【环境空气质量评价挑战赛】baseline——使用lightgbm+特征工程。

赛题
一、赛事背景
随着工业化和城镇化的快速发展,环境问题日益突出。空气污染是全球最重要的环境问题之一,影响着人们的健康、生产和生活。为了改善空气质量,我国加大监测和环保力度,增加空气质量监测站点,实施蓝天保卫战,并将空气质量水平与污染治理水平纳入部门工作考核。科学有效地评价空气质量,能够为预防和治理空气污染提供科学依据,有利于交通或环境管理部门实施污染控制,降低空气污染的影响,改善人类福祉。由于大气环境是受污染源、气象、人为因素的影响,因此需要客观综合地评价空气质量。
二、赛事任务
每日环境空气质量评价需要综合各污染物的影响,本次大赛提供了每日AQI数据和主要污染物浓度数据,参赛选手需构建空气质量评价模型,根据提供的样本评价样本之间的相对污染程度。
三、评审规则
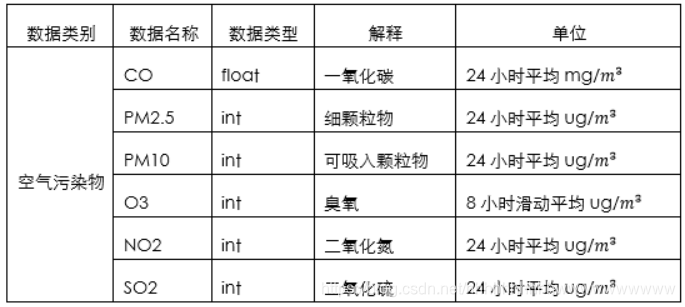
1.数据说明
本次比赛为参赛选手提供了大气污染数据,包括一氧化碳、细颗粒物、可吸入颗粒物、臭氧、二氧化氮、二氧化硫。此次比赛分为初赛和复赛两个阶段,两个阶段的区别是所提供样本的量级和样本城市有所不同,其他的设置均相同。
特别说明,空气质量评价本身是一个不确定性问题,主要采用不确定性方法来构建模型,如模糊数学,灰色理论,证据理论,神经网络等统计分析方法。
2.评估指标
本模型依据提交的结果文件,利用均方根误差(RMSE)评价模型。
(1) 样本的相对综合污染系数 IPRC,用于判断样本之间的相对污染程度。
(2) 基于IPRC,计算RMSE. 其中m为样本数,y为IPRC真实值,y_pred为IPRC预测值。
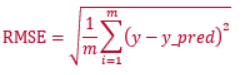
3.评测及排行
1、初赛和复赛均提供下载数据,选手在本地进行算法调试,在比赛页面提交结果。
2、每支团队每天最多提交3次。
3、排行按照得分从高到低排序,排行榜将选择团队的历史最优成绩进行排名。
四、作品提交要求
1.文件格式:按照csv格式提交
2.文件大小:无要求
3.提交次数限制:每支队伍每天最多3次
4.文件详细说明:
-
以csv格式提交,编码为UTF-8,第一行为表头;
-
提交格式见样例
5.不需要上传其他文件
赛题分析
首先分析这个比赛是解决什么问题?从评估指标RMSE我们可以得出这个比赛是回归问题,是预测IPRC的值,所以IPRC是y值,是我们要预测的值。
数据分析
初赛的数据集是保定2016年的空气质量数据,测试集是国际庄2016到2017年的空气质量数据。回想2016年,那时候整个河北的污染还是比较严重的,经常看不到太阳,一年没有几天是好天气。先查看训练集前5行的数据:
执行代码:
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler, MinMaxScaler
train = pd.read_csv('data/train/train.csv')
print(train.head(5))
运行结果:
| 日期 | AQI | 质量等级 | PM2.5 | PM10 | SO2 | CO | NO2 | O3_8h | IPRC |
|---|---|---|---|---|---|---|---|---|---|
| 2016/1/1 | 293 | 重度污染 | 243 | 324 | 122 | 6.1 | 149 | 12 | 2.088378 |
| 2016/1/2 | 430 | 严重污染 | 395 | 517 | 138 | 7.5 | 180 | 18 | 3.316942 |
| 2016/1/3 | 332 | 严重污染 | 282 | 405 | 72 | 6.3 | 130 | 10 | 2.516425 |
| 2016/1/4 | 204 | 重度污染 | 154 | 237 | 73 | 3.5 | 72 | 34 | 1.505693 |
| 2016/1/5 | 169 | 中度污染 | 128 | 186 | 99 | 3.2 | 66 | 39 | 1.210233 |
第一列是时间,对经历过那段时间的人来说,时间肯定是有用的,北方冬天取暖,空气质量差很多。春季和秋季刮风的时候多,好天气自然多一些,夏天有时下雨,下雨了空气的质量就能有所改善,空气质量和季节的相关系比较密切。对于时间的处理,我是采用将年月日分别3列。代码如下:
data["year"] = pd.to_datetime(data["日期"]).dt.year
data["month"] = pd.to_datetime(data["日期"]).dt.month
