激活函数汇总,包含公式、求导过程以及numpy实现,妥妥的万字干货

【摘要】 @[toc] 1、激活函数的实现 1.1 sigmoid 1.1.1 函数函数:f(x)=11+e−xf(x)=\frac{1}{1+e^{-x}}f(x)=1+e−x1 1.1.2 导数求导过程:根据:(uv)′=u′v−uv′v2\left ( \frac{u}{v} \right ){}'=\frac{{u}'v-u{v}'}{v^{2}}(vu)′=v2u′v−uv′f(x)′...
@[toc]
1、激活函数的实现
1.1 sigmoid
1.1.1 函数
函数:
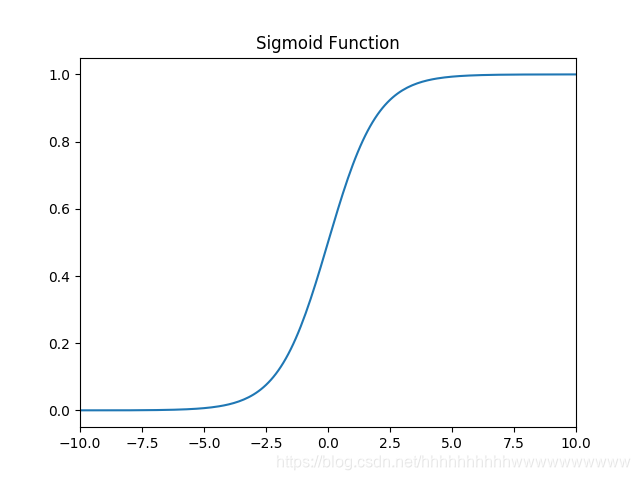
1.1.2 导数
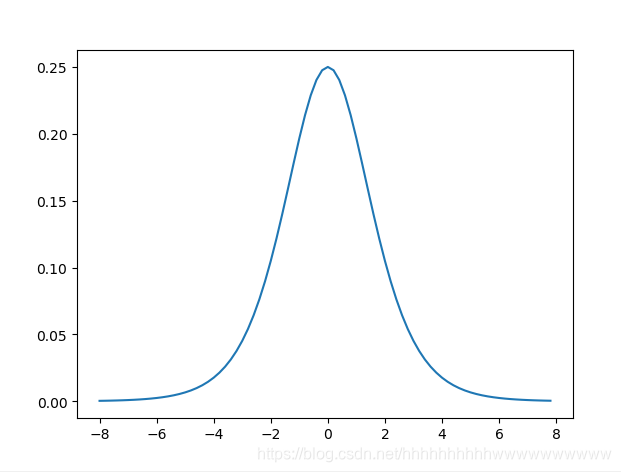
求导过程:
根据:
1.1.3 代码实现
import numpy as np
class Sigmoid():
def __call__(self, x):
return 1 / (1 + np.exp(-x))
def gradient(self, x):
return self.__call__(x) * (1 - self.__call__(x))
1.2 softmax
1.2.1 函数
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个元素的softmax值就是:
更形象的如下图表示:
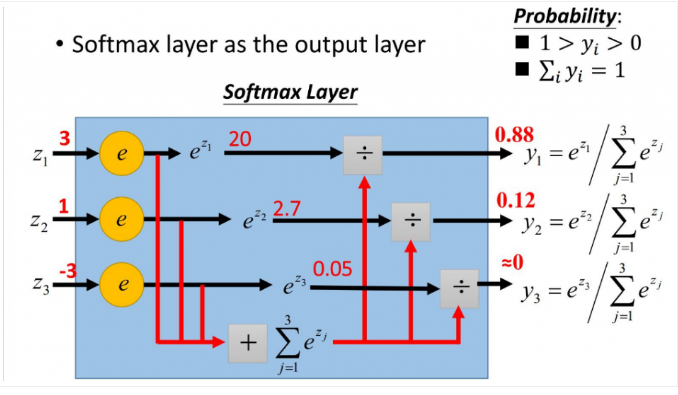
要使用梯度下降,就需要一个损失函数,一般使用交叉熵作为损失函数,交叉熵函数形式如下:
1.2.2 导数
求导分为两种情况。
第一种j=i:
推导过程如下:
1.2.3 代码实现
import numpy as np
class Softmax():
def __call__(self, x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / np.sum(e_x, axis=-1, keepdims=True)
def gradient(self, x):
p = self.__call__(x)
return p * (1 - p)
1.3 tanh
1.3.1 函数
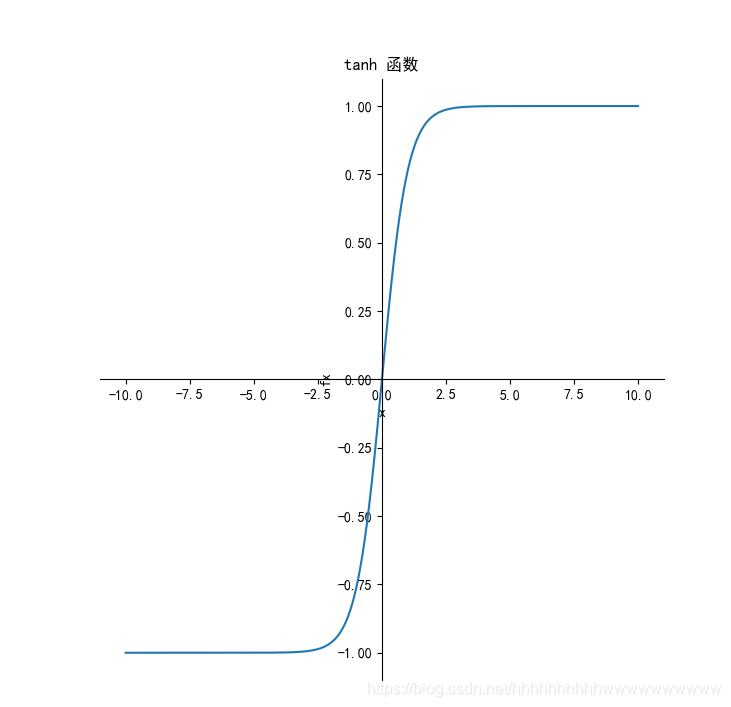
1.3.2 导数
求导过程:
1.3.3 代码实现
import numpy as np
class TanH():
def __call__(self, x):
return 2 / (1 + np.exp(-2*x)) - 1
def gradient(self, x):
return 1 - np.power(self.__call__(x), 2)
1.4 relu
1.4.1 函数
1.4.2 导数
1.4.3 代码实现
import numpy as np
class ReLU():
def __call__(self, x):
return np.where(x >= 0, x, 0)
def gradient(self, x):
return np.where(x >= 0, 1, 0)
1.5 leakyrelu
1.5.1 函数
1.5.2 导数
1.5.3 代码实现
import numpy as np
class LeakyReLU():
def __init__(self, alpha=0.2):
self.alpha = alpha
