图像特征-上篇(10大图像特征)

图像特征

和文本特征类似,图像特征也是梯度提升树模型非常难以挖掘的一类数据,目前图像相关的问题,例如图像分类,图像分割等等几乎都是以神经网络为主的模型,但是在一些多模态的问题中,例如商品搜索推荐的问题中,里面既包含图像信息又含有文本信息等,这个时候基于梯度提升树模型的建模方案还是至关重要的,这个时候为了更好地使用所有的数据信息,我们需要对图像特征进行多方位的提取。
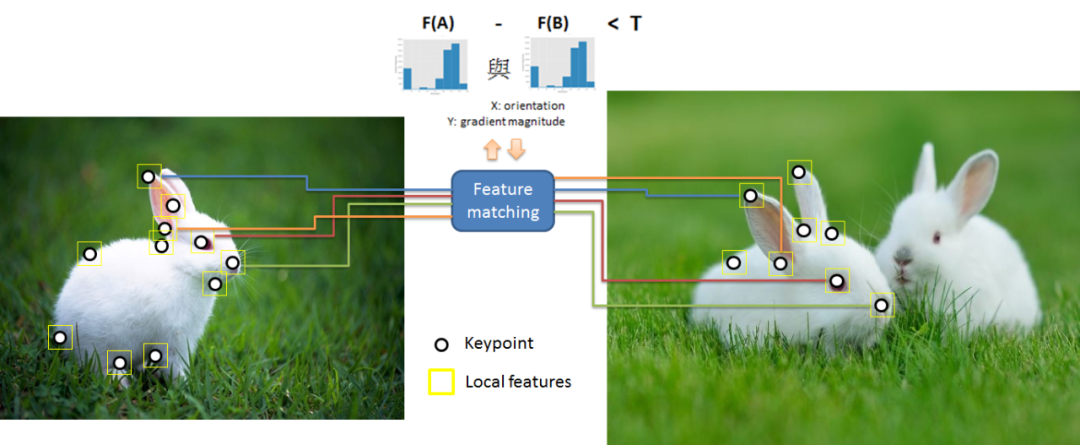
本节我们将会介绍图像特征提取中常常采用的方法技术。


1.图像长宽
图像的长宽可以表示图像的大小。
-
图像的长宽以及channel数:表示图像的大小;
-
# !pip3 install opencv-python
-
import cv2
-
img = cv2.imread('./imgs/chapter7/img_example.jpeg')
-
img.shape
(810, 1440, 3)
2.图像格式特征
图像的格式有非常多种,例如bmp,jpg,png,tif,gif,pcx,tga,exif,fpx,svg,psd,cdr,pcd,dxf,ufo,eps,ai,raw,WMF,webp,avif等,不同格式的图像也会含有不同的信息,不同情况下我们会使用不同的图像形式进行存储。图像的存储格式主要可以反映真实性、透明性、矢量性(该回答摘自知乎jpg和png有什么区别?下showvim的回答。

