客快物流大数据项目(三十八):安装Azkaban-3.71.0

目录
安装Azkaban-3.71.0
一、下载Azkaban源码并编译
| 操作步骤 |
说明 |
| 1 |
下载Azkaban-3.71.0 |
| cd /export/softwares/ |
|
| curl -L -O https://github.com/azkaban/azkaban/archive/3.71.0.tar.gz |
|
| 2 |
解压 |
| tar -zxf azkaban-3.71.0.tar.gz -C /export/services/ |
|
| 3 |
创建软连接 |
| ln -s /export/services/azkaban-3.71.0 /export/services/azkaban |
|
| 4 |
安装Git |
| yum install -y git |
|
| 5 |
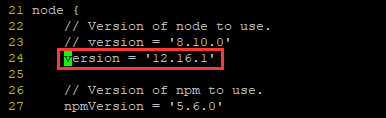
修改Azkaban依赖的node版本 |
| Azkaban默认使用NodeJs-8.10.0版本,但是前面已经安装过最新的NodeJs-12.16.1版本,所以直接使用即可 |
|
| vim /export/services/azkaban/azkaban-web-server/build.gradle |
|
| |
|
| 6 |
编译 |
| cd /export/services/azkaban |
|
| ## 跳过测试 |
|
| ./gradlew build installDist -x test |
|
| |
|
| 7 |
查看编译后的二进制软件包 |
| ll azkaban-solo-server/build/distributions/ |
|
| |

二、安装Azkaban
| 操作步骤 |
说明 |
| 1 |
解压缩 |
| tar -zxf /export/services/azkaban/azkaban-solo-server/build/distributions/azkaban-solo-server-0.1.0-SNAPSHOT.tar.gz -C /export/services/ |
|
| ## 重命名 |
|
| mv azkaban-solo-server-0.1.0-SNAPSHOT azkaban-3.71.0-bin |
|
| 2 |
进入/export/services目录 |
| cd /export/services/ |
|
| 3 |
创建软连接 |
| ln -s /export/services/azkaban-3.71.0-bin /export/services/azkaban |
|
| 4 |
添加环境变量 |
| vim /etc/profile |
|
| export AZKABAN_HOME=/export/services/azkaban PATH=$AZKABAN_HOME/bin:$PATH |
|
| source /etc/profile |
|
| 5 |
配置azkaban.properties |
| cd /export/services/azkaban |
|
| vim conf/azkaban.properties |
|
| |
|
| 6 |
配置commonprivate.properties |
| vim plugins/jobtypes/commonprivate.properties |
|
| |
|
| 7 |
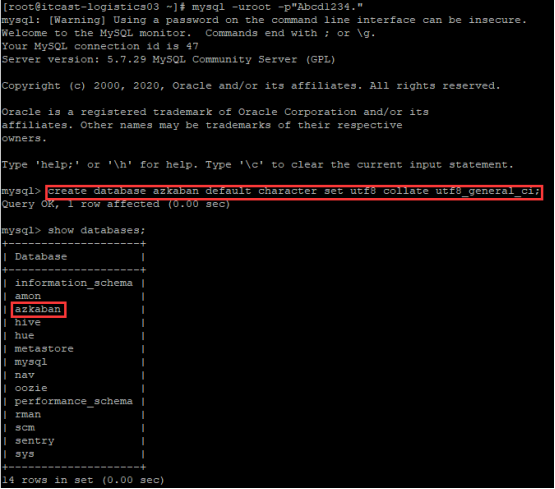
在mysql中添加azkaban数据库 |
| mysql -uroot -pAbcd1234. |
|
| create database azkaban default character set utf8 collate utf8_general_ci; |
|
| quit |
|
| |
|
| 8 |
启动Azkaban |
| cd /export/services/azkaban |
|
| ./bin/start-solo.sh |
|
| 注意:这个start-solo.sh脚本使用的是相对路径,必须进入到/export/services/azkaban路径下执行./bin/start-solo.sh,否则mysql数据库会初始化失败 |
|
| 9 |
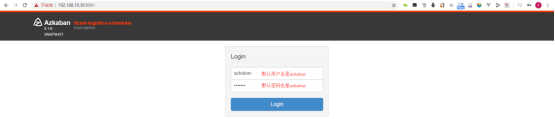
打开Azkaban的WebUI |
| 在浏览器中输入http://node2:8081 账户:azkaban 密码:azkaban |
|
| |
|
| 登录成功后的样子如图: |
|
| |


