客快物流大数据项目(四十):ETL实现方案

【摘要】
目录
ETL实现方案
一、ETL处理流程图
二、为什么使用Kudu作为存储介质
ETL实现方案
一、ETL处理流程图
数据来源:
来自于ogg同步到kafka的物流运输数据来自于canal同步到kafka的客户关系数据
二、为什么使用Kudu作为存储介质
数据库数据上的快速分析
目前很多业务使用事...
目录
ETL实现方案
一、ETL处理流程图
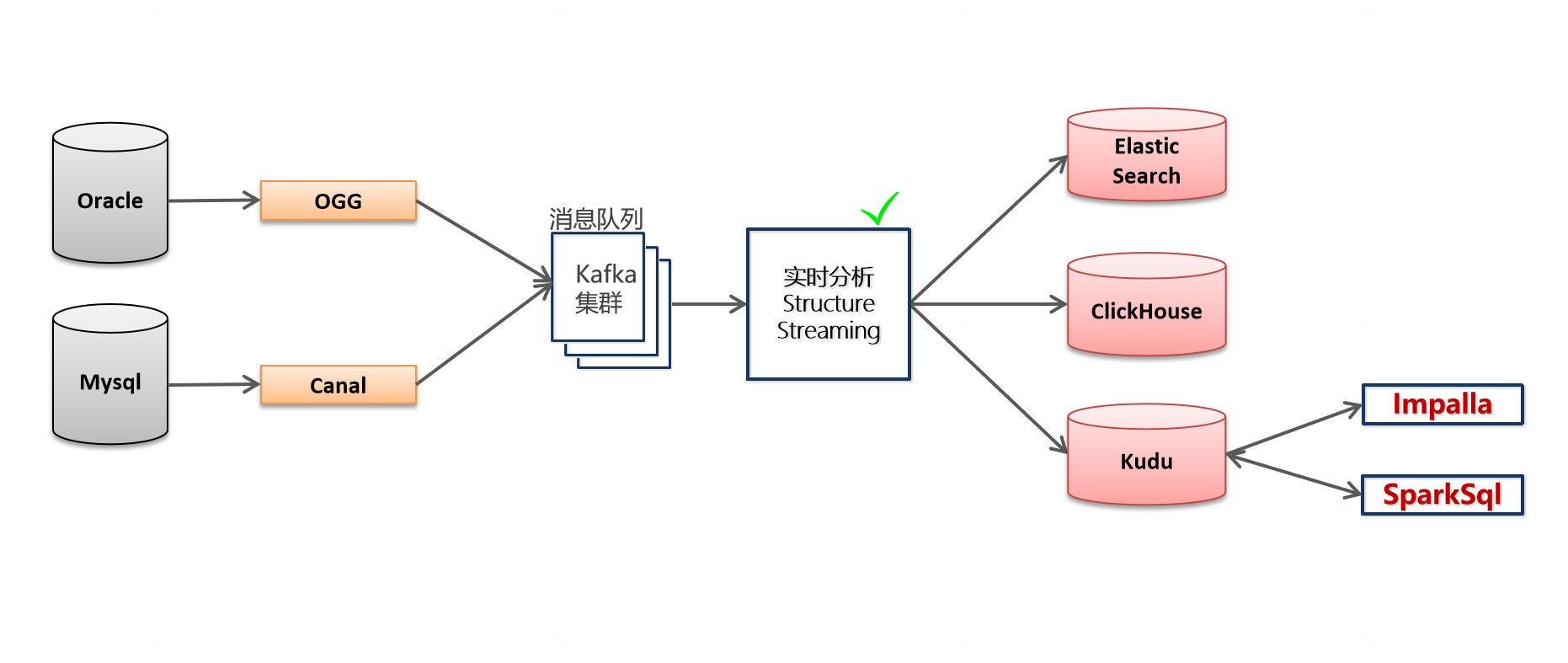
数据来源:
- 来自于ogg同步到kafka的物流运输数据
- 来自于canal同步到kafka的客户关系数据
二、为什么使用Kudu作为存储介质
- 数据库数据上的快速分析
目前很多业务使用事务型数据库(MySQL、Oracle)做数据分析,把数据写入数据库,然后使用 SQL 进行有效信息提取,当数据规模很小的时候,这种方式确实是立竿见影的,但是当数据量级起来以后,会发现数据库吃不消了或者成本开销太大了,此时就需要把数据从事务型数据库里拷贝出来或者说剥离出来,装入一个分析型的数据库里。发现对于实时性和变更性的需求,目前只有 Kudu 一种组件能够满足需求,所以就产生了这样的一种场景:
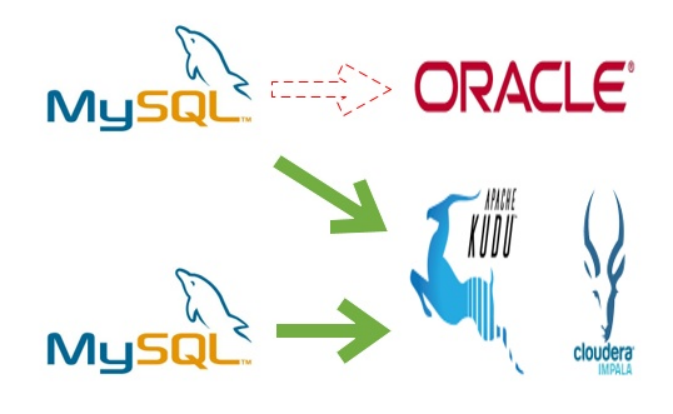
