L0 范数图像平滑(L0 Smooth) 的原理和 GPU 加速【CUDA】

一、概述
原作者提出了一种新的图像编辑方法,通过增加过渡的陡峭度,同时消除了一个低振幅结构的可管理程度,特别有效地锐化主要边缘。这种看似矛盾的效果是在一个利用 L0 梯度最小化的优化框架中实现的,它可以全局控制产生多少个非零梯度,以一种稀疏控制的方式近似出显著的结构。与其他边缘保持平滑方法不同,原作者的方法不依赖于局部特征,而是全局定位重要的边缘。它作为一种基本的工具,有许多应用场景,尤其有利于边缘提取、剪贴画JPEG伪影去除和非真实感效果的生成。
原作者的目标是在不影响整体锐度的情况下,通过增加过渡的陡度,在全局范围内保持并尽可能增强最显著的边缘集合。在算法上,原作者提出了一种基于优化框架的稀疏梯度计数方法。其主要贡献是提出了一种限制相邻像素间强度变化离散个数的新策略,该策略在数学上与 L0 范数相关,用于信息稀疏性的跟踪。作者认为他们的方法在性质上的效果是使显著边缘变薄,使其更容易被检测到,视觉上更清晰。与颜色量化和分割效果不同的是,使用作者的方法增强后的边缘与原始边缘基本一致。即使是小分辨率的对象和细边,如果它们在结构上引人注目,也可以忠实地保留下来。
在应用方面,作者认为该框架是通用的,他们将其应用于压缩伪影退化的剪贴画的恢复,声称在大量实验中可以得到高质量的结果。作者还声称他们的方法可以通过有效地去除部分噪声、不重要的细节,甚至是轻微的模糊,使得“边缘提取”这一非常基础而又重要的操作受益;同时,经过平滑的结果可以立即用于图像抽象和铅笔素描的特效制作上。
二、核心算法(一维)
作者通过限制非零梯度的数量来增强对比度最高的边缘,同时以全局方式实现平滑。首先,用 g 表示输入的离散信号,用 f 表示它的平滑结果。作者的方法是离散地计算振幅的变化,记为

其中 p 和 p + 1 索引邻近的样本(或像素)。 是关于 p 的前向差分形式的梯度。# { } 是计数操作符,输出 p 的数量满足,即 L0 范数的梯度。 不依赖梯度大小,因此如果一条边只改变其对比度,则不会受其影响。这个离散计数函数是我们方法的核心。
但是仅使用度量 是无效的。在作者的方法中,将其与一个一般的约束结合起来——即,结果 f 在结构上应该与输入信号 g 相似——因此作者把具体的目标函数表示为
表示结果中存在 k 个非零梯度,。在该目标函数的约束下,整体形状与原始形状保持一致,因为强度变化必须沿显著边缘出现,以尽可能减少总能量。显然,把边缘放在其他地方只会增加(目标函数的)成本。这种平滑效果明显不同于以往的边缘保持方法。k 越大,得到的近似值越小,但仍然是最显著的对比度。
在实际应用中,目标函数中的 k 值可能在数万到数千之间,特别是在不同分辨率的二维图像中。为了控制它,作者认为应该采用一般形式,在结构扁平化和保持结果与输入的相似性之间寻求平衡,并将其写成如下形式:
作为直接控制 重要性的权重,实际上是一个平滑参数, 越大,边缘就越少。
三、推广到二维
在二维图像表示中,用 I 表示输入图像,用 S 表示计算结果。梯度 表示对于每个像素 p 计算其相邻像素之间在 x 和 y 方向上的差分。
梯度的度量表示为:
它计算了 p 的幅值 不为零的个数。
根据这个定义,S便可通过下式求解得到
在实际计算中,彩色图像的梯度大小|∂Sp |被定义为梯度大小在rgb三个通道的总和。
四、目标函数的求解
由于新的目标函数涉及一个离散的计数度量。左右两项分别对像素差和全局不连续进行了统计建模,因此难以求解。传统的梯度下降法或其它离散优化方法都不可用。因此作者基于引入辅助变量的思想,采用一种特殊的半二次分裂交替优化策略,对原始项进行扩展和迭代更新(其思想有点像 EM 算法,分两步走,走一步看一步,交替验证优化的过程)。具体求解过程请参看原论文。
其伪代码如下:

五、具体应用场景
1)边缘的提升和提取(Edge Enhancement and Extraction)


2) 图像的抽象和铅笔画特效(Image Abstraction and Pencil Sketching)

3) 剪贴画瑕疵的修复(Clip-Art Compresion Artificat Removal)


4) 细节放大(Detail Magnification)

5)色调映射(Tone Mapping)

六、对比实验的结果
测试图片为 640*640 的下图:

基于原始的 OpenCV 的实现,执行时间为:
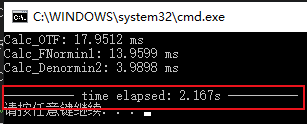
Github 上错误的 CUDA 实现(在 beta_max = 1e5 的条件下):

根据作者论文和其 Matlab 代码,以及 OpenCV 代码,我通过 CUDA 重新实现了 L0 Smooth 算法,结果如下:
时间从 2167ms -> 400ms,性能提升了 5.4 倍 !【我的笔记本显卡是 GTX970M,古老的 maxwell 架构】

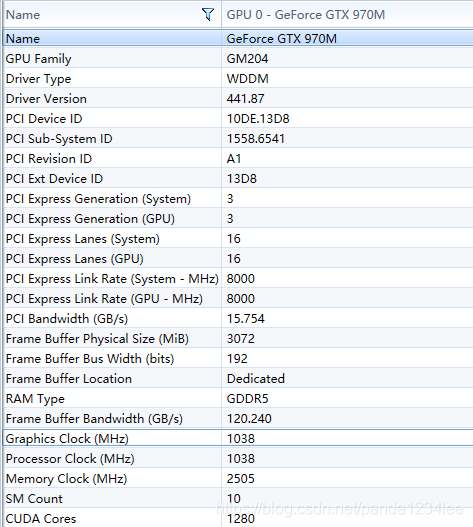 GPU 参数
GPU 参数
以上是初步的实现,性能经过进一步优化之后,总耗时减少到 139.6ms(不包括从磁盘读取图片的时间和开辟内存的时间【多张图像可以重复利用】、 host <-> device 之间的拷贝时间、显示时间)

ps: 谢绝白嫖
文章来源: panda1234lee.blog.csdn.net,作者:panda1234lee,版权归原作者所有,如需转载,请联系作者。
原文链接:panda1234lee.blog.csdn.net/article/details/87868483

- 点赞
- 收藏
- 关注作者
评论(0)