【第3篇】Inception V2

Inception V2
摘要
由于每层输入的分布在训练过程中随着前一层的参数发生变化而发生变化,因此训练深度神经网络很复杂。由于需要较低的学习率和仔细的参数初始化,这会减慢训练速度,并且使得训练具有饱和非线性的模型变得非常困难。我们将这种现象称为内部协变量偏移,并通过归一化层输入来解决该问题。我们的方法的优势在于将标准化作为模型架构的一部分,并为每个训练小批量执行标准化。 Batch Normalization 允许我们使用更高的学习率,并且在初始化时不那么小心。它还充当正则化器,在某些情况下消除了 Dropout 的需要。应用于最先进的图像分类模型,批量归一化在训练步骤减少 14 倍的情况下实现了相同的精度,并且以显着的优势击败了原始模型。使用批量归一化网络的集合,我们改进了 ImageNet 分类的最佳发布结果:达到 4.9% 的 top-5 验证错误(和 4.8% 的测试错误),超过人类评估者的准确性。
1 简介
深度学习极大地提高了视觉、语音和许多其他领域的技术水平。 随机梯度下降 (SGD) 已被证明是训练深度网络的有效方法,并且诸如动量 (Sutskever et al., 2013) 和 Adagrad (Duchi et al., 2011) 等 SGD 变体已被用于实现 艺术表演。 SGD 优化网络的参数 ,从而最小化损失
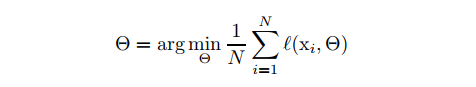
其中 是训练数据集。 使用 SGD,训练分步进行,在每一步我们考虑一个大小为 m 的 minibatch 。 mini-batch 用于近似损失函数相对于参数的梯度,通过计算
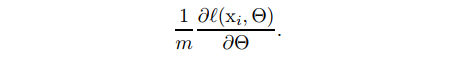
使用小批量的例子,而不是一次一个例子,在几个方面是有帮助的。首先,小批量损失的梯度是对训练集梯度的估计,其质量随着批量大小的增加而提高。其次,由于现代计算平台提供的并行性,批量计算比单个示例的 m 次计算更有效。
虽然随机梯度简单有效,但它需要仔细调整模型超参数,特别是优化中使用的学习率,以及模型参数的初始值。由于每一层的输入受到所有前面层的参数的影响,训练变得复杂——因此网络参数的微小变化会随着网络变得更深而放大。
层输入分布的变化带来了一个问题,因为层需要不断适应新的分布。当学习系统的输入分布发生变化时,据说会经历协变量转移(Shimodaira,2000)。这通常是通过域适应来处理的(Jiang,2008)。然而,协变量移位的概念可以扩展到整个学习系统之外,以应用于其部分,例如子网络或层。考虑网络计算
其中 和 是任意变换,并且要学习参数 、 以最小化损失 。 学习 Θ2 可以看作是将输入 输入到子网络中
例如,梯度下降步骤
(对于批量大小 m 和学习率 α)完全等同于具有输入 x 的独立网络 。 因此,使训练更有效的输入分布特性——例如在训练和测试数据之间具有相同的分布——也适用于训练子网络。 因此,随着时间的推移,x 的分布保持固定是有利的。 然后, 不必重新调整以补偿 x 分布的变化。