三、测试Azkaban的job
| 操作步骤 |
说明 |
| 1 |
创建shell类型job的路径 |
| cd /export/services/azkaban |
|
| mkdir -p examples/job-shell-example && cd examples/job-shell-example |
|
| 2 |
创建shell类型的job |
| # action1.job是第一个job,没有依赖 |
|
| vim action1.job |
|
| type=command # 假设是提交的一个spark应用,处理数据后写入到/export/services/文件夹下 command=spark-submit --version # 调度程序中的第一个动作,没有前置的依赖,所以无需配置dependencies # dependencies= |
|
| # action2.job是第二个job,依赖action1 |
|
| vim action2.job |
|
| type=command # 比如执行Hive的加载命令 command=hive --version dependencies=action1 |
|
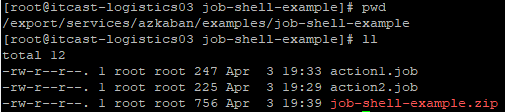
| 3 |
先打包 |
| 如果没有zip工具就先安装:yum install -y zip unzip |
|
| zip -q -r job-shell-example.zip ./ |
|
| |
|
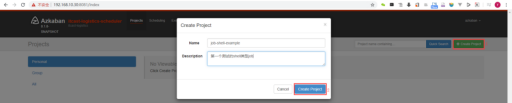
| 4 |
再创建project |
| |
|
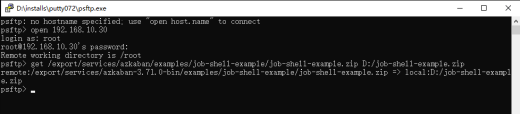
| 5 |
最后上传到project中 |
| Azkaban的WebUI是在Windows宿主机中打开的,在上传zip包时,只能读取浏览器所在操作系统的硬盘,无法浏览VPS中的zip包。所以还需要将打好的job-shell-example.zip文件使用ftp工具下载到Windows宿主机的D盘根目录下,如图: |
|
| |
|
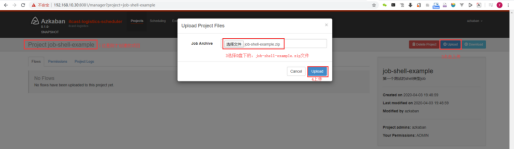
| 这时,在Azkaban的WebUI中,点击浏览按钮,直接选择D盘下的job-shell-example.zip,即可完成上传,如图: |
|
| |
|
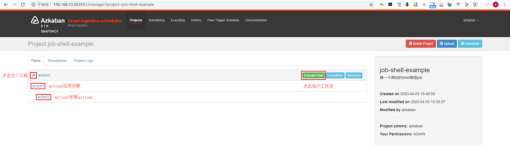
| 上传完成后,页面会以树状结构显示出刚才上传的zip包的每一个job,然后点击Execute Flow按钮即可运行,如图: |
|
| |
|
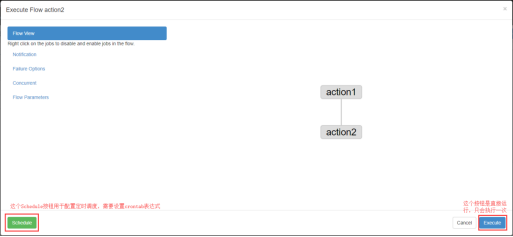
| 左侧绿色的Schedule用来配置定时调度,使用crontab表达式的方式实现。右侧蓝色的Execute按钮是直接运行,但只会运行一次。出于简单测试目的,我们点击Execute即可 |
|
| |
|
| |
|
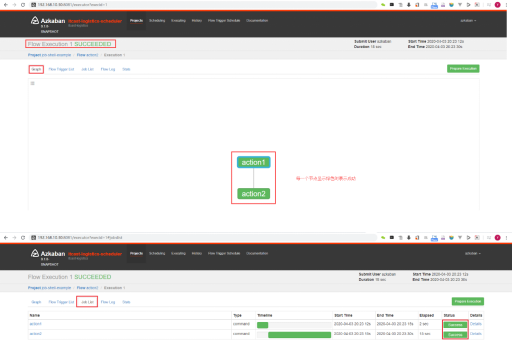
| 当工作流运行完成后,如果所有的节点都是绿色,就表示整个工作流运行成功了。有两种视图的形式,第一种是Graph的形式,第二种是Job List的形式。如下: |
|
| |
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/122837203

- 点赞
- 收藏
- 关注作者
评论(0)