《西瓜书》吃瓜笔记1、2章-1


基本术语
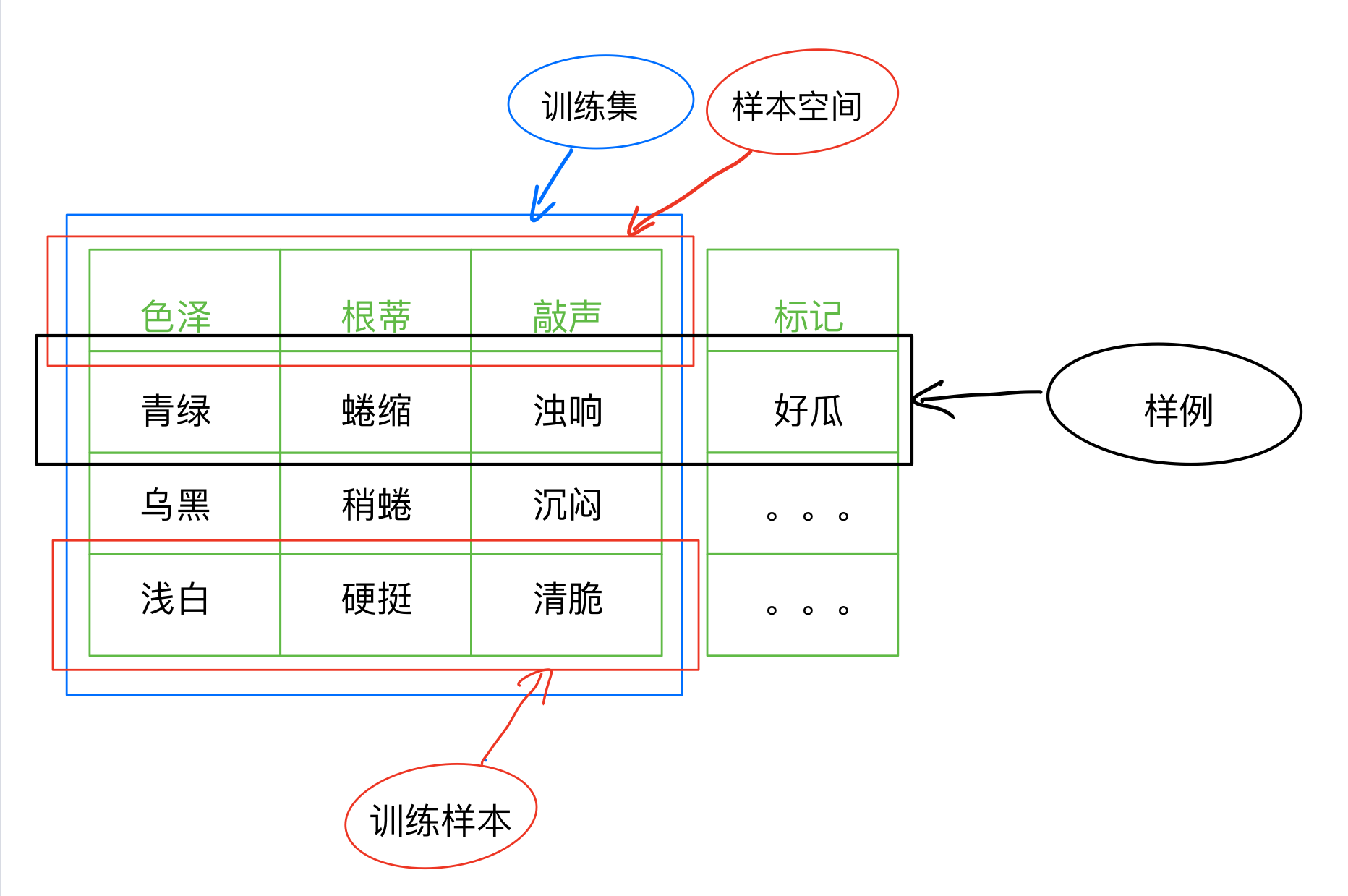
模型: 从数据中学到的结果(泛指)
学习算法: 使用计算机从数据中产生“模型”的算法
属性: 反应事件或对象在某方面的表现或性质的事项
记录: 一组属性对应取值的实例
样本: 每条记录是关于一个事件或对象的描述
数据集: 一组这样的记录或样本称为数据集
属性空间: 一组这样的属性组成的空间我们称为属性空间,或者样本空间(属性值我们可以类比坐标轴上的 x,y,z)
维数: 一组属性的个数
特征向量: 对应坐标轴上的一个点(向量),其实就是一个样本,一条记录
标记: 训练样本的结果信息
下面在来看一下机器学习中另外的一些术语:
假设: 由训练集到模型的一种映射
假设空间: 由训练集到所有模型(样本空间)的所有映射
版本空间: 在实际生活中,我们在假设空间中进行搜索,可能会存在多个假设与训练集一致,这样的多个假设就成为“版本空间”
归纳偏好: 在上述版本空间中,出现了多个假设与训练集一致,这时我们必须选出一个最佳的假设,我们心中这个”最佳的“标准就是我们所说的偏好。
学习/训练: 通过使用之前提到的学习算法,将由训练集获得模型的这个过程;也是在假设空间中进行搜索,找到对应的假设的过程。
监督学习:
无监督学习: 训练数据中不含有标记信息,对于不含标记信息的训练样本,我们也希望可以得到它的模型,对于这种能力我们称之为 “泛化能力”
文中基本术语学习 源自《机器学习》——周志华老师
完成数据建模后,如何衡量模型的效果?有很多种评价指标,侧重点不同,需要结合实际问题或场景来选用。建模是一个循环调试的过程,如果评价指标选得不好,调试的方向不对,最终可能评价指标得分很高,但是偏离了建模的初衷。
- 错误率error rate。(FP+FN)/(TP+TN+FP+FN),对于所有样本,预测错误的比例。
- 精度accuracy。(TP+TN)/(TP+TN+FP+FN),对于所有样本,预测正确的比例。
精度=1-错误率。精度指标的局限性在于:当样本存在类别不平衡时,占比大的类别会成为主要影响因素。例如1000个人里面只有10个新冠阳性患者,如果模型什么都不做,直接把所有人预测为阴性,精度就是990/1000=99%,非常高,但这是没有意义的,甚至会造成误导。