子网络输入的固定分布也会对子网络外的层产生积极影响。考虑一个具有 sigmoid 激活函数的层$ z = g(W u + b)$ 其中 u 是层输入,权重矩阵 W 和偏置向量 b 是要学习的层参数,$g(x) =\frac{1}{1+exp( 1-x)} |x|$ 增加,$g’(x) $趋于零。这意味着对于 的所有维度,除了绝对值较小的维度外,向下流向 u 的梯度将消失,模型将缓慢训练。然而,由于 x 受$ W,b$ 和下面所有层的参数的影响,在训练期间对这些参数的更改可能会将 x 的许多维度移动到非线性的饱和区域并减慢收敛速度。随着网络深度的增加,这种效果会被放大。在实践中,饱和问题和由此产生的梯度消失通常通过使用 Rectified Linear Units (Nair & Hinton, 2010) ,仔细初始化 (Bengio & Glorot, 2010; Saxe 等 ., 2013),以及小的学习率。然而,如果我们可以确保非线性输入的分布在网络训练时保持更稳定,那么优化器就不太可能陷入饱和状态,并且训练会加速。
我们将训练过程中深度网络内部节点分布的变化称为内部协变量偏移。消除它提供了更快训练的承诺。我们提出了一种新机制,我们称之为批量归一化,它朝着减少内部协变量偏移迈出了一步,并通过这样做显着加速了深度神经网络的训练。它通过一个归一化步骤来实现这一点,该步骤修复了层输入的均值和方差。通过减少梯度对参数尺度或其初始值的依赖性,批量归一化对通过网络的梯度流也有有益的影响。这使我们能够使用更高的学习率而没有发散的风险。此外,批量归一化使模型正则化并减少了对 Dropout 的需求(Srivastava 等,2014)。最后,批量归一化通过防止网络陷入饱和模式,使使用饱和非线性成为可能。
在第 4.2 节中,我们将批量归一化应用于性能最佳的 ImageNet 分类网络,并表明我们仅使用 7% 的训练步骤就可以匹配其性能,并且可以进一步大大超过其准确性。 使用通过批量归一化训练的此类网络的集合,我们实现了前 5 名错误率,该错误率改进了 ImageNet 分类的最佳已知结果。
2 减少内部协变量偏移
我们将内部协变量偏移定义为由于训练期间网络参数的变化而导致的网络激活分布的变化。 为了改进训练,我们寻求减少内部协变量偏移。 随着训练的进行,通过固定层输入 x 的分布,我们期望提高训练速度。 众所周知(LeCun 等, 1998b; Wiesler & Ney, 2011)如果输入被白化,网络训练收敛得更快——即线性变换为零均值和单位方差,并且去相关。 由于每一层都观察由下面的层产生的输入,因此对每一层的输入实现相同的白化将是有利的。 通过对每一层的输入进行白化,我们将朝着实现输入的固定分布迈出一步,从而消除内部协变量移位的不良影响。
我们可以在每个训练步骤或某个时间间隔考虑白化激活,通过直接修改网络或通过改变优化算法的参数以取决于网络激活值(Wiesler 等人,2014 年;Raiko 等人,2012 年) ;Povey 等人,2014 年;Desjardins 和 Kavukcuoglu)。但是,如果这些修改穿插在优化步骤中,那么梯度下降步骤可能会尝试以需要更新归一化的方式更新参数,这会降低梯度步骤的影响。例如,考虑一个输入 u 的层,它添加了学习偏差 b,并通过减去在训练数据上计算的激活的平均值来标准化结果: 其中 , $\chi =\left { x_{1 \cdots N }\right } $是训练集上的 x 值的集合,并且 。如果梯度下降步骤忽略了$ E[x]$ 对 b 的依赖性,那么它将更新 ,其中 。然后 。因此,对 b 的更新和随后的归一化变化相结合,不会导致层的输出发生变化,也不会导致损失。随着训练的继续,b 将无限增长,而损失保持不变。如果归一化不仅集中而且缩放激活,这个问题会变得更糟。我们在初始实验中凭经验观察到这一点,当在梯度下降步骤之外计算归一化参数时,模型会崩溃。