-
真实性中就是色彩度、位深、损耗(压缩)等;(jpg、jpeg、gif、tiff、bmp)
-
透明性就很明显了,就是支技透明的特性,但这里也有一个就是位深,他会影响透明度的深度png8与png24的差异就在这里;(png)
-
特殊动画,就是支持帧的特点,可以做成动画;(gif)4、 矢量性就可还原度,可再编辑的特性,通俗一点来讲就是很多人常说的放大不模糊的特点,因为他们的组成是由公式曲线方程生成的(但我们是可视化的编辑)(ai、cdr、eps)
这些信息的提取只需要对图像的文本进行正则匹配即可。
3.图像的创建时间
在一些图像分类的问题中,有一些图片是作者拍摄的或者收集的,所以相邻时间段的图片往往是一类图像,这个时候图像的创建时间就是一个非常重要的特征。
-
import time
-
import datetime
-
import os
-
-
def TimeStampToTime(timestamp):
-
timeStruct = time.localtime(timestamp)
-
return time.strftime('%Y-%m-%d %H:%M:%S',timeStruct)
-
-
def get_FileCreateTime(filePath):
-
filePath = filePath
-
t = os.path.getctime(filePath)
-
return TimeStampToTime(t)
-
-
get_FileCreateTime('./imgs/chapter7/img_example.jpeg')
'2021-04-25 13:24:03'
4.图片的亮度特征
1.暗度
在很多广告中,图片的亮度如果太低的话,会让很多消费者觉得看不清,不利于宣传,用于也不会去点击,所以图片的亮度信息在这个时候是一种不错的特征。对图像中突出的颜色的分析可以很好地表明图像是否暗淡。
-
from collections import defaultdict
-
from scipy.stats import itemfreq
-
from scipy import ndimage as ndi
-
import matplotlib.pyplot as plt
-
from skimage import feature
-
from PIL import Image as IMG
-
import numpy as np
-
import pandas as pd
-
import operator
-
import cv2
-
import os
-
-
def color_analysis(img):
-
# obtain the color palatte of the image
-
palatte = defaultdict(int)
-
for pixel in img.getdata():
-
palatte[pixel] += 1
-
-
# sort the colors present in the image
-
sorted_x = sorted(palatte.items(), key=operator.itemgetter(1), reverse = True)
-
light_shade, dark_shade, shade_count, pixel_limit = 0, 0, 0, 25
-
for i, x in enumerate(sorted_x[:pixel_limit]):
-
if all(xx <= 20 for xx in x[0][:3]): ## dull : too much darkness
-
dark_shade += x[1]
-
if all(xx >= 240 for xx in x[0][:3]): ## bright : too much whiteness
-
light_shade += x[1]
-
shade_count += x[1]
-
-
light_percent = round((float(light_shade)/shade_count)*100, 2)
-
dark_percent = round((float(dark_shade)/shade_count)*100, 2)
-
return light_percent, dark_percent
-
-
def perform_color_analysis(img, flag):
-
path = img
-
im = IMG.open(path)
-
-
size = im.size
-
halves = (size[0]/2, size[1]/2)
-
im1 = im.crop((0, 0, size[0], halves[1]))
-
im2 = im.crop((0, halves[1], size[0], size[1]))
-
-
try:
-
light_percent1, dark_percent1 = color_analysis(im1)
-
light_percent2, dark_percent2 = color_analysis(im2)
-
except Exception as e:
-
return None
-
-
light_percent = (light_percent1 + light_percent2)/2
-
dark_percent = (dark_percent1 + dark_percent2)/2
-
-
if flag == 'black':
-
return dark_percent
-
elif flag == 'white':
-
return light_percent
-
else:
-
return None
-
df = pd.DataFrame()
-
df['image'] = ['./imgs/chapter7/img_example.jpeg']
-
df['dullness'] = df['image'].apply(lambda x : perform_color_analysis(x, 'black'))
-
df.head()
| image | dullness | |
|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 39.735 |
2.亮度
如果图像太白或者太亮,这也是不利于图片的美观的,这种图片的点击率也会相对较低。此处我们判断所有通道上最亮的N个像素点的值大于某个阈值的比例来作为图像的亮度信息。
-
df['whiteness'] = df['image'].apply(lambda x : perform_color_analysis(x, 'white'))
-
df
| image | dullness | whiteness | |
|---|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 39.735 | 0.0 |
5.图像均匀度
某些图像可能不包含像素变化,并且完全uniform的。平均像素宽度是表示图像中存在的边缘数量的度量。如果这个数字非常低,那么图像很可能是一个单一的的图像,无法表示正确的内容。此处我们可以直接使用skimage的Canny检测。
-
def average_pixel_width(img):
-
path = img
-
im = IMG.open(path)
-
im_array = np.asarray(im.convert(mode='L'))
-
edges_sigma1 = feature.canny(im_array, sigma=3)
-
apw = (float(np.sum(edges_sigma1)) / (im.size[0]*im.size[1]))
-
return apw*100
-
df['average_pixel_width'] = df['image'].apply(lambda x : average_pixel_width(x))
-
df[['image','average_pixel_width']]
| image | average_pixel_width | |
|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 1.338563 |
6.图像的主导颜色
图片中使用的颜色在吸引用户方面起着重要的作用。可以创建与颜色相关的附加功能,例如主色和平均色。
-
def get_dominant_color(img):
-
path = img
-
img = cv2.imread(path)
-
arr = np.float32(img)
-
pixels = arr.reshape((-1, 3))
