Kubernetes API server工作原理

作为Kubernetes的使用者,每天用得最多的命令就是kubectl XXX了。
kubectl其实就是一个控制台,主要提供的功能:
1. 提供Kubernetes集群管理的REST API接口,包括认证授权、数据校验以及集群状态变更;
2. 提供其他模块之间的数据交互和通信的枢纽(其他模块通过API Server查询或修改数据,只有API Server才直接操作etcd)
也就是说,我们在终端里输入的每个kubectl命令,实际上都是一个发往Kubernetes API server的Restful API调用。
我们可以做个实验:
kubectl get secret -v=9, 通过-v=9设置最高级别的trace:
从输出观察到为了取回所有的secret而进行的API server的调用url:https://xxxx/api/v1/namespaces/<own namespace>/secrets?limit=500:
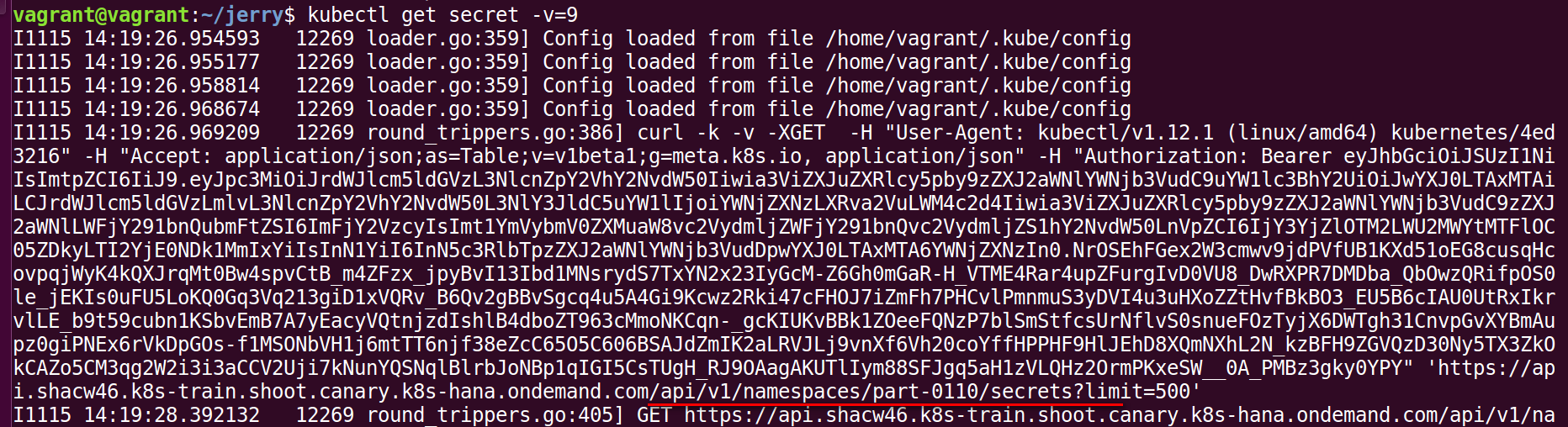
这个HTTP请求的格式在Kubernetes官网能查到。
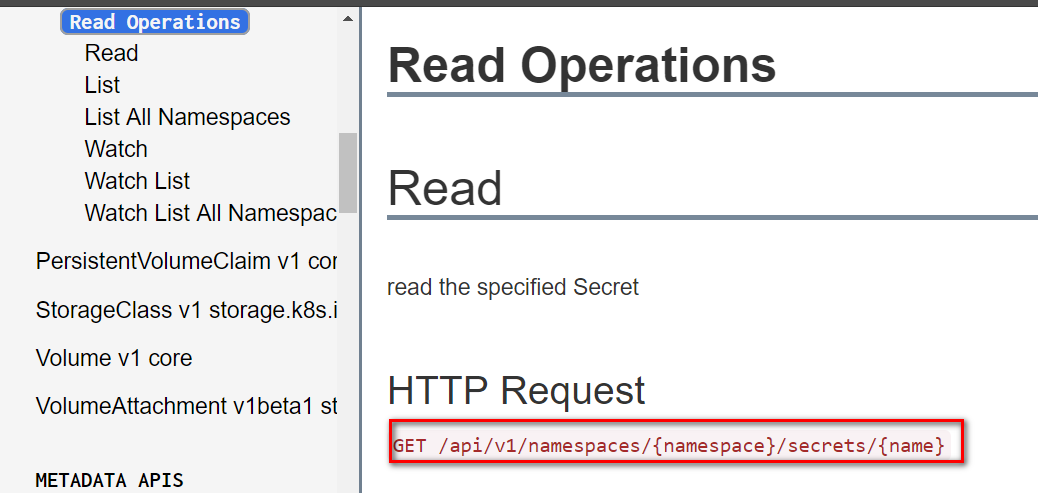
那么kubectl命令怎么知道应该把请求发送到哪个API server呢?
实行命令kubectl config view, 显示内容里的server:后面的地址就是API server的url。

