网易三面:说说Kafka的Follower是如何拉取Leader消息的?

搞懂AbstractFetcherThread的processPartitionData、truncate、buildFetch方法,就掌握了拉取线程的处理逻辑。最后搞懂串联起这三个方法的doWork方法就能完整理解Follower副本应用拉取线程(即ReplicaFetcherThread线程),从Leader副本获取消息并处理的流程了。
AbstractFetcherThread#doWork
doWork,AbstractFetcherThread的核心方法,线程的主逻辑运行方法:

AbstractFetcherThread线程只要一直处运行状态,就会不断重复这俩操作。
-
为何AbstractFetcherThread线程要不断尝试截断?
因为分区的Leader可能随时变化。每当有新Leader产生,Follower副本就必须主动执行截断,将自己的本地日志裁剪成与Leader一模一样的消息序列,甚至,Leader副本也要执行截断,将LEO调整到分区高水位处。
maybeTruncate

先对分区状态进行分组。既然是做截断,则该方法操作的就只能是处于【截断中】状态的分区。
Leader Epoch机制,替换高水位值在日志截断中的作用:
- 当分区存在Leader Epoch值,将副本的本地日志截断到Leader Epoch对应的最新位移值处,truncateToEpochEndOffsets实现
- 若分区不存在对应Leader Epoch记录,则仍使用原来高水位机制,调用truncateToHighWatermark将日志调整到高水位值处
truncateToHighWatermark

- 先遍历给定的所有分区
- 依次为每个分区获取当前高水位值,并保存在分区读取状态类
- 调用doTruncate执行日志截断
- 等给定的所有分区都执行对应操作后,更新这组分区的分区读取状态
doTruncate调用抽象方法truncate,而truncate实现在ReplicaFetcherThread。
maybeFetch

第1步,为partitionStates中的分区构造FetchRequest.Builder对象,之后调用其build方法创建FetchRequest请求对象。这里的partitionStates保存要去获取消息的一组分区及对应状态信息。该步的输出结果是两个对象:
- ReplicaFetch,要读取的分区核心信息+ FetchRequest.Builder对象。核心信息指要读取哪个分区,从哪个位置开始读,最多读多少字节等
- 一组出错分区
第2步,处理出错分区:将这组分区加入到有序Map末尾,等待后续重试。若发现当前无可读取分区,会阻塞等待一段时间
第3步,发送FETCH请求给对应Leader副本,并处理相应Response,即processFetchRequest要做的事。
processFetchRequest


子类:ReplicaFetcherThread
ReplicaFetcherThread继承自AbstractFetcherThread,是Follower副本端创建的线程,用于向Leader副本拉取消息数据。
类定义及字段
ReplicaFetcherThread的定义代码有些长,但构造器中大部分字段都解析过了。现在,只需学习ReplicaFetcherThread类的字段:

消息获相关字段:

都是FETCH请求的参数,主要控制Follower副本拉取Leader副本消息的行为,如:
- 一次请求到底能获取多少字节数据
- 或当未达到累积阈值时,FETCH请求等待多长时间等
API
Follower副本拉取线程要做的最重要的三件事:
- 处理拉取的消息
- 构建拉取消息的请求
- 执行截断日志操作
processPartitionData
AbstractFetcherThread线程从Leader副本拉取回消息后,要调用processPartitionData执行后续动作:

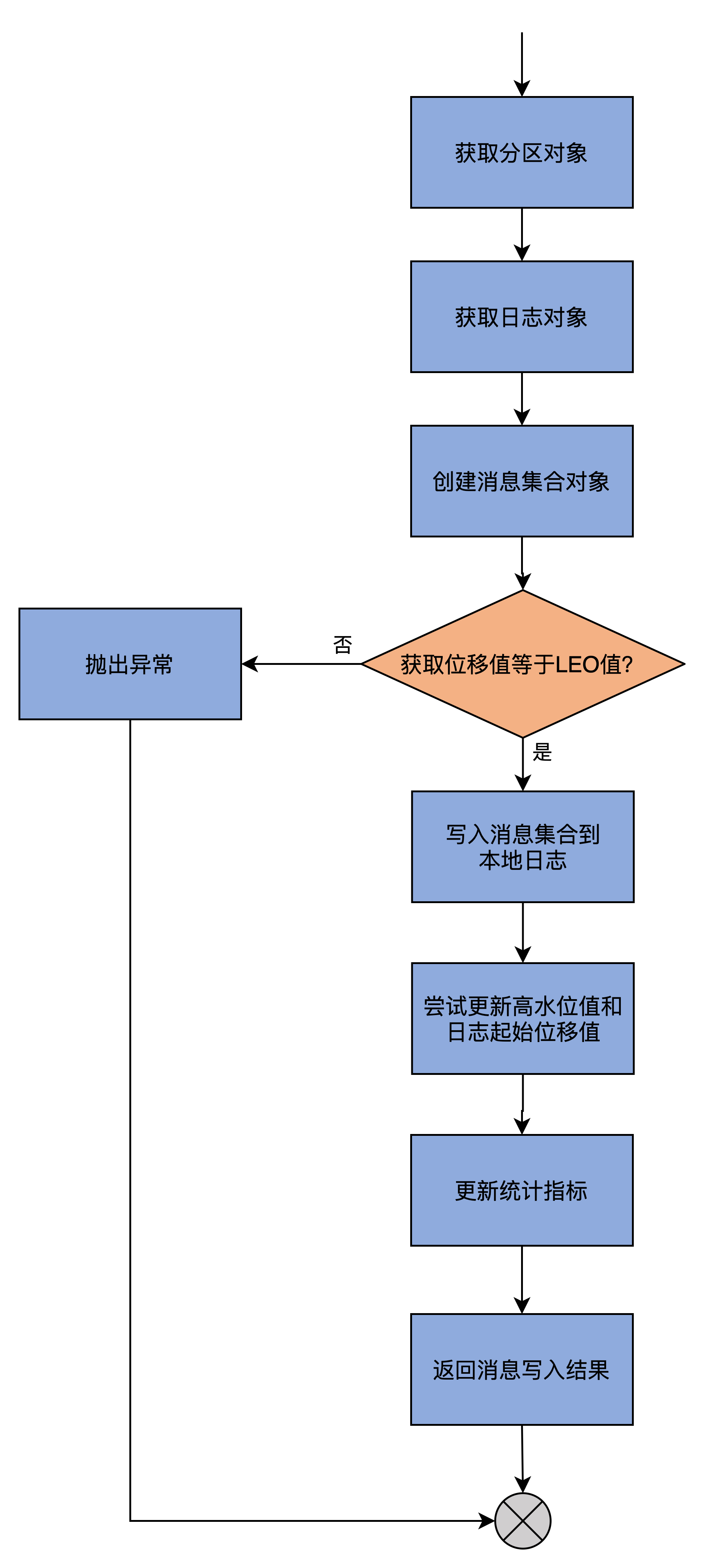
processPartitionData中的process就是写入Follower副本本地日志。因此,该方法的主体逻辑就是调用分区对象Partition的appendRecordsToFollowerOrFutureReplica写入获取到的消息。沿着这个写入方法追踪,就会发现它调用appendAsFollower。
仅写入日志还不够,还要做一些更新。如更新Follower副本的高水位值:将FETCH请求Response中包含的高水位值作为新的高水位值,还要尝试更新Follower副本的Log Start Offset值。
为何Log Start Offset值也可能变化?因为Leader的Log Start Offset可能发生变化,如用户手动执行删除消息的操作。Follower副本的日志要和Leader保持严格一致,因此,若Leader的该值发生变化,Follower自然也要发生变化。
此外还会更新其他一些统计指标值,最后将写入结果返回。
buildFetch
构建发送给Leader副本所在Broker的FETCH请求:

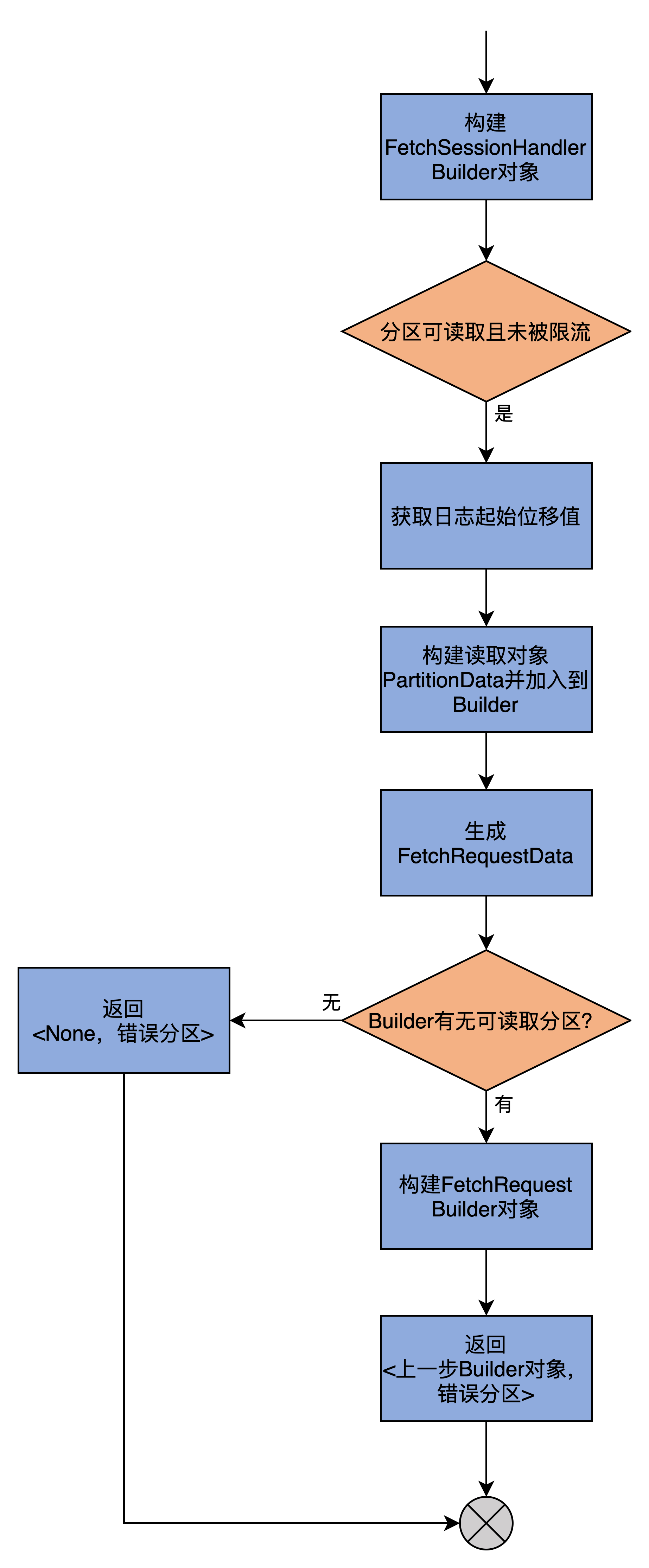
构造FETCH请求的Builder对象然后返回。有Builder对象,就能构造出FETCH请求,仅需调用builder.build()。
该方法的一个副产品是汇总出错分区,调用方后续可统一处理这些出错分区。
构造Builder的过程中,会用到ReplicaFetcherThread类定义的那些与消息获取相关的字段,如maxWait、minBytes和maxBytes。
truncate
对给定分区执行日志截断操作:
override def truncate(
tp: TopicPartition,
offsetTruncationState: OffsetTruncationState): Unit = {
// 拿到分区对象
val partition = replicaMgr.nonOfflinePartition(tp).get
//拿到分区本地日志
val log = partition.localLogOrException
// 执行截断操作,截断到的位置由offsetTruncationState的offset指定
partition.truncateTo(offsetTruncationState.offset, isFuture = false)
if (offsetTruncationState.offset < log.highWatermark)
warn(s"Truncating $tp to offset ${offsetTruncationState.offset} below high watermark " +
s"${log.highWatermark}")
if (offsetTruncationState.truncationCompleted)
replicaMgr.replicaAlterLogDirsManager
.markPartitionsForTruncation(brokerConfig.brokerId, tp,
offsetTruncationState.offset)
}
利用给定的offsetTruncationState的offset值,对给定分区的本地日志进行截断操作。该操作由Partition对象的truncateTo方法完成,但实际上底层调用的是Log#truncateTo:将日志截断到小于给定值的最大位移值处。
总结
AbstractFetcherThread线程的doWork完整了拉取线程要执行的逻辑,即日志截断(truncate)+日志获取(buildFetch)+日志处理(processPartitionData),而其子类ReplicaFetcherThread是真正实现这3个方法:Follower副本利用ReplicaFetcherThread线程实时地从Leader副本拉取消息并写入到本地日志,从而实现了与Leader副本之间的同步。
要点:
- doWork方法:拉取线程工作入口方法,联结所有重要的子功能方法,如执行截断操作,获取Leader副本消息以及写入本地日志。
- truncate方法:根据Leader副本返回的位移值和Epoch值执行本地日志的截断操作。
- buildFetch方法:为一组特定分区构建FetchRequest对象所需的数据结构。
- processPartitionData方法:处理从Leader副本获取到的消息,主要是写入到本地日志中。

Follower副本正是利用它来获取对应分区Partition对象的,然后依靠该对象执行消息写入。

- 点赞
- 收藏
- 关注作者
评论(0)