上述方法的问题在于梯度下降优化没有考虑归一化发生的事实。 为了解决这个问题,我们希望确保对于任何参数值,网络总是产生具有所需分布的激活。 这样做将允许损失相对于模型参数的梯度解释归一化及其对模型参数 Θ 的依赖性。 再次让 x 是一个层输入,被视为一个向量,而 X 是这些输入在训练数据集上的集合。 然后可以将规范化写为转换
这不仅取决于给定的训练示例 x,还取决于所有示例 如果 x 是由另一层生成的,则每个示例都取决于 Θ。 对于反向传播,我们需要计算雅可比矩阵
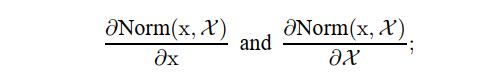
忽略后一项将导致上述爆炸。在这个框架内,白化层输入是昂贵的,因为它需要计算协方差矩阵 $Cov[x] = E_{x∈X} [xx^{T} ] − E[x]E[x]^{T} Cov[x]^{−1/2}(x − E[x])$,以及这些反向传播变换的导数。这促使我们寻找一种替代方法,以可微的方式执行输入归一化,并且不需要在每次参数更新后分析整个训练集。
之前的一些方法(例如 (Lyu & Simoncelli, 2008))使用在单个训练示例上计算的统计数据,或者在图像网络的情况下,使用给定位置的不同特征图计算的统计数据。然而,这通过丢弃激活的绝对规模改变了网络的表示能力。我们希望通过相对于整个训练数据的统计对训练示例中的激活进行归一化来保留网络中的信息。
3 通过小批量统计进行归一化
由于每层输入的完全白化代价高昂且并非处处可微,因此我们进行了两个必要的简化。 第一个是,不是联合白化层输入和输出中的特征,我们将独立地标准化每个标量特征,通过使其具有零均值和 1 方差。对于具有 d 维输入$ x = (x^{ (1)} . . . x^{(d)})$,我们将对每个维度进行归一化
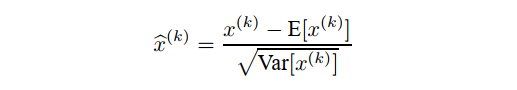
其中期望和方差是在训练数据集上计算的。 如 (LeCun等, 1998b) 所示,即使特征没有去相关,这种归一化也会加速收敛。
请注意,简单地对层的每个输入进行归一化可能会改变层可以表示的内容。 例如,对 sigmoid 的输入进行归一化会将它们限制在非线性的线性范围内。 为了解决这个问题,我们确保插入到网络中的变换可以代表身份变换。 为了实现这一点,我们为每个激活$ x^{(k)}$ 引入了一对参数 ,它们对归一化值进行缩放和移动:
这些参数与原始模型参数一起学习,并恢复网络的表示能力。 实际上,通过设置$ \gamma ^{(k)}=\sqrt{Var[x^{(k)}]} $和 ,我们可以恢复原始激活,如果这是最佳选择的话。
在批处理设置中,每个训练步骤都基于整个训练集,我们将使用整个集来规范化激活。 然而,这在使用随机优化时是不切实际的。 因此,我们进行第二次简化:由于我们在随机梯度训练中使用小批量,每个小批量产生每个激活的均值和方差的估计值。 这样,用于归一化的统计量就可以完全参与梯度反向传播。 请注意,小批量的使用是通过计算每维方差而不是联合协方差来实现的; 在联合情况下,由于小批量大小可能小于被白化的激活数量,因此需要正则化,从而导致奇异的协方差矩阵。
考虑大小为 m 的小批量$ B $。 由于归一化独立地应用于每个激活,让我们关注特定的激活 并为清楚起见省略 k。 我们在小批量中有 m 个此激活值,
设归一化值为 ,它们的线性变换为 。 我们参考变换
作为批量归一化变换。 我们在算法 1 中介绍了 BN 变换。在算法中,ǫ 是添加到小批量方差的常数,以确保数值稳定性。