-
-
n_colors = 5
-
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 200, .1)
-
flags = cv2.KMEANS_RANDOM_CENTERS
-
_, labels, centroids = cv2.kmeans(pixels, n_colors, None, criteria, 10, flags)
-
-
palette = np.uint8(centroids)
-
quantized = palette[labels.flatten()]
-
quantized = quantized.reshape(img.shape)
-
-
dominant_color = palette[np.argmax(itemfreq(labels)[:, -1])]
-
return dominant_color
-
-
df['dominant_color'] = df['image'].apply(get_dominant_color)
-
df
-
<ipython-input-92-970fc6abdf35>:16: DeprecationWarning: `itemfreq` is deprecated!
-
`itemfreq` is deprecated and will be removed in a future version. Use instead `np.unique(..., return_counts=True)`
-
dominant_color = palette[np.argmax(itemfreq(labels)[:, -1])]
| image | dullness | whiteness | average_pixel_width | dominant_color | |
|---|---|---|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 39.735 | 0.0 | 1.338563 | [163, 198, 219] |
-
df['dominant_red'] = df['dominant_color'].apply(lambda x: x[0]) / 255
-
df['dominant_green'] = df['dominant_color'].apply(lambda x: x[1]) / 255
-
df['dominant_blue'] = df['dominant_color'].apply(lambda x: x[2]) / 255
-
df[['image','dominant_red','dominant_green','dominant_blue']]
| image | dominant_red | dominant_green | dominant_blue | |
|---|---|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 0.639216 | 0.776471 | 0.858824 |
7.各channel的统计特征
各个channel的全局统计特征,例如,各个channel的均值,方差,中位数,众数,分位数等等。
-
# - 以均值为例
-
-
def get_average_color(img):
-
path = img
-
img = cv2.imread(path)
-
average_color = [img[:, :, i].mean() for i in range(img.shape[-1])]
-
return average_color
-
-
df['average_color'] = df['image'].apply(get_average_color)
-
df['average_red'] = df['average_color'].apply(lambda x: x[0]) / 255
-
df['average_green'] = df['average_color'].apply(lambda x: x[1]) / 255
-
df['average_blue'] = df['average_color'].apply(lambda x: x[2]) / 255
-
df[['image','average_red','average_green','average_blue']]
-
| image | average_red | average_green | average_blue | |
|---|---|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 0.497662 | 0.50784 | 0.532006 |
8.图像的模糊特征
该方法摘自于《Diatom Autofocusing in Brightfield Microscopy: A Comparative Study》,本文作者Pech-Pacheco等人提出了一种Laplacian滤波器的变种,可用来评估图像的模糊度,在该技术中,图像的单通道和Laplacian Filter卷积。如果指定的值小于阈值,则图像模糊,否则不会。
-
def get_blurrness_score(image):
-
path = image
-
image = cv2.imread(path)
-
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
-
fm = cv2.Laplacian(image, cv2.CV_64F).var()
-
return fm
-
-
df['blurrness'] = df['image'].apply(get_blurrness_score)
-
df[['image','blurrness']].head(5)
| image | blurrness | |
|---|---|---|
| 0 | ./imgs/chapter7/img_example.jpeg | 475.782864 |
9.图像直方图特征
对图像中的所有像素点进行分箱,统计每个直方图中像素的个数,注意:很多时候图像的大小不一样,所以一般使用百分比特征效果会好一些。
有些时候我们会选择分箱的个数多一些,为了将产出的新特征加入到模型中,会对特征进行PCA或者SVD等降维操作。
-
def get_histogram_features(image):
-
path = image
-
image = cv2.imread(path)
-
print(image.ravel().shape)
-
hist, bins = np.histogram(image.ravel(), bins=50)
-
-
return hist / image.ravel().shape
-
-
hist = df['image'].apply(get_histogram_features)
-
hist[0]
-
(3499200,)
-
array([0.0054261 , 0.01778464, 0.02784208, 0.02863769, 0.01264546,
-
0.01067358, 0.01119999, 0.00853052, 0.01141918, 0.0114409 ,
-
0.01528206, 0.0153698 , 0.01494227, 0.01478738, 0.01672297,
-
0.01708791, 0.02324588, 0.02150692, 0.02266575, 0.02503229,
-
0.0280487 , 0.02289752, 0.02528178, 0.02137889, 0.02387231,
-
0.02164495, 0.02553927, 0.02519462, 0.02330447, 0.02359082,
-
0.02976452, 0.02889003, 0.03554155, 0.04038637, 0.03270405,
-
0.02817644, 0.02875229, 0.0253618 , 0.02177298, 0.02141518,
-
0.02612597, 0.01889403, 0.01441044, 0.01199503, 0.01037809,
-
0.00855738, 0.01004915, 0.01521205, 0.00871342, 0.00990255])
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/116144633

- 点赞
- 收藏
- 关注作者
评论(0)