NAM:基于标准化的注意力模块

论文地址:https://arxiv.org/abs/2111.12419
Github:https://github.com/Christian-lyc/NAM

摘要
识别不太显着的特征是模型压缩的关键。 然而,它尚未在革命性的注意力机制中进行研究。 在这项工作中,我们提出了一种新颖的基于归一化的注意力模块(NAM),它抑制了不太显着的权重。 它将权重稀疏惩罚应用于注意力模块,从而使它们在保持相似性能的同时具有更高的计算效率。 与 Resnet 和 Mobilenet 上的其他三种注意力机制的比较表明,我们的方法具有更高的准确性。 本文的代码可以在 https://github.com/Christian-lyc/NAM 公开访问。
1 简介
注意力机制是近年来的热门研究兴趣之一(Wang et al.[2017], Hu et al. [2018], Park et al. [2018], Woo et al. [2018], Gao et al. [2018]。 [2019])。它帮助深度神经网络抑制不太显着的像素或通道。许多先前的研究侧重于通过注意力操作来捕捉显着特征(Zhang 等人 [2020]、Misra 等人 [2021])。这些方法成功地利用了来自不同维度特征的互信息。然而,他们没有考虑权重的影响因素,这能够进一步抑制不重要的通道或像素。受刘等人的启发。 [2017],我们的目标是利用权重的影响因素来改进注意力机制。我们使用批量归一化的比例因子,它使用标准偏差来表示权重的重要性。这样可以避免添加 SE、BAM 和 CBAM 中使用的全连接层和卷积层。因此,我们提出了一种有效的注意力机制——基于标准化的注意力模块(NAM)。
2 相关工作
许多先前的工作试图通过抑制无关紧要的权重来提高神经网络的性能。 Squeeze-and-Excitation Networks (SENet) (Hu et al. [2018]) 将空间信息整合到通道特征响应中,并用两个多层感知器 (MLP) 层计算相应的注意力。后来,瓶颈注意模块(BAM)(Park et al. [2018])构建
并行分离的空间和通道子模块,它们可以嵌入到每个瓶颈块中。卷积块注意模块 (CBAM) (Woo et al. [2018]) 提供了一种将通道和空间注意子模块顺序嵌入的解决方案。为了避免忽略跨维度交互,三元组注意力模块 (TAM)(Misra 等人 [2021])通过旋转特征图来考虑维度相关性。然而,这些工作忽略了来自训练调整权重的信息。因此,我们旨在通过利用训练模型权重的方差测量来突出显着特征。
3 方法
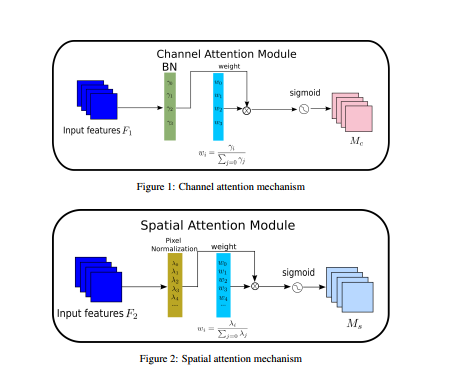
我们建议 NAM 作为一种高效且轻量级的注意力机制。 我们采用了 CBAM (Woo et al. [2018]) 的模块集成并重新设计了通道和空间注意子模块。 然后,在每个网络块的末尾嵌入一个 NAM 模块。 对于残差网络,它嵌入在残差结构的末尾。 对于通道注意力子模块,我们使用批量归一化 (BN)(Ioffe 和 Szegedy [2015])中的缩放因子,如等式 (1) 所示。 比例因子衡量通道的方差并表明它们的重要性。
B out = B N ( B in ) = γ B in − μ B σ B 2 + ϵ + β B_{\text {out }}=B N\left(B_{\text {in }}\right)=\gamma \frac{B_{\text {in }}-\mu_{B}}{\sqrt{\sigma_{B}^{2}+\epsilon}}+\beta Bout =BN(Bin )=γσB2+ϵBin −μB+β
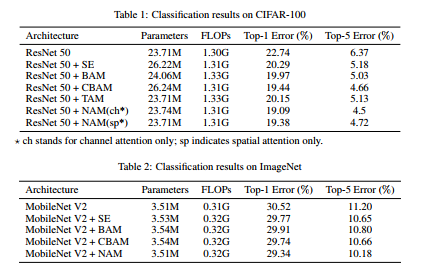
其中 μ B \mu_{B} μB 和 σ B \sigma_{B} σB 分别是小批量 $ {B}$ 的均值和标准差; γ \gamma γ 和 β \beta β 是可训练的仿射变换参数(尺度和位移)(Ioffe 和 Szegedy [2015])。通道注意力子模块如图1和等式(2)所示,其中Mc代表输出特征。 γ \gamma γ 是每个通道的缩放因子,权重为 W γ = γ i / ∑ j = 0 γ j W_{\gamma}=\gamma_{i} / \sum_{j=0} \gamma_{j} Wγ=γi/∑j=0γj。我们还将 BN 的比例因子应用于空间维度来衡量像素的重要性。我们将其命名为像素归一化。相应的空间注意力子模块如图2和等式(3)所示,其中输出表示为 M s M_{s} Ms。λ是缩放因子,权重为 W λ = λ i / ∑ j = 0 λ j W_{\lambda}=\lambda_{i} / \sum_{j=0} \lambda_{j} Wλ=λi/∑j=0λj。
为了抑制不太显着的权重,我们在损失函数中添加了一个正则化项,如等式 (4) (Liu et al. [2017]) 所示,其中 x 表示输入; y 是输出; W 代表网络权重; l(·)是损失函数; g(·)是l1范数惩罚函数; p 是平衡 g(γ) 和 g(λ) 的惩罚
M c = sigmoid ( W γ ( B N ( F 1 ) ) ) M s = sigmoid ( W λ ( B N s ( F 2 ) ) ) Loss = ∑ ( x , y ) l ( f ( x , W ) , y ) + p ∑ g ( γ ) + p ∑ g ( λ )
4 实验
在本节中,我们将 NAM 与 SE、BAM、CBAM 和 TAM 在 ResNet 和 MobileNet 上的性能进行比较。 我们使用集群上的四个 Nvidia Tesla V100 GPU 评估每种方法。 我们首先在 CIFAR-100(Krizhevsky 等人 [2009])上运行 ResNet50,并使用与 CBAM(Woo 等人 [2018])相同的预处理和训练配置,p 为 0.0001。 表 1 中的比较表明,仅具有通道或空间注意力的 NAM 优于其他四种注意力机制。 然后我们在 ImageNet 上运行 MobileNet (Deng et al. [2009]),因为它是图像分类基准的标准数据集之一。 我们将 p 设置为 0.001,其余配置与 CBAM 相同。 表 2 中的比较表明,结合了通道和空间注意力的 NAM 优于具有相似计算复杂度的其他三个。
5 结论
我们提出了一个 NAM 模块,它通过抑制不太显着的特征来提高效率。 我们的实验表明 NAM 在 ResNet 和 MobileNet 上都提供了效率增益。 我们正在对 NAM 的集成变化和超参数调整的性能进行详细分析。 我们还计划使用不同的模型压缩技术优化 NAM,以提高其效率。 未来,我们将研究其对其他深度学习架构和应用程序的影响。
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/122092352

- 点赞
- 收藏
- 关注作者
评论(0)