五个维度比较四种芯片在AI上的表现

目录
说明
本文参考:,这边篇文章对常用的AI芯片做了比较客观的分析,我截取了部分内容,以便收藏备用。
最常见的四种芯片是CPU、GPU、ASIC、FPGA。五个维度是算力也就是芯片的性能、灵活性、同构性、成本和功耗。
首先就是算力,也就是芯片的性能。这里的性能有很多方面,比如这个芯片做浮点或者定点数运算的时候,每秒的运算次数,以及这个芯片的峰值性能和平均性能等等。灵活性指的是这个AI芯片对不同应用场景的适应程度。也就是说,这个芯片能不能被用于各种不同的AI算法和应用。
同构性指的是,当我们大量部署这个AI芯片的时候,我们能否重复的利用现有的软硬件架构和资源,还是需要引入其他额外的东西。举个简单的例子,比如我的电脑要外接一个显示器,如果这个显示器的接口是HDMI,那么就可以直接连。但是如果这个显示器的接口只有VGA或者DVI或者其他接口,那么我就要买额外的转接头才行。这样,我们就说这个设备,也就是显示器,它对我现有系统的同构性不好。

![]()
成本和功耗就比较好理解了。成本指的就是钱和时间,当然如果细抠的话,还有投入的各种人力物力,以及没有选择其他芯片带来的机会成本等等。不过归根到底还是钱和时间。成本包含两大部分,一部分是芯片的研发成本,另一部分是芯片的部署和运维成本。
功耗就更好理解了,指的就是某种AI芯片对数据中心带来的额外的功耗负担。
CPU
对于CPU来说,它仍然是数据中心里的主要计算单元。事实上,为了更好的支持各种人工智能应用,传统CPU的结构和指令集也在不断迭代和变化。
比如,英特尔最新的Xeon可扩展处理器,就引入了所谓的DL Boost,也就是深度学习加速技术,来加速卷积神经网络和深度神经网络的训练和推理性能。但是相比其他三种芯片,CPU的AI性能还是有一定差距。
CPU最大的优势就是它的灵活性和同构性。对于大部分数据中心来说,它们的各种软硬件基础设施都是围绕CPU设计建设的。所以CPU在数据中心的部署、扩展、运维,包括生态其实都已经非常成熟了。它的功耗和成本不算太低,但也还在可接受的范围内。
GPU
GPU有着大规模的并行架构,非常适合对数据密集型的应用进行计算和处理,比如深度学习的训练过程。和CPU相比,GPU的性能会高几十倍甚至上千倍。因此业界的很多公司,都在使用GPU对各种AI应用进行加速。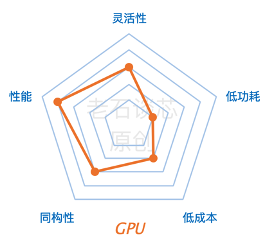
![]()
GPU的另外一个优势,是它有着比较成熟的编程框架,比如CUDA,或者OpenCL等等,这是GPU在AI领域得到爆发最直接的推动力量之一,也是GPU相比FPGA或者ASIC的最大优势之一。
但是,GPU的最大问题就是它的功耗。比如,英伟达的P100、V100和A100 GPU的功耗都在250W到400W之间。相比于FPGA或ASIC的几十瓦甚至几瓦的功耗而言,这个数字显得过于惊人了。目前深度学习训练用的GPU主要是英伟达的GPU。
ASIC
ASIC就是所谓的人工智能专用芯片。这里的典型代表,就是谷歌阿尔法狗里用的TPU。根据谷歌的数据,TPU在阿尔法狗里替代了一千多个CPU和上百个GPU。
![]()
在我们的衡量体系里,这种AI专用芯片的各项指标都非常极端,比如它有着极高的性能和极低的功耗,和GPU相比,它的性能可能会高十倍,功耗会低100倍。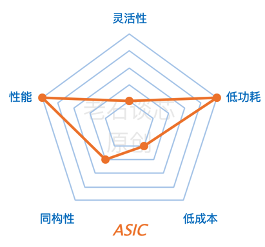
![]()
但是,研发这样的芯片有着极高的成本和风险。与软件开发不同,芯片开发全程都需要大量的人力物力投入,开发周期往往长达数年,而且失败的风险极大。放眼全球,同时拥有雄厚的资金实力和技术储备以进行这类研发的公司,大概用两只手就能数的出来。也就是说,这种方案对于大多数公司而言并可能没有直接的借鉴意义。
此外呢,AI专用芯片的灵活性往往比较低。顾名思义,包括谷歌TPU在内的AI专用芯片,通常是针对某种特定应用而设计开发,因此它可能很难适用于其他的应用。在使用成本的角度,如果要采用基于ASIC的方案,就需要这类目标应用有足够的使用量,以分摊高昂的研发费用。同时,这类应用需要足够稳定,避免核心的算法和协议不断变化。而这对于很多AI应用来说是不现实的。
值得一提的是,我国在人工智能专用芯片领域涌现出来了一波优秀的公司,比如寒武纪、地平线,还有之前被赛灵思收购的深鉴科技等等。受篇幅限制,关于这些公司的具体产品和技术,这里就不再展开了。
![]()
FPGA
最后再来说一下FPGA。我个人认为,FPGA能够在这些性能指标中达到比较理想的平衡。当然了,我目前的职业就和FPGA紧密相关,所以这个结论有屁股决定脑袋之嫌,谨供大家借鉴。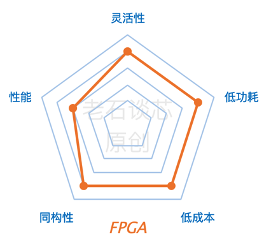
![]()
在性能方面,FPGA可以实现定制化的硬件流水线,并且可以在硬件层面进行大规模的并行运算,而且有着很高的吞吐量。
FPGA最主要的特点其实是它的灵活性,它可以很好的应对包括计算密集型和通信密集型在内的各类应用。此外,FPGA有着动态可编程、部分可编程的特点,也就是说,FPGA可以在同一时刻处理多个应用,也可以在不同时刻处理不同的应用。
在数据中心里,目前FPGA通常以加速卡的形式配合现有的CPU进行大规模部署。FPGA的功耗通常为几十瓦,对额外的供电和散热等环节没有特殊要求,因此可以兼容数据中心的现有硬件基础设施。
在衡量AI芯片的时候,我们也经常使用性能功耗比这个标准。也就是说,即使某种芯片的性能非常高,但是功耗也非常高的话,那么这个芯片的性能功耗比就很低。这也是FPGA相比GPU更有优势的地方。
![]()
在开发成本方面,FPGA的一次性成本其实远低于ASIC,因为FPGA在制造出来之后,可以通过重复编程来改变它的逻辑功能。而专用芯片一旦流片完成就不能修改了,但是每次流片都会耗资巨大。这也是为什么包括深鉴在内的很多AI芯片的初创企业,都使用FPGA作为实现平台的原因。
所以说,相比其他硬件加速单元而言,FPGA在性能、灵活性、同构性、成本和功耗五个方面达到了比较理想的平衡,这也是微软最终选用FPGA,并在数据中心里进行大规模部署的主要原因。

![]()
参考文章:

- 点赞
- 收藏
- 关注作者
评论(0)