目标跟踪入门:使用OpenCV实现质心跟踪

目标跟踪的过程:
1、获取对象检测的初始集
2、为每个初始检测创建唯一的ID
3、然后在视频帧中跟踪每个对象的移动,保持唯一ID的分配
本文使用OpenCV实现质心跟踪,这是一种易于理解但高效的跟踪算法。
质心跟踪算法步骤
步骤1:接受边界框坐标并计算质心
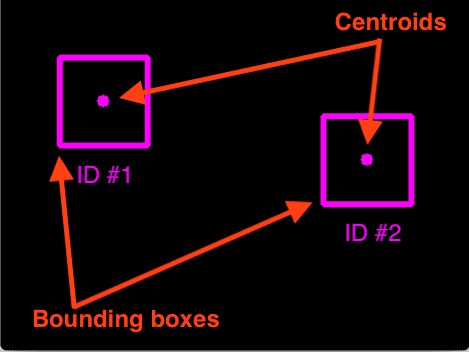
质心跟踪算法假设我们为每一帧中的每个检测到的对象传入一组边界框 (x, y) 坐标。
这些边界框可以由任何类型的对象检测器(颜色阈值 + 轮廓提取、Haar 级联、HOG + 线性 SVM、SSD、Faster R-CNN 等)生成,前提是它们是针对 该视频。
通过边界框坐标,就可以计算“质心”(边界框的中心 (x, y) 坐标)。 如上图演示了通过一组边界框坐标计算出质心。
给初始的边界框分配ID。
步骤2:计算新边界框和现有对象之间的欧几里得距离
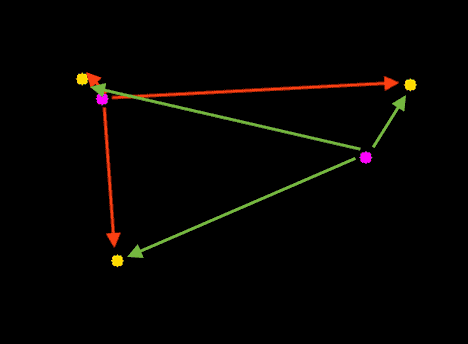
对于视频流中的每个后续帧,首先执行步骤1; 然后,我们首先需要确定是否可以将新的对象质心(黄色)与旧的对象质心(紫色)相关联,而不是为每个检测到的对象分配一个新的唯一 ID(这会破坏对象跟踪的目的)。 为了完成这个过程,我们计算每对现有对象质心和输入对象质心之间的欧几里得距离(用绿色箭头突出显示)。
上图可以看出,我们这次在图像中检测到了三个对象。 靠近的两对是两个现有对象。
然后我们计算每对原始质心(黄色)和新质心(紫色)之间的欧几里得距离。 但是我们如何使用这些点之间的欧几里得距离来实际匹配它们并关联它们呢?
答案在步骤3。
步骤 3:更新现有对象的 (x, y) 坐标

质心跟踪算法的主要假设是给定对象可能会在后续帧之间移动,但帧 F_t 和 F_{t + 1} 的质心之间的距离将小于对象之间的所有其他距离。
因此,如果我们选择将质心与后续帧之间的最小距离相关联,我们可以构建我们的对象跟踪器。
在上图中,可以看到质心跟踪器算法如何选择关联质心以最小化它们各自的欧几里得距离。
但是左下角的孤独点呢?
它没有与任何东西相关联——我们如何处理它?