MySQL 数据库增、删、改的数据通过 Binlog 实时的被同步到 Kudu 里,同时在 Impala(或者其他计算引擎如 Spark、Hive、Presto、MapReduce)上可以实时的看到。
这种场景也是目前业界使用最广泛的,认可度最高。
- 用户行为日志的快速分析
对于用户行为日志的实时性敏感的业务,比如电商流量、AB 测试、优惠券的点击反馈、广告投放效果以及秒级导入秒级查询等需求,按 Kudu 出现以前的架构基本上都是这张图的模式:
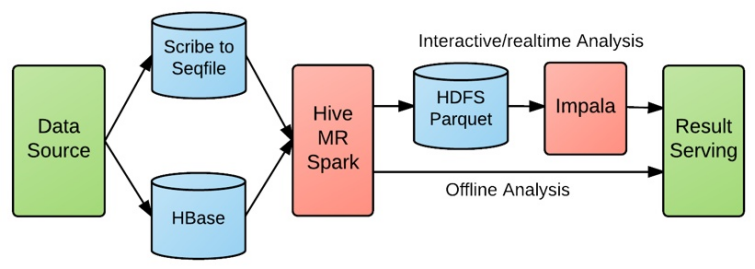
不仅链路长而且实时性得不到有力保障,有些甚至是 T + 1 的,极大的削弱了业务的丰富度。
引入 Kudu 以后,大家看,数据的导入和查询都是在线实时的:
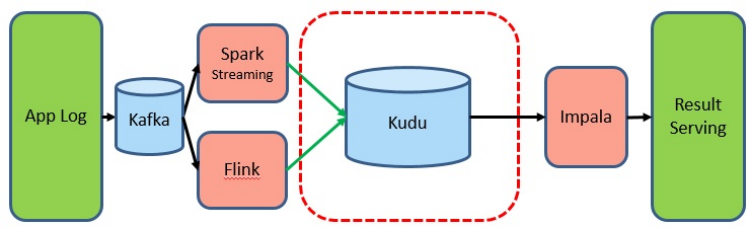
这种场景目前也是网易考拉和hub在使用的,其中hub甚至把 Kudu 当 HBase 来作点查使用。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/122906365

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)