BN 变换可以添加到网络中以操纵任何激活。在符号 中,我们表示要学习参数 和$ β BN_{γ,β^{(x)}}$取决于训练示例和小批量中的其他示例。缩放和移动的值 y 被传递到其他网络层。归一化激活 是我们转换的内部,但它们的存在至关重要。只要每个 mini-batch 的元素都从相同的分布中采样,并且如果我们忽略 ,则任何 值的分布的期望值为 0 和方差为 1。这可以通过观察 和 并取期望值看出。每个归一化的激活 可以看作是一个子网络的输入,该子网络由线性变换 组成,然后是由原始网络。这些子网络输入都有固定的均值和方差,虽然这些归一化 的联合分布会在训练过程中发生变化,但我们预计归一化输入的引入会加速子网络以及整个网络的训练。
在训练期间,我们需要通过这个变换来反向传播损失 的梯度,并计算关于 BN 变换参数的梯度。 我们使用链式法则,如下(化简前):
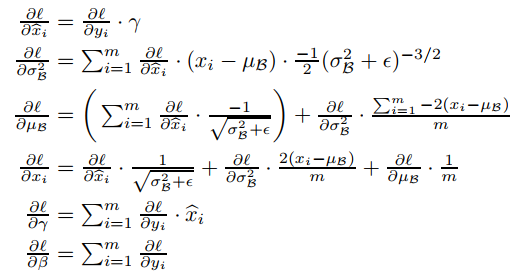
因此,BN 变换是一种将归一化激活引入网络的可微变换。 这确保在模型训练时,层可以继续学习表现出较少内部协变量偏移的输入分布,从而加速训练。 此外,应用于这些归一化激活的学习仿射变换允许 BN 变换表示身份变换并保留网络容量。
3.1 使用 BatchNormalized 网络进行训练和推理
根据 Alg.1,为了对网络进行批量标准化,我们指定了一个激活子集并为每个激活插入了 BN 变换。 任何先前接收 x 作为输入的层,现在接收 BN(x)。 可以使用批量梯度下降或小批量大小 m > 1 的随机梯度下降或其任何变体例如 Adagrad(Duchi 等人,2011)来训练采用批量归一化的模型。 依赖于小批量的激活标准化允许有效的训练,但在推理过程中既不必要也不可取; 我们希望输出仅依赖于输入,确定性地。 为此,一旦网络经过训练,我们使用归一化
使用population(英文翻译是人口,很奇怪)统计,而不是小批量统计。 忽略 ǫ,这些归一化激活具有与训练期间相同的均值 0 和方差 1。 我们使用无偏方差估计
,其中期望值超过训练大小为 m 的小批量,
是它们的样本方差。 使用移动平均线,我们可以在模型训练时跟踪模型的准确性。 由于在推理过程中均值和方差是固定的,因此归一化只是应用于每个激活的线性变换。 它可以进一步与按
的缩放和按
的移位组成,以产生替换 BN(x) 的单个线性变换。 Algorithm 2 总结了训练批量归一化网络的过程。 
3.2 批量归一化卷积网络
批量标准化可以应用于网络中的任何一组激活。 在这里,我们关注由仿射变换和元素级非线性组成的变换:
其中 W 和 b 是模型的学习参数,g(·) 是非线性,例如 sigmoid 或 ReLU。 该公式涵盖了全连接层和卷积层。 我们通过归一化 在非线性之前立即添加 BN 变换。 我们也可以对层输入 u 进行归一化,但由于 u 可能是另一个非线性的输出,其分布的形状可能会在训练期间发生变化,并且限制其一阶和二阶矩不会消除协变量偏移。 相比之下, 更可能具有对称的非稀疏分布,即“更高的高斯分布”(Hyvarinen & Oja, 2000); 归一化它可能会产生具有稳定分布的激活。
请注意,由于我们对 进行了归一化,因此可以忽略偏差 b,因为它的影响将被随后的均值减法抵消(偏差的作用由 Alg.1 中的 β 包含)。 因此, 被替换为 :
其中 BN 变换独立应用于 的每个维度,每个维度有一对单独的学习参数 。