步骤4:注册新对象
如果输入检测比跟踪的现有对象多,我们需要注册新对象。 “注册”仅仅意味着我们通过以下方式将新对象添加到我们的跟踪对象列表中:
为其分配一个新的对象 ID
存储该对象的边界框坐标的质心
然后我们可以返回到步骤2,重复执行。
上图演示了使用最小欧几里得距离关联现有对象 ID,然后注册新对象的过程。
步骤5:注销旧对象
当旧的对象超出范围时,注销旧对象、
项目结构
ObjectTracking
├── Model
│ ├── init.py
│ └── centroidtracker.py
├── object_tracker.py
├── deploy.prototxt
└──res10_300x300_ssd_iter_140000_fp16.caffemodel
使用 OpenCV 实现质心跟踪
新建 centroidtracker.py,写入代码:
# import the necessary packages
from scipy.spatial import distance as dist
from collections import OrderedDict
import numpy as np
class CentroidTracker():
def __init__(self, maxDisappeared=50):
self.nextObjectID = 0
self.objects = OrderedDict()
self.disappeared = OrderedDict()
# 存储给定对象被允许标记为“消失”的最大连续帧数,直到我们需要从跟踪中注销该对象
self.maxDisappeared = maxDisappeared
导入了所需的包和模块:distance 、 OrderedDict 和 numpy 。
定义类 CentroidTracker 。构造函数接受一个参数maxDisappeared,即给定对象必须丢失/消失的最大连续帧数,如果超过这个数值就将这个对象删除。
四个类变量:
- nextObjectID :用于为每个对象分配唯一 ID 的计数器。如果一个对象离开帧并且没有返回 maxDisappeared 帧,则将分配一个新的(下一个)对象 ID。
- objects :使用对象 ID 作为键和质心 (x, y) 坐标作为值的字典。
- disappeared:保持特定对象 ID(键)已被标记为“丢失”的连续帧数(值)。
- maxDisappeared :在我们取消注册对象之前,允许将对象标记为“丢失/消失”的连续帧数。
让我们定义负责向我们的跟踪器添加新对象的 register 方法:
def register(self, centroid):
# 注册对象时,我们使用下一个可用的对象ID来存储质心
self.objects[self.nextObjectID] = centroid
self.disappeared[self.nextObjectID] = 0
self.nextObjectID += 1
def deregister(self, objectID):
# 要注销注册对象ID,我们从两个字典中都删除了该对象ID
del self.objects[objectID]
del self.disappeared[objectID]
register 方法接受一个质心,然后使用下一个可用的对象 ID 将其添加到对象字典中。
对象消失的次数在消失字典中初始化为 0。
最后,我们增加 nextObjectID,这样如果一个新对象进入视野,它将与一个唯一的 ID 相关联。
与我们的注册方法类似,我们也需要一个注销方法。
deregister 方法分别删除对象和消失字典中的 objectID。
质心跟踪器实现的核心位于update方法中
def update(self, rects):
# 检查输入边界框矩形的列表是否为空
if len(rects) == 0:
# 遍历任何现有的跟踪对象并将其标记为消失
for objectID in list(self.disappeared.keys()):
self.disappeared[objectID] += 1
# 如果达到给定对象被标记为丢失的最大连续帧数,请取消注册
if self.disappeared[objectID] > self.maxDisappeared:
self.deregister(objectID)
# 由于没有质心或跟踪信息要更新,请尽早返回
return self.objects
# 初始化当前帧的输入质心数组
inputCentroids = np.zeros((len(rects), 2), dtype="int")
# 在边界框矩形上循环
for (i, (startX, startY, endX, endY)) in enumerate(rects):
# use the bounding box coordinates to derive the centroid
cX = int((startX + endX) / 2.0)
cY = int((startY + endY) / 2.0)
inputCentroids[i] = (cX, cY)
# 如果我们当前未跟踪任何对象,请输入输入质心并注册每个质心
if len(self.objects) == 0:
for i in range(0, len(inputCentroids)):
self.register(inputCentroids[i])
# 否则,当前正在跟踪对象,因此我们需要尝试将输入质心与现有对象质心进行匹配
else:
# 抓取一组对象ID和相应的质心
objectIDs = list(self.objects.keys())
objectCentroids = list(self.objects.values())
# 分别计算每对对象质心和输入质心之间的距离-我们的目标是将输入质心与现有对象质心匹配
D = dist.cdist(np.array(objectCentroids), inputCentroids)
# 为了执行此匹配,我们必须(1)在每行中找到最小值,然后(2)根据行索引的最小值对行索引进行排序,以使具有最小值的行位于索引列表的* front *处
rows = D.min(axis=1).argsort()
# 接下来,我们在列上执行类似的过程,方法是在每一列中找到最小值,然后使用先前计算的行索引列表进行排序
cols = D.argmin(axis=1)[rows]
# 为了确定是否需要更新,注册或注销对象,我们需要跟踪已经检查过的行索引和列索引
usedRows = set()
usedCols = set()
