特征工程--单时间变量特征

时间特征

时间信息是极其敏感的信息,我们在数据竞赛中看到分数前后排出现较大gap的时候,第一时间需要考虑的就是时间信息,时间特征在很多竞赛中,往往可以决定排名的走势,那么当我们拿到时间相关的特征时,该如何进行思考,构建强有力的特征呢?(PS:本文我们介绍8大常见的单变量时间特征,剩下的两个可能一不小心拿金牌强特会在后续分享)。
1.基础周期特征(年月日特征拆解)
几乎所有的时间都可以被拆解为年-月-日-小时-分钟-秒-毫秒的形式。在大多数情况中,拆解之后的数据往往存在某些潜在规律的,比如:
-
我们对某个城市的旅游人数进行预估,旅游是存在旺季和淡季的,这个时候拆分之后得到的月份就非常重要;
-
我们预估店铺每天的销量,因为很多公司都会在月末发工资,这个时候拆解得到的天信息就会比较重要;
-
我们预估用户是否会下单,那么小时特征可能就比较重要,比如这个时候已经是晚上11点了,用户在搜索旅馆的信息,那么大概率可能就会下单,相反如果是中午在搜索,那么该用户可能并不是很急,所以下单的概率就会小一些;
-
我们预估地铁的每个小时的流量,那么早上7点到8点,晚上5点到7点,这些上下班的高峰期,流量一般就会大一些。
虽然拆解很简单,但是里面会按含有非常多的潜在重要信息,如果直接对时间信息进行Label编码,然后使用梯度提升树模型进行训练预测,是极难挖掘到此类信息的,但是拆解之后却可以极大的帮助到梯度提升树模型发现此类信息。
-
import pandas as pd
-
df = pd.DataFrame()
-
df['dt'] = ['2020-07-03', '2020-08-09', '2020-08-29', '2020-08-19']
-
df['dt'] = pd.to_datetime(df['dt'])
-
df['year'] = df['dt'].dt.year
-
df['month'] = df['dt'].dt.month
-
df['day'] = df['dt'].dt.day
-
df.head()
| dt | year | month | day | |
|---|---|---|---|---|
| 0 | 2020-07-03 | 2020 | 7 | 3 |
| 1 | 2020-08-09 | 2020 | 8 | 9 |
| 2 | 2020-08-29 | 2020 | 8 | 29 |
| 3 | 2020-08-19 | 2020 | 8 | 19 |


