPEGImages/Image_20210615204210757.bmp'
model = pdx.load_model('output/mask_rcnn_r50_fpn/best_model')
img = cv2.imread(image_name)
result = model.predict(img)
keep_results = []
areas = []
f = open('result.txt', 'a')
count = 0
for dt in np.array(result):
cname, bbox, score = dt['category'], dt['bbox'], dt['score']
if score < 0.5:
continue
keep_results.append(dt)
count += 1
f.write(str(dt) + '\n')
f.write('\n')
areas.append(bbox[2] * bbox[3])
areas = np.asarray(areas)
sorted_idxs = np.argsort(-areas).tolist()
keep_results = [keep_results[k]
for k in sorted_idxs] if len(keep_results) > 0 else []
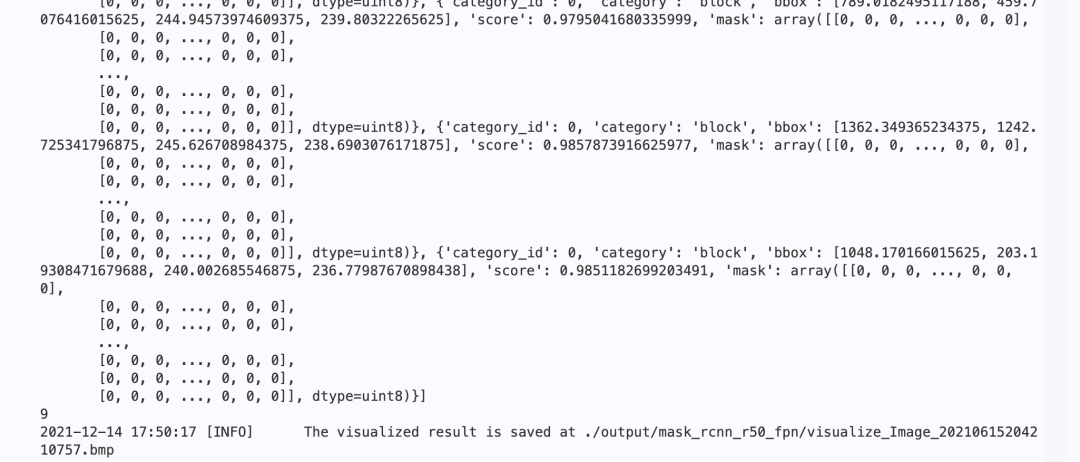
print(keep_results)
print(count)
f.write("the total number is :" + str(int(count)))
f.close()
pdx.det.visualize(
image_name, result, threshold=0.5, save_dir='./output/mask_rcnn_r50_fpn')

第三步:保存Notebook并关闭、停止运行
完整的代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/67332976

- 点赞
- 收藏
- 关注作者
评论(0)