kubectl config view显示的内容来自配置文件: ~/.kube/config:
其实Kubernetes的kubectl工作原理和CloudFoundry的命令行工具cf一样。
设置操作系统的环境变量CF_TRACE = true
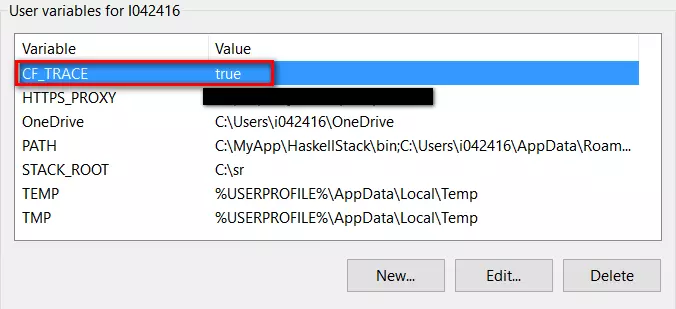
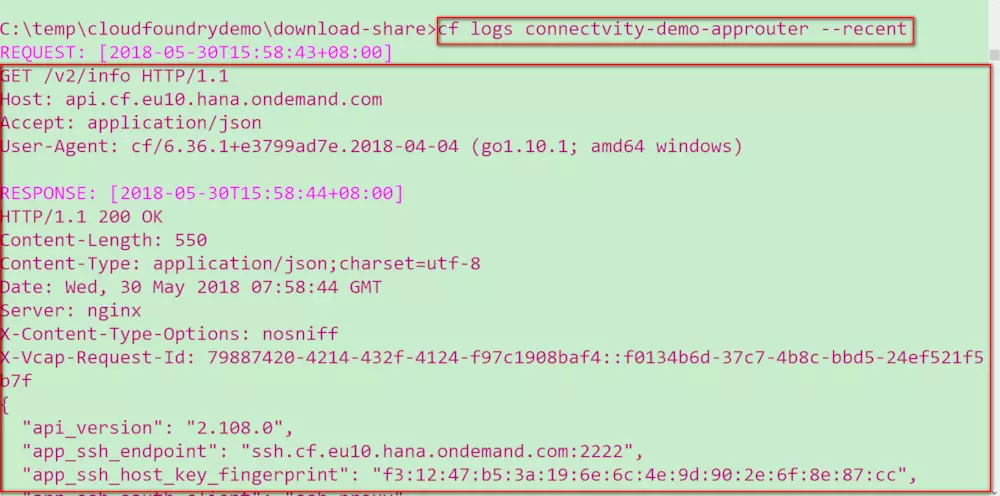
然后执行任意的cf 命令,能看到这些命令实际上也是发送一个HTTP请求到SAP Cloud Platform的某个endpoint上。
例子:cf logs connectvity-demo-approuter --recent
然后就能看到为了完成这个命令所发送的HTTP请求和响应的负载。
创建一个类型为NetworkPolicy的Kubernetes对象的yaml文件。
第九行的podSelector指定这个NetworkPolicy施加在哪些pod上,通过label来做pod的过滤。

从第16行开始的ingress定义,定义了只有具备标签component=ads,module=app的pod才能够连接component=ads, module=db的pod。
首先创建一个临时的pod,使用正确的label(component=ads,module=app)去访问db pod:
kubectl run --restart=Never -it --rm --image=postgres:9.6 --labels=“component=ads,module=app” --env=“PGCONNECT_TIMEOUT=5” helper --command – /bin/bash
执行完毕后看到提示root@helper:/#, 说明我通过上述命令创建的临时pod成功的连接到了postgreSQL的pod上。

输入正确的用户名和密码,能成功连接到postgreSQL pod提供的数据库服务上。

现在我们重新创建一个临时pod,不指定label,因此不满足NetworkPolicy里定义的限制条件,因此会看到我们期望的结果:postgreSQL连接失败。

希望通过例子大家能够理解Kubernetes里NetworkPolicy的工作原理。

- 点赞
- 收藏
- 关注作者
评论(0)