人脸检测进阶:使用 dlib、OpenCV 和 Python 检测眼睛、鼻子、嘴唇和下巴等面部五官

使用 dlib、OpenCV 和 Python 检测眼睛、鼻子、嘴唇和下巴
今天的博客文章将首先讨论与面部标志相关的 (x, y) 坐标以及如何将这些面部标志映射到面部的特定区域。
然后我们将编写一些可用于提取每个面部区域的代码。
我们将通过在一些示例图像上演示我们的方法的结果来结束博客文章。
在这篇博文结束时,您将对如何通过面部标志(自动)提取面部区域有深入的了解,并将能够将这些知识应用到您自己的应用程序中。
面部区域的面部标志性索引
在 dlib 中实现的面部标志检测器产生 68 个 (x, y) 坐标,这些坐标映射到特定的面部结构。 这 68 个点映射是通过在标记的 iBUG 300-W 数据集上训练形状预测器获得的。
下面我们可以可视化这 68 个坐标中的每一个映射到的内容:
 检查图像,我们可以看到面部区域可以通过简单的 Python 索引访问(假设使用 Python 进行零索引,因为上图是单索引):
检查图像,我们可以看到面部区域可以通过简单的 Python 索引访问(假设使用 Python 进行零索引,因为上图是单索引):
嘴巴: [48, 68] 。
右眉:[17, 22]。
左眉: [22, 27]。
右眼: [36, 42]。
左眼: [42, 48]。
鼻子: [27, 35]。
下巴: [0, 17]。
这些映射在 imutils 库的 face_utils 内的 FACIAL_LANDMARKS_IDXS 字典中编码:
# 定义一个映射面部索引的字典
# 特定面部区域的标记
FACIAL_LANDMARKS_IDXS = OrderedDict([
("mouth", (48, 68)),
("right_eyebrow", (17, 22)),
("left_eyebrow", (22, 27)),
("right_eye", (36, 42)),
("left_eye", (42, 48)),
("nose", (27, 35)),
("jaw", (0, 17))
])
使用这个字典,我们可以轻松地将索引提取到面部标志数组中,并只需提供一个字符串作为键即可提取各种面部特征。
可视化面部标记
稍微困难的任务是将这些面部标志中的每一个可视化并将结果叠加在输入图像上。为此,我们需要 imutils 库中已包含的visualize_facial_landmarks 函数:
def visualize_facial_landmarks(image, shape, colors=None, alpha=0.75):
# create two copies of the input image -- one for the
# overlay and one for the final output image
overlay = image.copy()
output = image.copy()
# if the colors list is None, initialize it with a unique
# color for each facial landmark region
if colors is None:
colors = [(19, 199, 109), (79, 76, 240), (230, 159, 23),
(168, 100, 168), (158, 163, 32),
(163, 38, 32), (180, 42, 220)]
我们的visualize_facial_landmarks 函数需要两个参数,后跟两个可选参数,每个参数的详细信息如下:
image :我们将在其上绘制面部标志性可视化的图像。
shape : NumPy 数组,包含映射到不同面部部位的 68 个面部标志坐标。
colors :用于对每个面部标志区域进行颜色编码的 BGR 元组列表。
alpha :用于控制原始图像上叠加层的不透明度的参数。
我们现在准备通过面部标志来可视化每个单独的面部区域:
# 分别循环面部标志区域
for (i, name) in enumerate(FACIAL_LANDMARKS_IDXS.keys()):
# 获取与关联的 (x, y) 坐标
#人脸地标
(j, k) = FACIAL_LANDMARKS_IDXS[name]
pts = shape[j:k]
# 检查是否应该绘制下颌线
if name == "jaw":
# 由于下颌线是一个非封闭的面部区域,
# 只在 (x, y) 坐标之间画线
for l in range(1, len(pts)):
ptA = tuple(pts[l - 1])
ptB = tuple(pts[l])
cv2.line(overlay, ptA, ptB, colors[i], 2)
# 否则,计算人脸的凸包
# 地标坐标点并显示
else:
hull = cv2.convexHull(pts)
cv2.drawContours(overlay, [hull], -1, colors[i], -1)
遍历 FACIAL_LANDMARKS_IDXS 字典中的每个条目。
对于这些区域中的每一个,我们提取给定面部部分的索引并从形状 NumPy 数组中获取 (x, y) 坐标。
检查是否正在绘制下颌,如果是,只需循环各个点,绘制一条将下颌点连接在一起的线。
否则,处理计算点的凸包并在叠加层上绘制包。
最后一步是通过 cv2.addWeighted 函数创建透明叠加层:
# 应用透明覆盖
cv2.addWeighted(overlay, alpha, output, 1 - alpha, 0, output)
# return the output image
return output
将visualize_facial_landmarks 应用于图像和关联的面部标记后,输出将类似于下图:

使用 dlib、OpenCV 和 Python 提取部分人脸
新建一个文件,将其命名为 detect_face_parts.py ,并插入以下代码:
# import the necessary packages
from imutils import face_utils
import numpy as np
import argparse
import imutils
import dlib
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-p", "--shape-predictor", required=True,
help="path to facial landmark predictor")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
# 初始化dlib的人脸检测器(基于HOG)然后创建
# 面部标志预测器
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(args["shape_predictor"])
# 加载输入图像,调整大小,并将其转换为灰度
image = cv2.imread(args["image"])
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 在灰度图像中检测人脸
rects = detector(gray, 1)
导入我们需要的 Python 包。
解析我们的命令行参数。
实例化 dlib 的基于 HOG 的面部检测器并加载面部标志预测器。
加载和预处理我们的输入图像。
在我们的输入图像中检测人脸。
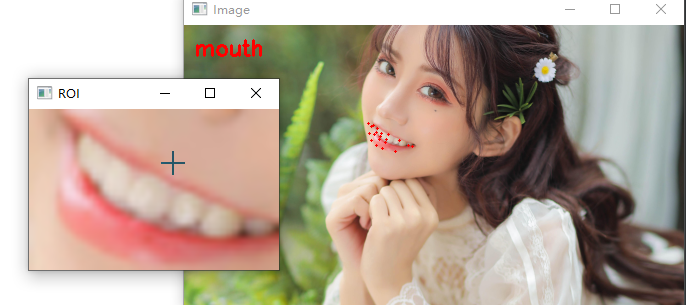
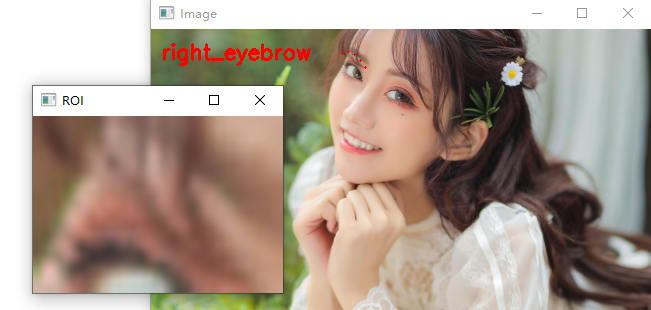
现在我们已经在图像中检测到人脸,我们可以单独循环每个人脸 ROI:
# 循环面部检测
for (i, rect) in enumerate(rects):
# 确定面部区域的面部标志,然后
# 将地标 (x, y) 坐标转换为 NumPy 数组
shape = predictor(gray, rect)
shape = face_utils.shape_to_np(shape)
# 单独循环面部部分
for (name, (i, j)) in face_utils.FACIAL_LANDMARKS_IDXS.items():
# 克隆原始图像,以便我们可以在其上绘制,然后
# 在图像上显示人脸部分的名称
clone = image.copy()
cv2.putText(clone, name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX,
0.7, (0, 0, 255), 2)
# 循环面部标志的子集,绘制
# 特定的面部部分
for (x, y) in shape[i:j]:
cv2.circle(clone, (x, y), 1, (0, 0, 255), -1)
对于每个面部区域,确定 ROI 的面部标志,并将 68 个点转换为 NumPy 数组。
然后,对于每个面部部分,遍历它们。
绘制面部区域的名称/标签,然后将每个单独的面部标志绘制为圆圈。
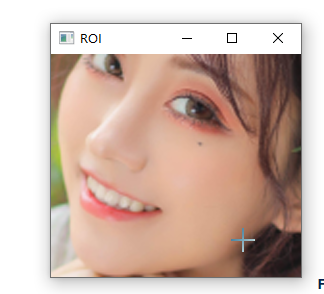
要实际提取每个面部区域,只需要计算与特定区域关联的 (x, y) 坐标的边界框,并使用 NumPy 数组切片来提取它:
# 提取人脸区域的ROI作为单独的图像
(x, y, w, h) = cv2.boundingRect(np.array([shape[i:j]]))
roi = image[y:y + h, x:x + w]
roi = imutils.resize(roi, width=250, inter=cv2.INTER_CUBIC)
# 显示特定的人脸部分
cv2.imshow("ROI", roi)
cv2.imshow("Image", clone)
cv2.waitKey(0)
# 使用透明叠加可视化所有面部标志
output = face_utils.visualize_facial_landmarks(image, shape)
cv2.imshow("Image", output)
cv2.waitKey(0)
计算区域的边界框通过 cv2.boundingRect 处理。
使用 NumPy 数组切片,提取 ROI。
然后将此 ROI 调整为 250 像素的宽度,以便我们可以更好地对其进行可视化。
将单个人脸区域显示到我们的屏幕上。
然后应用visualize_facial_landmarks 函数为每个面部部分创建一个透明的叠加层。
人脸部分标注结果
代码已经编写完了,让我们来看看一些结果。
打开终端输入下面命令来可视化结果:
python detect_face_parts.py --shape-predictor shape_predictor_68_face_landmarks.dat --image 11.jpg


总结
在这篇博文中,我演示了如何使用面部标记检测来检测图像中的各种面部结构。
具体来说,我们学习了如何检测和提取:
嘴
右眉
左眉
右眼
左眼
鼻子
下颌线
这是使用 dlib 的预训练面部标记检测器以及一些 OpenCV 和 Python 来完成的。
在这一点上,您可能对面部标记的准确性印象深刻——使用面部标志有明显的优势,尤其是在面部对齐、面部交换和提取各种面部结构方面。
完整代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/54155398

- 点赞
- 收藏
- 关注作者
评论(0)