def __call__(self, x):
return np.where(x >= 0, x, self.alpha * x)
def gradient(self, x):
return np.where(x >= 0, 1, self.alpha)
1.6 ELU
1.61 函数
1.6.2 导数
当x>=0时,导数为1。
当x<0时,导数的推导过程:
所以,完整的导数为:
1.6.3 代码实现
import numpy as np
class ELU():
def __init__(self, alpha=0.1):
self.alpha = alpha
def __call__(self, x):
return np.where(x >= 0.0, x, self.alpha * (np.exp(x) - 1))
def gradient(self, x):
return np.where(x >= 0.0, 1, self.__call__(x) + self.alpha)
1.7 selu
1.7.1 函数
1.7.2 导数
1.7.3 代码实现
import numpy as np
class SELU():
# Reference : https://arxiv.org/abs/1706.02515,
# https://github.com/bioinf-jku/SNNs/blob/master/SelfNormalizingNetworks_MLP_MNIST.ipynb
def __init__(self):
self.alpha = 1.6732632423543772848170429916717
self.scale = 1.0507009873554804934193349852946
def __call__(self, x):
return self.scale * np.where(x >= 0.0, x, self.alpha*(np.exp(x)-1))
def gradient(self, x):
return self.scale * np.where(x >= 0.0, 1, self.alpha * np.exp(x))
1.8 softplus
1.81 函数
1.8.2 导数
log默认的底数是
1.8.3 代码实现
import numpy as np
class SoftPlus():
def __call__(self, x):
return np.log(1 + np.exp(x))
def gradient(self, x):
return 1 / (1 + np.exp(-x))
1.9 Swish
1.9.1 函数
1.9.2 导数
1.9.3 代码实现
import numpy as np
class Swish(object):
def __init__(self, b):
self.b = b
def __call__(self, x):
return x * (np.exp(self.b * x) / (np.exp(self.b * x) + 1))
def gradient(self, x):
return self.b * x / (1 + np.exp(-self.b * x)) + (1 / (1 + np.exp(-self.b * x)))(
1 - self.b * (x / (1 + np.exp(-self.b * x))))
1.10 Mish
1.10.1 函数
1.10.2 导数
where softplus and sigmoid .