对于卷积层,我们还希望归一化遵循卷积特性——以便同一特征图的不同元素在不同位置以相同的方式归一化。 为了实现这一点,我们在所有位置上共同标准化小批量中的所有激活。 在 Alg.1 中,我们让 B 是小批量元素和空间位置的特征图中所有值的集合——因此对于大小为 m 的小批量和大小为 的特征图,我们 使用大小为 m’ 的有效小批量 。 我们为每个特征图而不是每个激活学习一对参数 。 算法 2 进行了类似的修改,因此在推理过程中,BN 变换对给定特征图中的每个激活应用相同的线性变换。
3.3 批量标准化可实现更高的学习率
在传统的深度网络中,过高的学习率可能会导致梯度爆炸或消失,以及陷入较差的局部最小值。 批量标准化有助于解决这些问题。 通过对整个网络的激活进行归一化,它可以防止参数的微小变化放大为梯度激活的较大和次优变化; 例如,它可以防止训练陷入非线性的饱和状态。
批量归一化还使训练对参数规模更具弹性。 通常,较大的学习率可能会增加层参数的规模,从而在反向传播过程中放大梯度并导致模型爆炸。 然而,使用批量归一化,通过层的反向传播不受其参数规模的影响。 实际上,对于标量 a,
我们可以证明
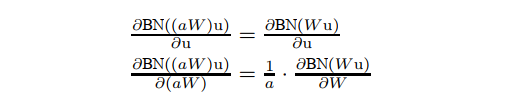
尺度不影响层Jacobian ,因此也不影响梯度传播。 此外,较大的权重会导致较小的梯度,而 Batch Normalization 将稳定参数增长 。
我们进一步推测 Batch Normalization 可能会导致层 Jacobian 具有接近 1 的奇异值,这对训练有益(Saxe 等人,2013 年)。 考虑具有归一化输入的两个连续层,以及这些归一化向量之间的转换: 。 如果我们假设 和 是高斯且不相关的,并且 $F (\hat{x}) ≈ J\hat{x} $是给定模型参数的线性变换,那么 和 都有单位协方差,并且 。 因此, ,因此 J 的所有奇异值都等于 1,这在反向传播期间保留了梯度幅度。 实际上,变换不是线性的,并且不能保证归一化值是高斯或独立的,但我们仍然希望批量归一化有助于使梯度传播表现得更好。 批量归一化对梯度传播的精确影响仍然是进一步研究的领域。
3.4 Batch Normalization 正则化模型
使用批量归一化进行训练时,会看到一个训练示例与小批量中的其他示例相结合,并且训练网络不再为给定的训练示例生成确定性值。 在我们的实验中,我们发现这种效果有利于网络的泛化。 Dropout (Srivastava 等, 2014) 通常用于减少过拟合,而在批量归一化网络中,我们发现它可以被移除或降低强度。
4 实验
4.1 随着时间的推移激活
为了验证内部协变量偏移对训练的影响,以及批量归一化对抗它的能力,我们考虑了在 MNIST 数据集上预测数字类别的问题(LeCun 等人,1998a)。 我们使用了一个非常简单的网络,以 28x28 的二进制图像作为输入,以及 3 个全连接的隐藏层,每个隐藏层有 100 个激活。 每个隐藏层计算 y = g(W u+b) 与 sigmoid 非线性,权重 W 初始化为小的随机高斯值。 最后一个隐藏层之后是具有 10 个激活(每个类一个)和交叉熵损失的全连接层。 我们对网络进行了 50000 步的训练,每个小批量有 60 个示例。 我们向网络的每个隐藏层添加了批量归一化,如第 3.1 节所示。 我们对基线和批量归一化网络之间的比较感兴趣,而不是在 MNIST 上实现最先进的性能(所描述的架构没有)。

