Python中的“旧瓶旧酒”——浅谈深拷贝与浅拷贝

课堂上有一道思考题:
m = [1, 2, [3]]
n = m[:]
n[1] = 4
n[2][0] = 5
print(m)
- 1
- 2
- 3
- 4
- 5
m 的结果是什么?

正确答案是 [1, 2, [5]],这次比上次好点,有 35% 的正确率。
当时我留了个提示,说和浅拷贝、深拷贝有关,现在我们就来具体说一说。
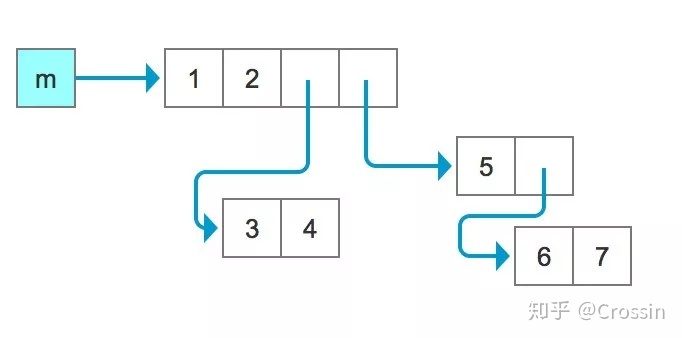
假设有这样一个 list 变量 m,其中有 4 个元素(别被嵌套迷惑了):
m = [1, 2, [3, 4], [5, [6, 7]]]
- 1
为了更直观的表示,我来画个图:
现在我们想要再来“复制”一个同样的变量。也许第一个闪过脑中的念头就是:
n = m
- 1
但看了前面的文章后你应该知道,这样的赋值只相当于增加了一个标签,并没有新的对象产生:
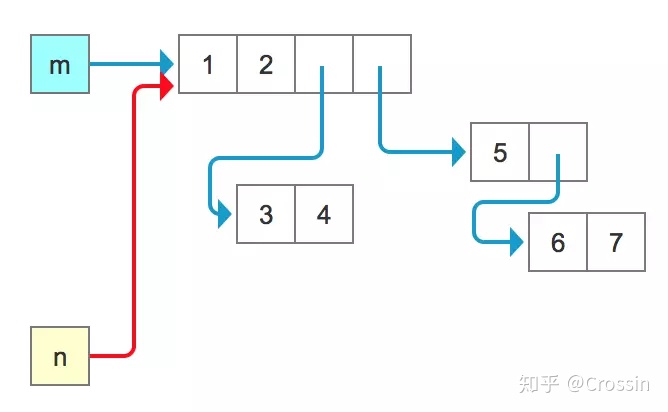
用 id 验证下就知道,m 和 n 仍然是同一个东西。那么他们内部的元素自然也是一样的,对其中一个进行修改,另一个也会跟着变:
m = [1, 2, [3, 4], [5, [6, 7]]]
print('m:', id(m))
print([id(i) for i in m])
n = m
print('n:', id(n))
print([id(i) for i in n])
print(n is m)
print(n[0] is m[0])
print(n[2] is m[2])
n[0] = -1
print(m)
n[2][1] = -1
print(m)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
输出
m: 4564554888
[4556507504, 4556507536, 4564554760, 4564555016]
n: 4564554888
[4556507504, 4556507536, 4564554760, 4564555016]
True
True
True
[-1, 2, [3, 4], [5, [6, 7]]]
[-1, 2, [3, -1], [5, [6, 7]]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
因此有人将此操作称为“旧瓶装旧酒”,只是多贴了一层标签,这不能达到我们的目的。要得到一个对象的“拷贝”,我们需要用到 copy 方法:
from copy import copy
m = [1, 2, [3, 4], [5, [6, 7]]]
print('m:', id(m))
print([id(i) for i in m])
n = copy(m)
print('n:', id(n))
print([id(i) for i in n])
print(n is m)
print(n[0] is m[0])
print(n[2] is m[2])
n[0] = -1
print(m)
n[2][1] = -1
print(m)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
m: 4340253832
[4333009264, 4333009296, 4340253704, 4340253960]
n: 4340268104
[4333009264, 4333009296, 4340253704, 4340253960]
False
True
True
[1, 2, [3, 4], [5, [6, 7]]]
[1, 2, [3, -1], [5, [6, 7]]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
从结果中可以看出,n 和 m 已不是同一个对象,对于某个元素的重新赋值不会影响原对象。但是,它们内部的元素全都是一样的,所以对一个可变类型元素的修改,则仍然会反应在原对象中。