# 循环遍历(行,列)索引元组的组合
for (row, col) in zip(rows, cols):
# 如果我们之前已经检查过行或列的值,请忽略它
if row in usedRows or col in usedCols:
continue
# 否则,获取当前行的对象ID,设置其新的质心,然后重置消失的计数器
objectID = objectIDs[row]
self.objects[objectID] = inputCentroids[col]
self.disappeared[objectID] = 0
# 表示我们已经分别检查了行索引和列索引
usedRows.add(row)
usedCols.add(col)
# 计算我们尚未检查的行和列索引
unusedRows = set(range(0, D.shape[0])).difference(usedRows)
unusedCols = set(range(0, D.shape[1])).difference(usedCols)
# 如果对象质心的数量等于或大于输入质心的数量
# 我们需要检查一下其中的某些对象是否已潜在消失
if D.shape[0] >= D.shape[1]:
# loop over the unused row indexes
for row in unusedRows:
# 抓取相应行索引的对象ID并增加消失的计数器
objectID = objectIDs[row]
self.disappeared[objectID] += 1
# 检查是否已将该对象标记为“消失”的连续帧数以用于注销该对象的手令
if self.disappeared[objectID] > self.maxDisappeared:
self.deregister(objectID)
# 否则,如果输入质心的数量大于现有对象质心的数量,我们需要将每个新的输入质心注册为可跟踪对象
else:
for col in unusedCols:
self.register(inputCentroids[col])
# return the set of trackable objects
return self.objects
update方法接受边界框矩形列表。 rects 参数的格式假定为具有以下结构的元组: (startX, startY, endX, endY) 。
如果没有检测到,我们将遍历所有对象 ID 并增加它们的消失计数。 我们还将检查是否已达到给定对象被标记为丢失的最大连续帧数。 如果是,我们需要将其从我们的跟踪系统中删除。 由于没有要更新的跟踪信息,我们将提前返回。
否则,我们将初始化一个 NumPy 数组来存储每个 rect 的质心。 然后,我们遍历边界框矩形并计算质心并将其存储在 inputCentroids 列表中。 如果没有我们正在跟踪的对象,我们将注册每个新对象。
否则,我们需要根据最小化它们之间的欧几里得距离的质心位置更新任何现有对象 (x, y) 坐标。
接下来我们在else中计算所有 objectCentroids 和 inputCentroids 对之间的欧几里德距离:
获取 objectID 和 objectCentroid 值。
计算每对现有对象质心和新输入质心之间的距离。距离图 D 的输出 NumPy 数组形状将是 (# of object centroids, # of input centroids) 。要执行匹配,我们必须 (1) 找到每行中的最小值,以及 (2) 根据最小值对行索引进行排序。我们对列执行非常相似的过程,在每列中找到最小值,然后根据已排序的行对它们进行排序。我们的目标是在列表的前面具有最小对应距离的索引值。
下一步是使用距离来查看是否可以关联对象 ID:
初始化两个集合以确定我们已经使用了哪些行和列索引。
然后遍历 (row, col) 索引元组的组合以更新我们的对象质心:
如果我们已经使用了此行或列索引,请忽略它并继续循环。
否则,我们找到了一个输入质心:
- 到现有质心的欧几里得距离最小
- 并且没有与任何其他对象匹配
- 在这种情况下,我们更新对象质心(第 113-115 行)并确保将 row 和 col 添加到它们各自的 usedRows 和 usedCols 集合中。
在我们的 usedRows + usedCols 集合中可能有我们尚未检查的索引:
所以我们必须确定哪些质心索引我们还没有检查过,并将它们存储在两个新的方便集合(unusedRows 和 usedCols)中。
最终检查会处理任何丢失或可能消失的对象:
如果对象质心的数量大于或等于输入质心的数量:
我们需要循环遍历未使用的行索引来验证这些对象是否丢失或消失。
在循环中,我们将:1. 增加他们在字典中消失的次数。 2. 检查消失计数是否超过 maxDisappeared 阈值,如果是,我们将注销该对象。
否则,输入质心的数量大于现有对象质心的数量,我们有新的对象要注册和跟踪.
循环遍历未使用的Cols 索引并注册每个新质心。 最后,我们将可跟踪对象集返回给调用方法。
实现对象跟踪驱动程序脚本
已经实现了 CentroidTracker 类,让我们将其与对象跟踪驱动程序脚本一起使用。
驱动程序脚本是您可以使用自己喜欢的对象检测器的地方,前提是它会生成一组边界框。 这可能是 Haar Cascade、HOG + 线性 SVM、YOLO、SSD、Faster R-CNN 等。
在这个脚本中,需要实现的功能:
1、使用实时 VideoStream 对象从网络摄像头中抓取帧
2、加载并使用 OpenCV 的深度学习人脸检测器
3、实例化 CentroidTracker 并使用它来跟踪视频流中的人脸对象并显示结果。
新建 object_tracker.py 插入代码:
from Model.centroidtracker import CentroidTracker
import numpy as np
import imutils
import time
import cv2
# 定义最低置信度
confidence_t=0.5
# 初始化质心跟踪器和框架尺寸
ct = CentroidTracker()
(H, W) = (None, None)
# 加载检测人脸的模型
print("[INFO] loading model...")
net = cv2.dnn.readNetFromCaffe("deploy.prototxt", "res10_300x300_ssd_iter_140000_fp16.caffemodel")
# 初始化视频流并允许相机传感器预热
print("[INFO] starting video stream...")