图 1(a) 显示了随着训练的进行,两个网络对保留测试数据的正确预测的比例。 批量归一化网络具有更高的测试精度。 为了研究原因,我们在训练过程中研究了原始网络 N 和批量归一化网络 Ntr BN(Alg. 2)中 sigmoid 的输入。 在图 1(b,c) 中,我们展示了每个网络最后一个隐藏层的一个典型激活,其分布如何演变。 原始网络中的分布随时间显着变化,包括均值和方差,这使后续层的训练复杂化。 相比之下,随着训练的进行,批量归一化网络中的分布更加稳定,这有助于训练。
4.2 ImageNet 分类
我们将批量归一化应用于 Inception 网络的一个新变体(Szegedy 等人,2014 年),在 ImageNet 分类任务上进行了训练(Russakovsky 等人,2014 年)。该网络有大量的卷积层和池化层,有一个 softmax 层来预测图像类别,有 1000 种可能性。卷积层使用 ReLU 作为非线性。与 (Szegedy et al., 2014) 中描述的网络的主要区别在于,5 × 5 卷积层被两个连续的 3 × 3 卷积层替换,最多 128 个滤波器。该网络包含 个参数,除最顶层的 softmax 层外,没有全连接层。附录中提供了更多详细信息。我们在本文的其余部分将此模型称为 Inception。该模型使用具有动量的 Stochastic Gradient Descent (Sutskever et al., 2013) 版本进行训练,使用 mini-batch 大小为 32。使用大规模分布式架构进行训练(类似于(Dean et al., 2012))。随着训练的进行,所有网络都通过计算验证准确度@1 进行评估,即在保留的集合上,使用每个图像的单个裁剪,从 1000 种可能性中预测正确标签的概率。
在我们的实验中,我们使用批量标准化评估了 Inception 的几种修改。 在所有情况下,批量归一化以卷积方式应用于每个非线性的输入,如第 3.2 节所述,同时保持架构的其余部分不变。
4.2.1 加速BN网络
简单地将批量归一化添加到网络并不能充分利用我们的方法。 为此,我们进一步更改了网络及其训练参数,如下所示:
提高学习率。 在批量归一化模型中,我们已经能够通过更高的学习率实现训练加速,并且没有不良副作用(第 3.3 节)。
删除Dropout。 如第 3.4 节所述,批量归一化实现了与 Dropout 相同的一些目标。 从 Modified BN-Inception 中删除 Dropout 可以加快训练速度,同时不会增加过拟合。
减少 L2 权重正则化。 在 Inception 中,模型参数上的 L2 损失控制了过度拟合,而在 Modified BN-Inception 中,此损失的权重降低了 5 倍。我们发现这提高了保留验证数据的准确性。
加速学习率衰减。 在训练初始阶段,学习率呈指数衰减。 因为我们的网络训练速度比 Inception 快,所以我们将学习率降低了 6 倍。
删除局部响应归一化 虽然 Inception 和其他网络(Srivastava 等人,2014)从中受益,但我们发现批量归一化没有必要。
更彻底地洗牌训练。 我们启用了训练数据的分片内改组,这可以防止相同的示例总是一起出现在小批量中。 这导致验证准确度提高了约 1%,这与将批标准化作为正则化器的观点一致(第 3.4 节): 我们方法中固有的随机化应该是最有益的,因为它在每次看到一个例子时都会有不同的影响。
减少光度失真。 由于批量归一化网络训练速度更快并且观察每个训练示例的次数更少,我们让训练器通过减少扭曲来专注于更多“真实”图像。