- 查准率precision。TP/(TP+FP),对于预测为正的样本,预测正确的比例。也叫准确率,为了避免中文翻译造成的困扰,要区分精度accuracy和查准率precision,最好直接用英文或者带上英文。
- 查全率recall。TP/(TP+FN),对于真实为正的样本,预测正确的比例。也叫召回率。
precision和recall是既矛盾又统一的两个指标,为了提高precision,模型会在更高的阈值,即更有把握的情况下才把样本预测为正,这样会因为保守而漏掉了“没有把握”的正样本,导致recall降低。通俗点说,查全率就是“宁愿杀错,不要放过”,而查准率就是“宁愿放过,不要杀错”。
- P-R曲线。通过将判断阈值从高到低移动而生成的。对类别不平衡问题会比较敏感,当训练集和测试集分布不一样时,曲线的变动会很大。
- F1score。2*P*R/(P+R),P和R的调和平均数,跟算术平均、几何平均相比,更重视较小值。如果想增加某个指标的重要度,则给它加个调节参数,变成一般形式Fβ。当β>1时查全率有更大的影响;β<1时查准率有更大影响。
- ROC曲线。受试者工作特征曲线,起源于军事领域,后来在医学领域和机器学习领域应用广泛,其名称就是来自于医学领域。ROC反映的是模型对正负样本的排序能力。
相比P-R曲线,ROC曲线有一个特点,当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。这个特点让ROC曲线能够尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能
- AUC。定义为ROC曲线下的面积。因为ROC曲线在很多时候不能清晰地说明哪个分类器的效果更好,而AUC作为一个数值,和模型预测的概率绝对值无关,它只关注样本间的排序效果,其值越大代表模型的效果越好。
- 代价函数。某些场景中,错误的代价不同时怎么办?采用代价敏感错误率
- logloss。用于评价分类器的概率输出。
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/122507791

- 点赞
- 收藏
- 关注作者
评论(0)