# 获取日
data["day"] = pd.to_datetime(data["日期"]).dt.day
第二列AQI和PM2.5、PM10、SO2、CO、NO2、O3_8h,这里列的处理方式类似,都采用MinMaxScaler(feature_range=(0, 1)),代码如下:
cols = ["PM2.5", "PM10", "SO2", "CO", "NO2", "O3_8h","day","month","year"]
scaler = MinMaxScaler(feature_range=(0, 1))
for clo in cols:
data[clo] = scaler.fit_transform(data[clo].values.reshape(-1, 1))
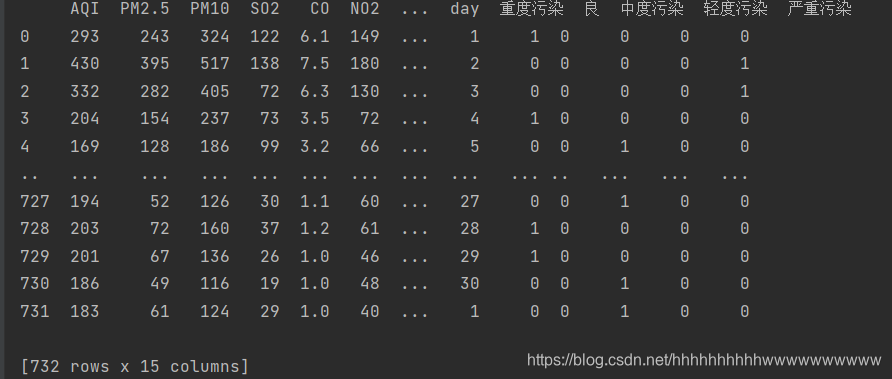
第三列 质量等级,共5个等级,这个毫无疑问用OneHot编码做,我使用pandas 自带的方法实现OneHot编码,编码完成后把质量等级和日期列删除,代码如下:
df = pd.DataFrame({'质量等级': ['重度污染', '良', '中度污染', '轻度污染', '严重污染']})
ff = pd.get_dummies(data['质量等级'].values)
data['重度污染'] = ff['重度污染']
data['良'] = ff['良']
data['中度污染'] = ff['中度污染']
data['轻度污染'] = ff['轻度污染']
data['严重污染'] = ff['严重污染']
del data['质量等级']
del data['日期']
print(data)
运行结果:
标签数据处理 标签采用MinMaxScaler(feature_range=(0, 1)),把标签缩放到0-1之间,方便预测,代码如下:
scaler_y = MinMaxScaler(feature_range=(0, 1))
train['IPRC'] = scaler_y.fit_transform(train['IPRC'].values.reshape(-1, 1))
target = train['IPRC']
数据分析的完整代码如下:
import numpy as np
import pandas as pd
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler, MinMaxScaler
train = pd.read_csv('data/train/train.csv')
print(train.head(5))
test = pd.read_csv('data/test/test.csv')
smb = test['日期'].values
scaler_y = MinMaxScaler(feature_range=(0, 1))
train['IPRC'] = scaler_y.fit_transform(train['IPRC'].values.reshape(-1, 1))
target = train['IPRC']
del train['IPRC']
data = pd.concat([train, test], axis=0, ignore_index=True)
data = data.fillna(0)
data["year"] = pd.to_datetime(data["日期"]).dt.year
data["month"] = pd.to_datetime(data["日期"]).dt.month
# 获取日
data["day"] = pd.to_datetime(data["日期"]).dt.day
df = pd.DataFrame({'质量等级': ['重度污染', '良', '中度污染', '轻度污染', '严重污染']})
ff = pd.get_dummies(data['质量等级'].values)
data['重度污染'] = ff['重度污染']
data['良'] = ff['良']
data['中度污染'] = ff['中度污染']
data['轻度污染'] = ff['轻度污染']
data['严重污染'] = ff['严重污染']
del data['质量等级']
del data['日期']
print(data)
cols = ["PM2.5", "PM10", "SO2", "CO", "NO2", "O3_8h","day","month","year"]
scaler = MinMaxScaler(feature_range=(0, 1))