vs = cv2.VideoCapture('11.mp4')
time.sleep(2.0)
fps = 30 #保存视频的FPS,可以适当调整
size=(600,1066)#宽高,根据frame的宽和高确定。
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
videoWriter = cv2.VideoWriter('3.mp4',fourcc,fps,size)#最后一个是保存图片的尺寸
导入需要的包。
定义最低置信度。
加载人脸检测模型
初始化视频流或者相机(设置成相机对应的ID就会启动相机)
接下来定义cv2.VideoWriter的参数。
# 循环播放图像流中的帧
while True:
# 从视频流中读取下一帧并调整其大小
(grabbed, frame) = vs.read()
if not grabbed:
break
frame = imutils.resize(frame, width=600)
print(frame.shape)
# 如果帧中尺寸为“无”,则抓住它们
if W is None or H is None:
(H, W) = frame.shape[:2]
# 从帧中构造一个Blob,将其通过网络,
# 获取输出预测,并初始化边界框矩形的列表
blob = cv2.dnn.blobFromImage(frame, 1.0, (W, H),
(104.0, 177.0, 123.0))
net.setInput(blob)
detections = net.forward()
rects = []
# 循环检测
for i in range(0, detections.shape[2]):
# 通过确保预测的概率大于最小阈值来过滤掉弱检测
if detections[0, 0, i, 2] >0.5:
# 计算对象边界框的(x,y)坐标,然后更新边界框矩形列表
box = detections[0, 0, i, 3:7] * np.array([W, H, W, H])
rects.append(box.astype("int"))
# 在对象周围画一个边界框,以便我们可视化它
(startX, startY, endX, endY) = box.astype("int")
cv2.rectangle(frame, (startX, startY), (endX, endY),
(0, 255, 0), 2)
# 使用边界框矩形的计算集更新质心跟踪器
objects = ct.update(rects)
# 循环跟踪对象
for (objectID, centroid) in objects.items():
# 在输出帧上绘制对象的ID和对象的质心
text = "ID {}".format(objectID)
cv2.putText(frame, text, (centroid[0] - 10, centroid[1] - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
cv2.circle(frame, (centroid[0], centroid[1]), 4, (0, 255, 0), -1)
# 显示输出画面
cv2.imshow("Frame", frame)
videoWriter.write(frame)
key = cv2.waitKey(1) & 0xFF
# 如果按下“ q”键,则退出循环
if key == ord("q"):
break
videoWriter.release()
cv2.destroyAllWindows()
vs.release()
遍历帧并将它们调整为固定宽度(同时保持纵横比)。
然后将帧通过 CNN 对象检测器以获得预测和对象位置(。
初始化一个 rects 列表,即边界框矩形。
循环检测detections,如果检测超过我们的置信度阈值,表明检测有效,然后计算边框。
在质心跟踪器对象 ct 上调用 update 方法。
接下来在输出帧上绘制对象的ID和质心,将质心显示为一个实心圆圈和唯一的对象 ID 号文本。 现在我们将能够可视化结果并通过将正确的 ID 与视频流中的对象相关联来检查 CentroidTracker 是否正确地跟踪对象。
运行结果:

限制和缺点
虽然质心跟踪器在这个例子中工作得很好,但这种对象跟踪算法有两个主要缺点。
1、它要求在输入视频的每一帧上运行对象检测步骤。对于非常快速的对象检测器(即颜色阈值和 Haar 级联),必须在每个输入帧上运行检测器可能不是问题。但是,如果在 资源受限的设备上使用计算量大得多的对象检测器,例如 HOG + 线性 SVM 或基于深度学习的检测器,那么帧处理将大大减慢。
2、与质心跟踪算法本身的基本假设有关——质心必须在后续帧之间靠得很近。
这个假设通常成立,但请记住,我们用 2D 帧来表示我们的 3D 世界——当一个对象与另一个对象重叠时会发生什么?
答案是可能发生对象 ID 切换。如果两个或多个对象相互重叠到它们的质心相交的点,而是与另一个相应对象具有最小距离,则算法可能(在不知不觉中)交换对象 ID。重要的是要了解重叠/遮挡对象问题并非特定于质心跟踪 - 它也发生在许多其他对象跟踪器中,包括高级对象跟踪器。然而,质心跟踪的问题更为明显,因为我们严格依赖质心之间的欧几里得距离,并且没有额外的度量、启发式或学习模式。
完整的代码如下:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/76397879

- 点赞
- 收藏
- 关注作者
评论(0)