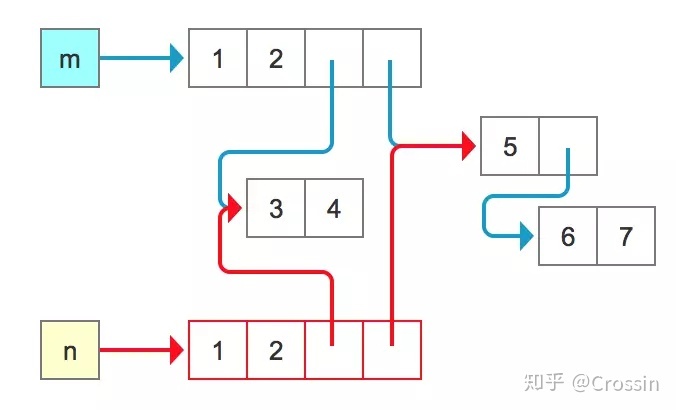
(其实这里1、2也是指向同一个对象,但作为不可变对象来说,它们互不影响,直观上的感受就相当于是复制了一份,故简化如图上所示)
这种复制方法叫做浅拷贝(shallow copy),又被人形象地称作“新瓶装旧酒”,虽然产生了新对象,但里面的内容还是来自同一份。
如果要彻底地产生一个和原对象完全独立的复制品,得使用深拷贝(deep copy):
from copy import deepcopy
m = [1, 2, [3, 4], [5, [6, 7]]]
print('m:', id(m))
print([id(i) for i in m])
n = deepcopy(m)
print('n:', id(n))
print([id(i) for i in n])
print(n is m)
print(n[0] is m[0])
print(n[2] is m[2])
n[0] = -1
print(m)
n[2][1] = -1
print(m)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
输出
m: 4389131400
[4381886832, 4381886864, 4389131272, 4389131528]
n: 4389131208
[4381886832, 4381886864, 4389131656, 4389145736]
False
True
False
[1, 2, [3, 4], [5, [6, 7]]]
[1, 2, [3, 4], [5, [6, 7]]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
此时,对新对象中元素做任何改动都不会影响原对象。新对象中的子列表,无论有多少层,都是新的对象,有不同的地址。
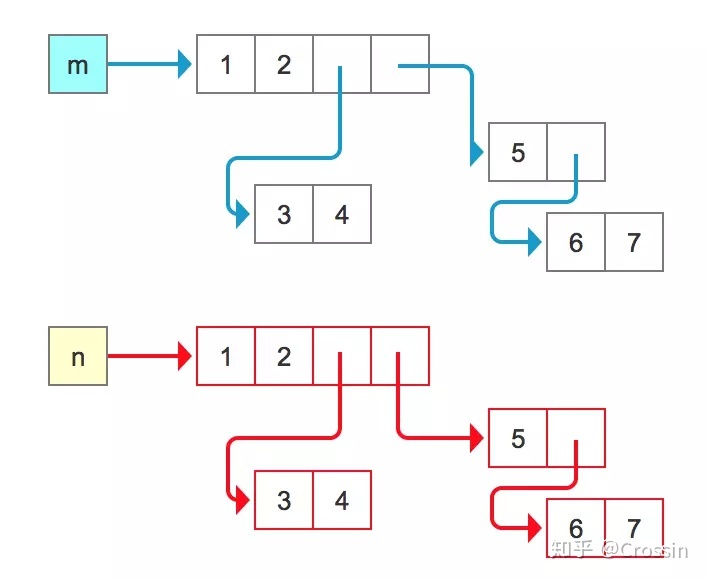
按照前面的比喻,深拷贝就是“新瓶装新酒”。
你可能会注意到一个细节:n 中的前两个元素的地址仍然和 m 中一样。这是由于它们是不可变对象,不存在被修改的可能,所以拷贝和赋值是一样的。
于是,深拷贝也可以理解为,不仅是对象自身的拷贝,而且对于对象中的每一个子元素,也都进行同样的拷贝操作。这是一种递归的思想。
不过额外要说提醒一下的是,深拷贝的实现过程并不是完全的递归,否则如果对象的某级子元素是它自身的话,这个过程就死循环了。实际上,如果遇到已经处理过的对象,就会直接使用其引用,而不再重复处理。听上去有点难懂是不是?想想这个例子大概就会理解了:
from copy import deepcopy
m = [1, 2]
m.append(m)
print(m, id(m), id(m[2]))
n = deepcopy(m)
print(n, id(n), id(n[2]))
- 1
- 2
- 3
- 4
- 5
- 6
输出
[1, 2, [...]] 4479589576 4479589576
[1, 2, [...]] 4479575048 4479575048
- 1
- 2
最后,还是给各位留个思考:
from copy import deepcopy
a = [3, 4]
m = [1, 2, a, [5, a]]
n = deepcopy(m)
n[3][1][0] = -1
print(n)
- 1
- 2
- 3
- 4
- 5
- 6
深拷贝后的 n,修改了其中一个元素值,会是怎样的效果?
思考一下输出会是什么?
然后自己在电脑上或者在线编辑器 Crossin的编程教室 - 在线Python编辑器 里输入代码运行下看看结果,再想想为什么。
欢迎留言给出你的解释。
参考资料:
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/122910432

- 点赞
- 收藏
- 关注作者
评论(0)