for clo in cols:
data[clo] = scaler.fit_transform(data[clo].values.reshape(-1, 1))
train = data[:train.shape[0]]
test = data[train.shape[0]:]
# print(X_train)
X_train = train.values
y_train = target.values
X_test = test.values
构建模型
模型选用lightgbm ,lightgbm 是曾经的刷分神器,在kaggle的各种大赛盛极一时。今天我们就讲解如何是用lightgbm 实现回归算法。
第一步 配置参数。
常用的参数有学习力,l2 正则,叶子的节点等等,下面的代码列出了常用的参数配置:
param = {'num_leaves': 600,
'min_data_in_leaf': 30,
'objective': 'rmse',
'max_depth': -1,
'learning_rate': 0.001,
"min_child_samples": 30,
"boosting": "gbdt",
"feature_fraction": 0.9,
"bagging_freq": 1,
"bagging_fraction": 0.9,
"bagging_seed": 12,
"metric": 'mse',
"lambda_l2": 0.1,
'is_unbalance': True,
"verbosity": -1}
为了防止数据不均匀,提高模型的精确度,减轻过拟合,我们采用10折交叉验证。代码如下:
# 五折交叉验证
folds = KFold(n_splits=10, shuffle=True, random_state=42)
oof = np.zeros(len(train))
predictions = np.zeros(len(test))
然后开始训练和测试,设置迭代次数为100000,设置earlystop为1000,如果迭代1000次,loss没有发生变化则终止迭代,代码如下:
for fold_, (trn_idx, val_idx) in enumerate(folds.split(X_train, y_train)):
print("fold n°{}".format(fold_ + 1))
trn_data = lgb.Dataset(X_train[trn_idx], y_train[trn_idx])
val_data = lgb.Dataset(X_train[val_idx], y_train[val_idx])
num_round = 100000
clf = lgb.train(param,
trn_data,
num_round,
valid_sets=[trn_data, val_data],
verbose_eval=2000,
early_stopping_rounds=1000)
oof[val_idx] = clf.predict(X_train[val_idx], num_iteration=clf.best_iteration)
b = [round(i, 3) for i in oof]
predictions += clf.predict(X_test, num_iteration=clf.best_iteration) / folds.n_splits
保存结果
将预测的结果,按照缩放的比例还原,然后将测试结果保存到csv文件中。
inv_y = scaler_y.inverse_transform(predictions.reshape(1, -1))
inv_y = inv_y[0]
print(inv_y)
print("CV score: {:<8.5f}".format(mean_squared_error(oof, target)))
# 提交结果
resuktend = []
for (i1) in zip(inv_y):
resuktend.append(i1)
dataframe = pd.DataFrame({'date': smb, 'class': resuktend})
# 将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("test_estimator.csv", index=False, sep=',')
测试结果如下:

但是提交到竞赛平台上的得分只有0.2左右,过拟合还是很严重的。

- 点赞
- 收藏
- 关注作者
评论(0)