4.2.2 单一网络分类
我们评估了以下网络,均在 LSVRC2012 训练数据上训练,并在验证数据上进行测试:
Inception:4.2 节开头描述的网络,以 0.0015 的初始学习率进行训练。
BN-Baseline:与 Inception 相同,在每个非线性之前使用 Batch Normalization。
BN-x5:批量标准化的开始和第 4.2.1 节中的修改。初始学习率增加了 5 倍,达到 0.0075。与原始 Inception 相同的学习率增加导致模型参数达到机器无穷大。
BN-x30:类似于 BN-x5,但初始学习率为 0.045(是 Inception 的 30 倍)。
BN-x5-Sigmoid:与 BN-x5 类似,但具有 sigmoid 非线性 而不是 ReLU。我们还尝试用 sigmoid 训练原始的 Inception,但模型仍然保持与机会相当的准确度。
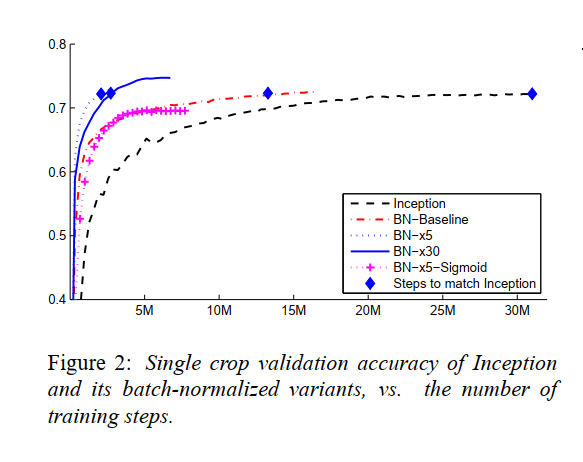
在图 2 中,我们显示了网络的验证准确性,作为训练步骤数的函数。 Inception 在 个训练步骤后达到了 72.2% 的准确率。 图 3 显示了对于每个网络,达到相同 72.2% 准确度所需的训练步骤数,以及网络达到的最大验证准确度和达到该准确度的步骤数。
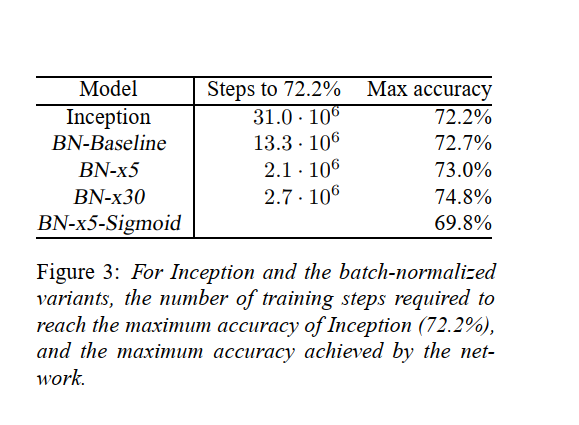
通过仅使用批量归一化 (BN-Baseline),我们以不到一半的训练步骤数来匹配 Inception 的准确性。 通过应用第 4.2.1 节中的修改,我们显着提高了网络的训练速度。 BN-x5 需要比 Inception 少 14 倍的步骤才能达到 72.2% 的准确率。 有趣的是,进一步提高学习率 (BN-x30) 会导致模型最初的训练速度稍慢,但可以达到更高的最终精度。 在 步后达到 74.8%,即比 Inception 达到 72.2% 所需的步数少 5 倍。
我们还验证了内部协变量偏移的减少允许在使用 sigmoid 作为非线性时训练具有批量归一化的深度网络,尽管训练此类网络存在众所周知的困难。 事实上,BN-x5-Sigmoid 达到了 69.8% 的准确率。 如果没有批量归一化,使用 sigmoid 的 Inception 永远不会达到超过 1/1000 的准确度。
4.2.3 集成分类
目前在 ImageNet 大规模视觉识别竞赛中报告的最佳结果是由传统模型的 Deep Image 集成 (Wu et al., 2015) 和 (He et al., 2015) 的集成模型实现的。根据 ILSVRC 服务器的评估,后者报告了 4.94% 的前 5 名错误。在这里,我们报告了 4.9% 的 top-5 验证错误和 4.82% 的测试错误(根据 ILSVRC 服务器)。这改进了之前的最佳结果,并超过了人类评估者根据 (Russakovsky et al., 2014) 估计的准确度。
对于我们的集成,我们使用了 6 个网络。每个都基于 BN-x30,通过以下一些修改:增加卷积层中的初始权重;使用 Dropout(Dropout 概率为 5% 或 10%,而原始 Inception 为 40%);并使用模型的最后隐藏层的非卷积、按激活批量归一化。每个网络在大约 个训练步骤后达到其最大精度。集成预测基于组成网络预测的类概率的算术平均值。集成和多作物推理的细节类似于(Szegedy 等,2014)。