1.10.3 代码实现
import numpy as np
def sech(x):
"""sech函数"""
return 2 / (np.exp(x) + np.exp(-x))
def sigmoid(x):
"""sigmoid函数"""
return 1 / (1 + np.exp(-x))
def soft_plus(x):
"""softplus函数"""
return np.log(1 + np.exp(x))
def tan_h(x):
"""tanh函数"""
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
class Mish:
def __call__(self, x):
return x * tan_h(soft_plus(x))
def gradient(self, x):
return sech(soft_plus(x)) * sech(soft_plus(x)) * x * sigmoid(x) + tan_h(soft_plus(x))
1.11 SiLU
1.11.1 函数
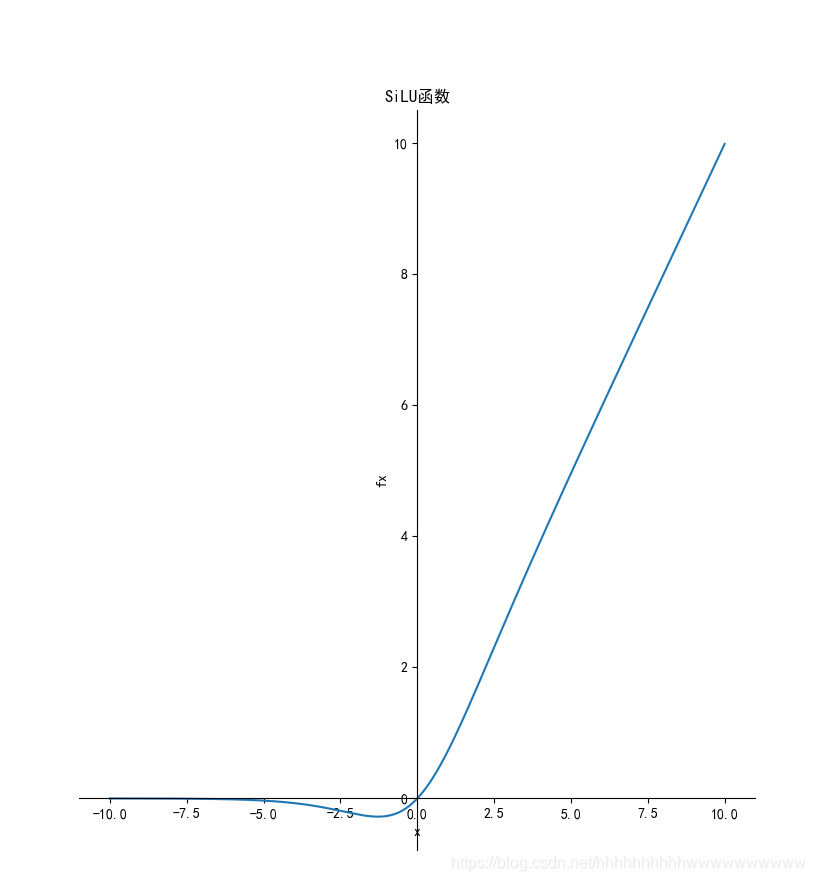
1.11.2 导数
推导过程
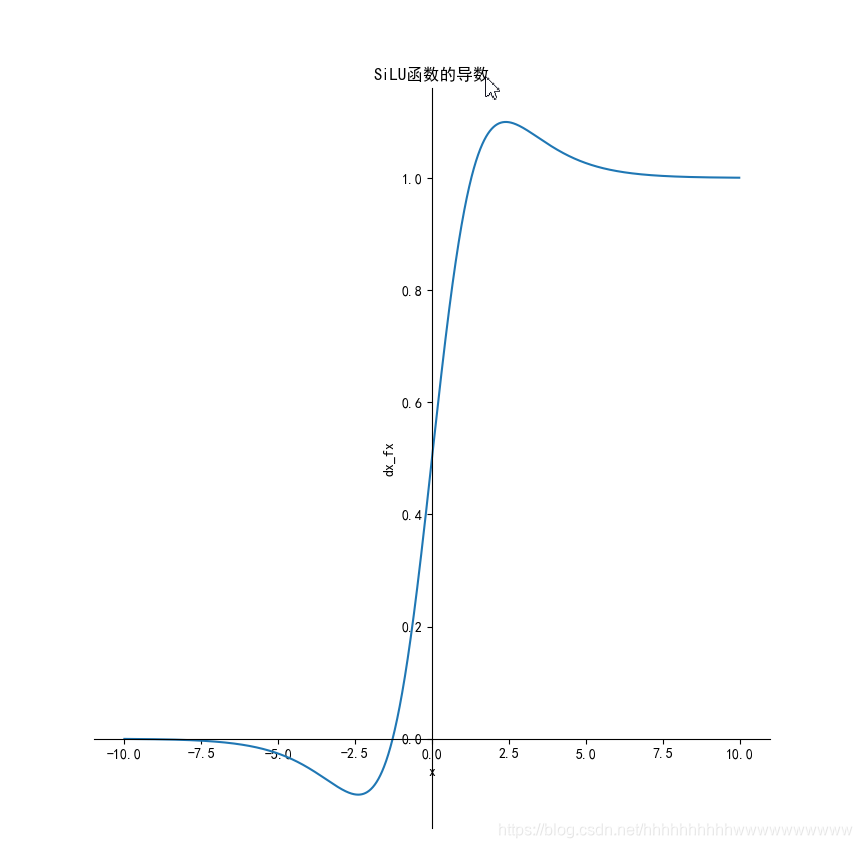
1.11.3 代码实现
import numpy as np
def sigmoid(x):
"""sigmoid函数"""
return 1 / (1 + np.exp(-x))
class SILU(object):
def __call__(self, x):
return x * sigmoid(x)
def gradient(self, x):
return self.__call__(x) + sigmoid(x) * (1 - self.__call__(x))
1.12 完整代码
定义一个activation_function.py,将下面的代码复制进去,到这里激活函数就完成了。
import numpy as np
# Collection of activation functions
# Reference: https://en.wikipedia.org/wiki/Activation_function
class Sigmoid():
def __call__(self, x):
return 1 / (1 + np.exp(-x))
def gradient(self, x):
return self.__call__(x) * (1 - self.__call__(x))
class Softmax():
def __call__(self, x):
e_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return e_x / np.sum(e_x, axis=-1, keepdims=True)
def gradient(self, x):
p = self.__call__(x)
return p * (1 - p)
class TanH():
def __call__(self, x):
return 2 / (1 + np.exp(-2 * x)) - 1
def gradient(self, x):
return 1 - np.power(self.__call__(x), 2)
class ReLU():
def __call__(self, x):
return np.where(x >= 0, x, 0)
def gradient(self, x):
return np.where(x >= 0, 1, 0)
class LeakyReLU():
def __init__(self, alpha=0.2):
self.alpha = alpha
def __call__(self, x):
return np.where(x >= 0, x, self.alpha * x)
def gradient(self, x):
return np.where(x >= 0, 1, self.alpha)
