NEON 指令集并行技术优化矩阵转置【Android】

【摘要】
核心代码如下:转置一个 4*4的矩阵,更大的矩阵(不能被4整除的需要特殊处理边界)都可以通过分块来进行转置
void transpose32x4x4(float32x4_t *q0, float32x4_t *q1, float32x4_t *q2, float32x4_t *q3) { // ---------...
核心代码如下:转置一个 4*4的矩阵,更大的矩阵(不能被4整除的需要特殊处理边界)都可以通过分块来进行转置
-
void transpose32x4x4(float32x4_t *q0, float32x4_t *q1, float32x4_t *q2, float32x4_t *q3) {
-
// ----------------------------------------------
-
float32x4x2_t q01 = vtrnq_f32(*q0, *q1);
-
float32x4x2_t q23 = vtrnq_f32(*q2, *q3);
-
-
float32x4_t qq0 = q01.val[0];
-
float32x2_t d00 = vget_low_f32(qq0);
-
float32x2_t d01 = vget_high_f32(qq0);
-
-
float32x4_t qq1 = q01.val[1];
-
float32x2_t d10 = vget_low_f32(qq1);
-
float32x2_t d11 = vget_high_f32(qq1);
-
-
float32x4_t qq2 = q23.val[0];
-
float32x2_t d20 = vget_low_f32(qq2);
-
float32x2_t d21 = vget_high_f32(qq2);
-
-
float32x4_t qq3 = q23.val[1];
-
float32x2_t d30 = vget_low_f32(qq3);
-
float32x2_t d31 = vget_high_f32(qq3);
-
-
*q0 = vcombine_f32(d00, d20);
-
*q1 = vcombine_f32(d10, d30);
-
*q2 = vcombine_f32(d01, d21);
-
*q3 = vcombine_f32(d11, d31);
-
// ----------------------------------------------
-
}
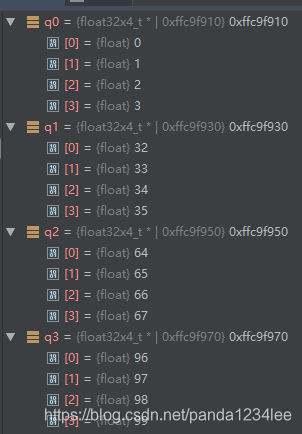
q0-q3 在内存中的初始值如下图所示
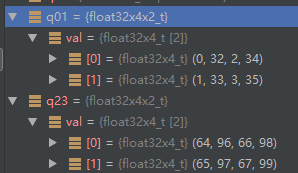
经过 vtrn 操作后的结果为:
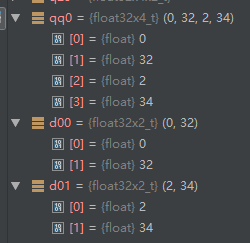
取低位和高位的结果为:
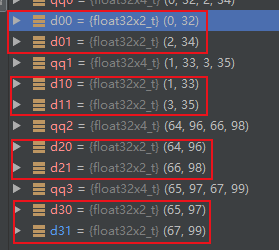
注意原始的4*4矩阵是
| 0 | 1 | 2 | 3 |
| 32 | 33 | 34 | 35 |
| 64 | 65 | 66 | 67 |
| 96 | 97 | 98 | 99 |
转置后应该为
| 0 | 32 | 64 | 96 |
| 1 | 33 | 65 | 97 |
| 2 | 34 | 66 | 98 |
| 3 | 35 | 67 | 99 |
所以,应该把 d00 和 d20 结合在一起,其他同理
最后验证一下转置的结果
-
int ret = 0;
-
for(int i = 0; i<COLS; i++)
-
{
-
for(int j = 0; j<ROWS; j++)
-
{
-
ret = src[j*COLS + i] == dst[i*ROWS + j];
-
if(!ret)
-
{
-
LOGE("src[%d] != dst[%d] \t", j*COLS + i, i*ROWS + j);
-
break;
-
}
-
}
-
}
-
-
if(ret)
-
LOGE("Tranpose Correctly !\t");
如图所示,转置验证是正确的
![]()
1024*1024大小的矩阵, 大约提升了 42.7% 的性能

文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/85222973

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)