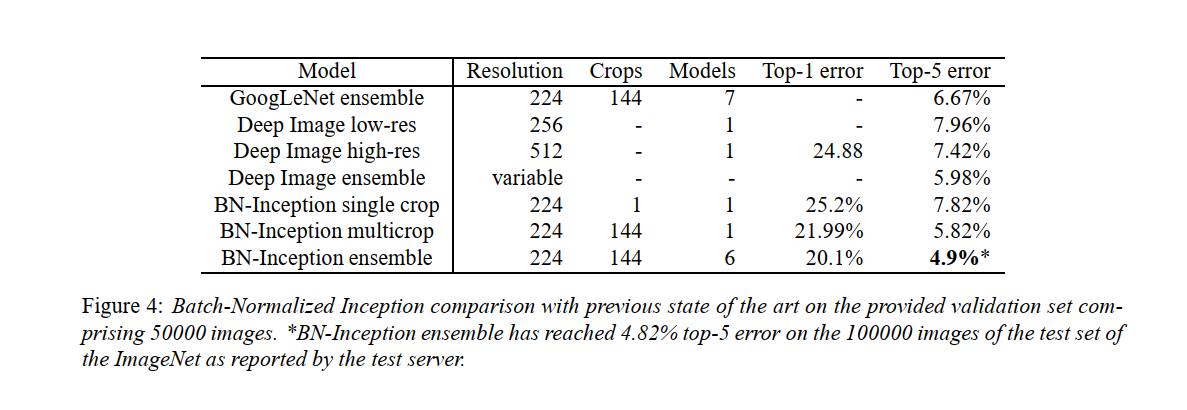
我们在图 4 中证明,批量归一化允许我们在 ImageNet 分类挑战基准上以健康的差距设置新的最新技术。
5 结论
我们提出了一种显着加速深度网络训练的新机制。它基于这样一个前提,众所周知,协变量偏移会使机器学习系统的训练复杂化,也适用于子网络和层,并且将其从网络的内部激活中移除可能有助于训练。我们提出的方法从规范化激活中汲取力量,并将这种规范化纳入网络架构本身。这确保了用于训练网络的任何优化方法都能适当地处理归一化。为了启用深度网络训练中常用的随机优化方法,我们对每个小批量执行归一化,并通过归一化参数反向传播梯度。 Batch Normalization 每次激活只添加两个额外的参数,这样做可以保留网络的表示能力。我们提出了一种使用批量归一化网络构建、训练和执行推理的算法。由此产生的网络可以用饱和非线性进行训练,更能容忍增加的训练率,并且通常不需要 Dropout 进行正则化。
仅将批量归一化添加到最先进的图像分类模型中就可以显着加快训练速度。 通过进一步提高学习率、去除 Dropout 并应用批标准化提供的其他修改,我们仅用一小部分训练步骤就达到了之前的最先进技术——然后在单网络图像分类中击败了最先进技术 . 此外,通过结合使用 Batch Normalization 训练的多个模型,我们在 ImageNet 上的表现明显优于最著名的系统。
有趣的是,我们的方法与 (Gulc¸ehre & Bengio, 2013) 的标准化层相似,尽管这两种方法源于非常不同的目标,并执行不同的任务。 Batch Normalization 的目标是在整个训练过程中实现激活值的稳定分布,在我们的实验中,我们将其应用在非线性之前,因为这是匹配一阶和二阶矩的地方更有可能导致稳定的分布。相反,(Gulc¸ehre & Bengio, 2013) 将标准化层应用于非线性的输出,这会导致更稀疏的激活。在我们的大规模图像分类实验中,我们没有观察到非线性输入是稀疏的,无论有没有批量归一化。 Batch Normalization 的其他显着区别特征包括允许 BN 变换表示身份的学习尺度和移位(标准化层不需要这样做,因为它后面是学习线性变换,从概念上讲,它吸收了必要的尺度和移位),处理卷积层,不依赖于小批量的确定性推理,以及对网络中的每个卷积层进行批量归一化。
在这项工作中,我们没有探索批量标准化可能实现的所有可能性。 我们未来的工作包括将我们的方法应用于循环神经网络 (Pascanu et al., 2013),其中内部协变量偏移和消失或爆炸梯度可能特别严重,这将使我们能够更彻底地测试归一化的假设 改进梯度传播(第 3.3 节)。 我们计划调查批量归一化是否可以帮助传统意义上的域适应——即网络执行的归一化是否能让它更容易地泛化到新的数据分布,也许只需要重新计算总体均值和方差( 算法 2)。 最后,我们相信对该算法的进一步理论分析将允许更多的改进和应用。
包括将我们的方法应用于循环神经网络 (Pascanu et al., 2013),其中内部协变量偏移和消失或爆炸梯度可能特别严重,这将使我们能够更彻底地测试归一化的假设 改进梯度传播(第 3.3 节)。 我们计划调查批量归一化是否可以帮助传统意义上的域适应——即网络执行的归一化是否能让它更容易地泛化到新的数据分布,也许只需要重新计算总体均值和方差( 算法 2)。 最后,我们相信对该算法的进一步理论分析将允许更多的改进和应用。

- 点赞
- 收藏
- 关注作者
评论(0)