class ELU(object):
def __init__(self, alpha=0.1):
self.alpha = alpha
def __call__(self, x):
return np.where(x >= 0.0, x, self.alpha * (np.exp(x) - 1))
def gradient(self, x):
return np.where(x >= 0.0, 1, self.__call__(x) + self.alpha)
class SELU():
# Reference : https://arxiv.org/abs/1706.02515,
# https://github.com/bioinf-jku/SNNs/blob/master/SelfNormalizingNetworks_MLP_MNIST.ipynb
def __init__(self):
self.alpha = 1.6732632423543772848170429916717
self.scale = 1.0507009873554804934193349852946
def __call__(self, x):
return self.scale * np.where(x >= 0.0, x, self.alpha * (np.exp(x) - 1))
def gradient(self, x):
return self.scale * np.where(x >= 0.0, 1, self.alpha * np.exp(x))
class SoftPlus(object):
def __call__(self, x):
return np.log(1 + np.exp(x))
def gradient(self, x):
return 1 / (1 + np.exp(-x))
class Swish(object):
def __init__(self, b):
self.b = b
def __call__(self, x):
return x * (np.exp(self.b * x) / (np.exp(self.b * x) + 1))
def gradient(self, x):
return self.b * x / (1 + np.exp(-self.b * x)) + (1 / (1 + np.exp(-self.b * x)))(
1 - self.b * (x / (1 + np.exp(-self.b * x))))
def sech(x):
"""sech函数"""
return 2 / (np.exp(x) + np.exp(-x))
def sigmoid(x):
"""sigmoid函数"""
return 1 / (1 + np.exp(-x))
def soft_plus(x):
"""softplus函数"""
return np.log(1 + np.exp(x))
def tan_h(x):
"""tanh函数"""
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
class Mish:
def __call__(self, x):
return x * tan_h(soft_plus(x))
def gradient(self, x):
return sech(soft_plus(x)) * sech(soft_plus(x)) * x * sigmoid(x) + tan_h(soft_plus(x))
class SILU(object):
def __call__(self, x):
return x * sigmoid(x)
def gradient(self, x):
return self.__call__(x) + sigmoid(x) * (1 - self.__call__(x))
参考公式
双曲正弦:
双曲余弦:
双曲正切:
双曲余切:
双曲正割:
双曲余割:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)