2.特殊周期特征(星期&节假日等)
1.星期特征
年月日特征拆解可以帮我们得到最基础的时间周期特征。那么肯定大家就就会联想到其它的时间周期特征,例如星期等信息。
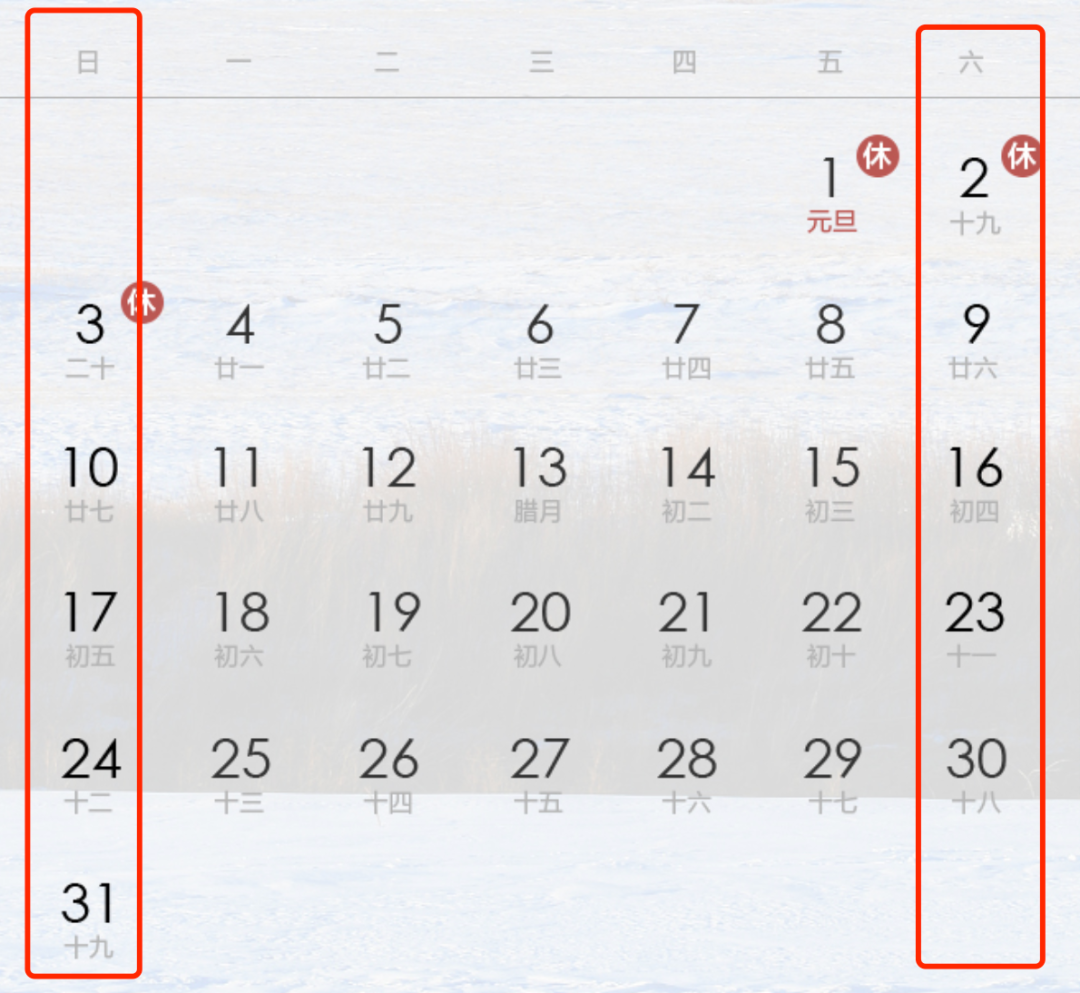
这个也较为容易理解:
-
我们需要预测某些餐馆的人流量,那么热闹的大餐馆周六周日的人流量就会比平时多一些;而一些靠近互联网大公司附近的商场可能周末人会少很多,因为平时工作日忙,就会在附近商场吃饭,但是到了周日了,不用上班了,周围的人流量大大下降,反而使得商场附近餐馆的人流量大大下降了。
2.月和星期组合特征
有些时候,我们还会将星期特征和月份特征结合,构成简单的组合特征,怎么做呢?很简单,我们还是举个例子:
-
我们需要预测某些餐馆的销售额,我们知道一般公司会在月末发放工资,所以每个月的最后一个周末的餐馆的销售额可能就会比平常的周末大一些。
3.节假日特征
节假日这个不仅包含国家的法定节假日,依据问题的不同,还有非常多特殊的日期,例如:
-
如果我们的问题是预测各大电商的日GMV,那么每年的双11等特殊日期就尤为重要;
-
如果我们的问题是预测旅游景点的客流量,那么五一、十一等节假日的日期就尤为重要;

4.节假日和星期组合特征
节假日和星期的组合也是非常强的组合特征,在有些问题中,又是重要节日又是周末会是非常强的信息,在另外一些问题中,节假日如果是连着周六周日的,那么这些信息也都是非常重要的组合特征,因为这意味着我们的假期可能延长了,所以会是一种较强的信号。
-
df['weekday'] = df['dt'].dt.weekday
-
df.head()
| dt | year | month | day | weekday | |
|---|---|---|---|---|---|
| 0 | 2020-07-03 | 2020 | 7 | 3 | 4 |
| 1 | 2020-08-09 | 2020 | 8 | 9 | 6 |
| 2 | 2020-08-29 | 2020 | 8 | 29 | 5 |
| 3 | 2020-08-19 | 2020 | 8 | 19 | 2 |
月份暗含信息
该特征经常适用于关于以月为单位的预估问题,例如预估某个公司每个月的产值,某个景点的旅游人数,这个时候每个月中工作日的天数以及休假的天数就是非常重要的信息。

