NEON 常用函数及其执行结果

【摘要】
令初始数据为:
float d0[4] = {0.f, 1.f, 2.f, 3.f};float d1[4] = {4.f, 5.f, 6.f, 7.f};float d2[4] = {8.f, 9.f, 10.f, 11.f};float d3[4] = {12.f, 13.f, 14.f, 15.f};
一、基本的加...
令初始数据为:
-
float d0[4] = {0.f, 1.f, 2.f, 3.f};
-
float d1[4] = {4.f, 5.f, 6.f, 7.f};
-
float d2[4] = {8.f, 9.f, 10.f, 11.f};
-
float d3[4] = {12.f, 13.f, 14.f, 15.f};
一、基本的加载存储操作
1. vld1q_f32
float32x4_t q0 = vld1q_f32(d0); // 加载 d0 地址起始的 4 个 float 数据到 q0

2.vst1q_f32
vst1q_f32(d1, q0);// 将 q0 中 4 个 float32,赋值给以 d1 为起始地址的 4 个 float32


3.vld2q_f32
-
float d4[8]= {1.f, 2.f, 3.f, 4.f, 5.f, 6.f, 7.f, 8.f};
-
float32x4x2_t ret = vld2q_f32 (d4);

注意,此时在寄存器是交错读取的!
4.vst2q_f32
vst2q_f32 (d4, ret);

注意,由于寄存器是交错存储的,所以内存保持不变!
5.vld3q_f32
-
float d5[12] = {1.f, 2.f, 3.f, 4.f,
-
5.f, 6.f, 7.f, 8.f,
-
9.f, 10.f, 11.f, 12.f};
-
float32x4x3_t f = vld3q_f32 (d5);

6.vst3q_f32
vst3q_f32 (d5, f);

7.vld4q_f32, vst4q_f32
略
二、特殊操作
1.vdupq_n_f32
float32x4_t res = vdupq_n_f32(0.f); // 存储的四个 float32 都初始化为 0

2.vzipq_f32
float32x4x2_t q4 = vzipq_f32 (q0, q1);

3.vuzpq_f32
float32x4x2_t ret = vuzpq_f32 (q0, q1);

可见,打包 (zip)、拆包(unzip)并不是想当然的可逆的运算
4.vcombine_f32
-
float32x2_t a = vget_low_f32(q0);
-
float32x2_t b = vget_high_f32(q0);
-
-
float32x4_t ret = vcombine_f32 (a, b);

5. vget_low_f32
float32x2_t low = vget_low_f32(q0); // 取低2位

6. vget_high_f32
float32x2_t high = vget_high_f32(q0); // 取高2位

7. vtrnq_f32
float32x4x2_t ret = vtrnq_f32 (q0, q1)


8. vextq_f32
-
// 拼接两个寄存器并返回从第 n 位开始的大小为4的寄存器 0<=n<=3
-
res = vextq_f32(q0, q1, 2); //取 q1 低2位,拼接到 q0 的高位,保留 q0 的高2位(移到低位)
-
// q0, q1 实际数据没有变化
![]()

- vext_u8 的例子:
uint8x8_t ret = vext_u8 (p, q, 2); // 取 q 的低两位作为 p 的高位,p 向左移动两位腾出空间

9.vget_lane_f32
float lane0 = vget_lane_f32(ss0, 0);// get 0th parameter in vector
![]()

10. vsetq_lane_f32
float32x4_t res = vsetq_lane_f32(d1[0], q1, 1);//用 d1[0] 的数据替换掉 q1[1](q1 实际数据没有变化)


11.vtbl1_s8
int8x8_t r = vtbl1_s8 (p, q);

12.vrev16_s8
int8x8_t s = vrev16_s8 (q);


三、基本数据类型的转换
1.vcvtq_u32_f32
uint32x4_t ui0 = vcvtq_u32_f32 (q0);

2.vcvtq_s32_f32
int32x4_t i0 = vcvtq_s32_f32 (q1);

3. vcvtq_f32_s32
float32x4_t f0 = vcvtq_f32_s32 (i0);

