re正则表达式妙用:md的公式标准化

【摘要】
我们在markdown中进行公式书写时,部分会采取引用站外图片的方式,如下。
str1=r'''
### **4.5 多变量决策树**
### **单变量决策树(univariate decision...
我们在markdown中进行公式书写时,部分会采取引用站外图片的方式,如下。
str1=r'''
### **4.5 多变量决策树**
### **单变量决策树(univariate decision tree)**
特点:轴平行(axis-parallel):即它的分类边界由若干个与坐标轴平行的分段组成
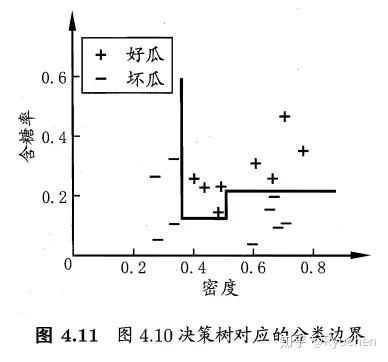
### **多变量决策树(multivariate decision tree)**
特点:非叶结点不再是仅对某个属性进行测试,而是对属性的线性组合进行测试
每一个非叶结点是一个形如  的线性分类器,其中  是属性  的权重
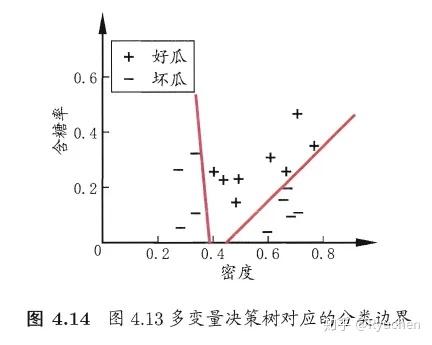
'''
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
利用下面的代码,可以实现内联公式的标准化。
import re
string=str1.replace(r"[]",'@@')
string = string.replace(r"![",'$')
string = re.sub(r"\]\(https(.+?)\)",'$',string)
string = string.replace(r"@@",'[]')
print(string)
- 1
- 2
- 3
- 4
- 5
- 6
结果输出
### **4.5 多变量决策树**
### **单变量决策树(univariate decision tree)**
特点:轴平行(axis-parallel):即它的分类边界由若干个与坐标轴平行的分段组成
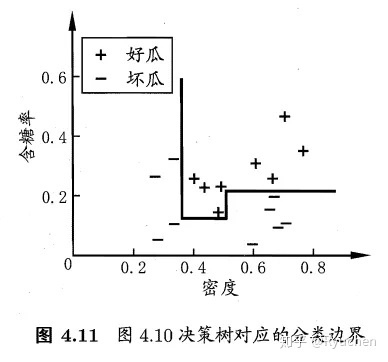
### **多变量决策树(multivariate decision tree)**
特点:非叶结点不再是仅对某个属性进行测试,而是对属性的线性组合进行测试
每一个非叶结点是一个形如 $\sum_{i=1}^dw_ia_i=t$ 的线性分类器,其中 $w_i$ 是属性 $a_i$ 的权重
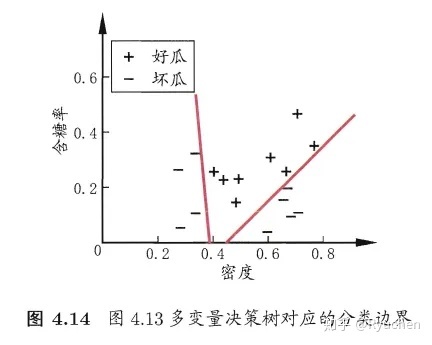
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/122618637

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)