时间差
1.相邻时间差
该特征顾明思议,就是相邻两个时间戳之间的差值,在有些问题中,例如用户浏览每个视频的开始时间戳,相邻两个时间戳的差值一般就是用户浏览视频的差值,如果差值越大,那么该用户可能对上一个视频的喜好程度往往越大,此时,相邻时间戳的就是非常有价值的特征。
2.相邻时间差频率编码
这个是关于相邻特征差值的频率编码,该特征往往适合相邻时间差互补的一个特征,可以帮助我们更好地挖掘一些内在的信息,例如有些自律的用户在会控制自己的休闲与工作的时长,我们在统计用户的生活习惯时,发现出现大量的相邻时间差时10分钟和60分钟的,原来是该用户喜欢工作60分钟就休息10分钟,此时相邻时间差频率编码就可以协助我们发现此类信息。
-
'''
-
以月为单位计算基础时间差
-
'''
-
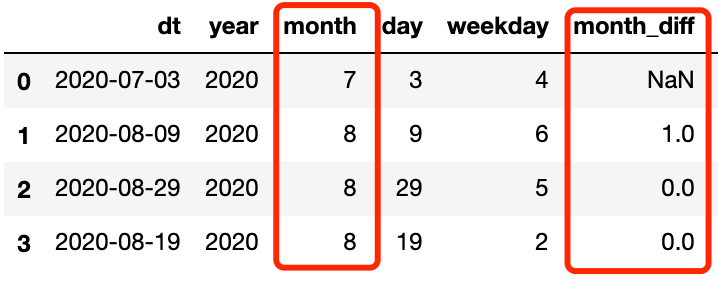
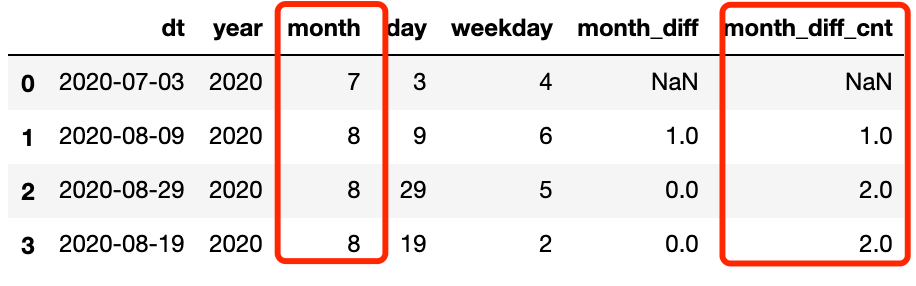
df['month_diff'] = df['month'] - df['month'].shift(1)
-
df['month_diff_cnt'] = df['month_diff'].map(df['month_diff'].value_counts())
-
df.head()
| dt | year | month | day | weekday | month_diff | month_diff_cnt | |
|---|---|---|---|---|---|---|---|
| 0 | 2020-07-03 | 2020 | 7 | 3 | 4 | NaN | NaN |
| 1 | 2020-08-09 | 2020 | 8 | 9 | 6 | 1.0 | 1.0 |
| 2 | 2020-08-29 | 2020 | 8 | 29 | 5 | 0.0 | 2.0 |
| 3 | 2020-08-19 | 2020 | 8 | 19 | 2 | 0.0 | 2.0 |
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/115856446

- 点赞
- 收藏
- 关注作者
评论(0)