4.vcvtq_f32_u32
float32x4_t uf0 = vcvtq_f32_u32 (ui0)

四、基本比较运算
1.vceq_f32
uint32x2_t c = vceq_f32 (a, b); // 等于

2.vceqq_f32
uint32x4_t q = vceqq_f32 (q1, q2); // 等于


3. vmaxq_f32
float32x4_t ret = vmaxq_f32 (q2, q1);

![]()
4. vminq_f32
float32x4_t ret0 = vminq_f32 (q2, q1);

![]()
5.vpmax_s8
int8x8_t r = vpmax_s8 (p, q);


6.vpmin_s8
int8x8_t s = vpmin_s8 (p, q);


五、基本的位运算
1.vclsq_s32
int32x4_t q1 = vclsq_s32 (q0); // 统计和符号位相同的 bit 数(不包括符号位)


2.vclzq_s32
int32x4_t q2 = vclzq_s32 (q0); // 统计前缀 0 的个数


3.vcnt_s8
-
int8_t d0[8] = {0, 1, 2, 3, 4, 5, 6, 7};
-
int8x8_t q = vld1_s8(d0);
-
int8x8_t p = vcnt_s8 (q); // 二进制形式的 1 的个数

4.vmvn_s8
int8x8_t q = vmvn_s8 (p); // 按位取反

5.vqneg_s8
int8x8_t r = vqneg_s8 (p);

![]()
6. vqshl_s8
-
int8_t d0[8] = {0, 1, 2, 3, 4, 5, 6, 7};
-
int8_t d1[8] = {1, 1, 2, 2, 3, 3, 4, 4};
-
-
int8x8_t p = vld1_s8(d0);
-
int8x8_t q = vld1_s8(d1);
-
-
int8x8_t pq = vqshl_s8 (p, q); // 左移对应的位数
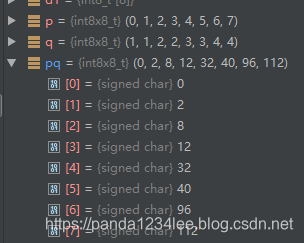
如果移位是负数 ,则变成截断的右移
-
int8_t d0[8] = {0, 1, 2, 3, 4, 5, 6, 7};
-
int8_t d1[8] = {-1, -1, -2, -2, -3, -3, -4, -4};
-
-
int8x8_t p = vld1_s8(d0);
-
int8x8_t q = vld1_s8(d1);
-
-
int8x8_t pq = vqshl_s8 (p, q);

六、基本的逻辑运算
略
七、基本的算术运算
1.vadd_f32
float32x2_t ss0 = vadd_f32(vget_low_f32(q2), vget_high_f32(q2));//对应元素相加
2.vaddq_f32
float32x4_t q4 = vaddq_f32 (q1, q2);


3.vpadd_f32
float32x2_t ss1 = vpadd_f32(vget_low_f32(q2), vget_high_f32(q2));//相邻元素相加

3.vmulq_f32
float32x4_t res0 = vmulq_f32(q0, q1); //点乘

![]()
4. vmlaq_f32
float32x4_t res1 = vmlaq_f32(q0, q1, q2);// q0 + q1*q2


5.vmlaq_lane_f32
-
// ri = ai + bi * c[d];
-
float32x4_t res = vmlaq_lane_f32(q0, q1, vget_low_f32(q2), 0);//取 q2 的第0个数,分别与 q1 中的 4 个数相乘,得到 4 个结果与 q0 累加


6.vmaxq_f3
float32x4_t max = vmaxq_f32(q1, q2);//对应元素比较,取最大

7.vrecpeq_f32
float32x4_t q5 = vrecpeq_f32 (q1); // 倒数

8.vrsqrteq_f32
float32x4_t q6 = vrsqrteq_f32 (q1); // 倒数平方根
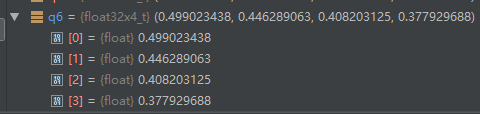
待续
文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/88784953
【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)