Win10环境下,将VOC数据集转为YOLOV5使用的数据集。

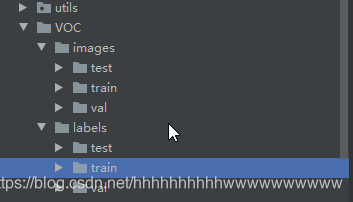
YOLOV5 采用的数据集和以前的yolo模型不一样,数据结构如下图:
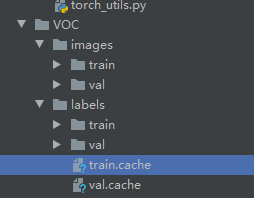
images文件夹存放train和val的图片
labels里面存放train和val的物体数据,里面的每个txt文件和images里面的图片是一一对应的。
txt文件的内容如下:
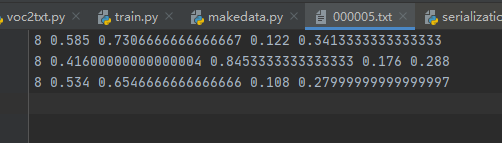
格式:物体类别 x y w h
坐标是不是真实的坐标,是将坐标除以宽高后的计算出来的,是相对于宽和高的比例。
数据介绍完了,下面讲如何将voc数据转为yolov5使用的数据集。
本次采用的数据集是PASCAL VOC 2007。
地址:
训练集和验证集:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
测试集:
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
下载后解压,将测试集和训练集合并在一起。在YOLOV5工程下面新建tmp文件夹,然后将voc数据集放到tmp文件夹下面,如图:
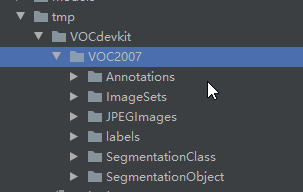
在tmp文件夹下面新家voc2txt.py文件,将voc的数据转为txt数据。
讲解voc2txt.py代码:
导入包:
import xml.etree.ElementTree as ET
import os
from os import getcwd
列出数据集的类别:
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable", "dog",
"horse", "motorbike", "person", "pottedplant", "sheep",
"sofa", "train", "tvmonitor"]
对box进行转换,转换后的坐标就是相对长宽的小数:
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
下面这个方法是获取单个xml的内容,将其转换。
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
整体代码如下:
-
import xml.etree.ElementTree as ET
-
import os
-
from os import getcwd
-
-
sets = [('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
-
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog",
-
"horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
-
-
-
def convert(size, box):
-
dw = 1. / (size[0])
-
dh = 1. / (size[1])
-
x = (box[0] + box[1]) / 2.0 - 1
-
y = (box[2] + box[3]) / 2.0 - 1
-
w = box[1] - box[0]
-
h = box[3] - box[2]
-
x = x * dw
-
w = w * dw
-
y = y * dh
-
h = h * dh
-
return (x, y, w, h)
-
-
-
def convert_annotation(year, image_id):
-
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml' % (year, image_id))
-
out_file = open('VOCdevkit/VOC%s/labels/%s.txt' % (year, image_id), 'w')
-
tree = ET.parse(in_file)
-
root = tree.getroot()
-
size = root.find('size')
-
w = int(size.find('width').text)
-
h = int(size.find('height').text)
-
-
for obj in root.iter('object'):
-
difficult = obj.find('difficult').text
-
cls = obj.find('name').text
-
if cls not in classes or int(difficult) == 1:
-
continue
-
cls_id = classes.index(cls)
-
xmlbox = obj.find('bndbox')
-
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
-
float(xmlbox.find('ymax').text))
-
bb = convert((w, h), b)
-
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
-
-
wd = getcwd()
-
for year, image_set in sets:
-
if not os.path.exists('VOCdevkit/VOC%s/labels/' % year):
-
os.makedirs('VOCdevkit/VOC%s/labels/' % year)
-
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt' % (year, image_set)).read().strip().split()
-
list_file = open('%s.txt' % image_set, 'w')
-
for image_id in image_ids:
-
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n' % (wd, year, image_id))
-
convert_annotation(year, image_id)
-
list_file.close()
运行完成后会生成test.txt train.txt val.txt。如图:
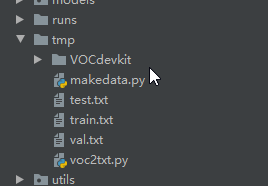
在tmp文件夹新建makedata.py,将生成的中间结果转为YOLOV5所使用的最终代码。
代码如下:
-
import shutil
-
import os
-
-
file_List = ["train", "val", "test"]
-
for file in file_List:
-
if not os.path.exists('../VOC/images/%s' % file):
-
os.makedirs('../VOC/images/%s' % file)
-
if not os.path.exists('../VOC/labels/%s' % file):
-
os.makedirs('../VOC/labels/%s' % file)
-
print(os.path.exists('../tmp/%s.txt' % file))
-
f = open('../tmp/%s.txt' % file, 'r')
-
lines = f.readlines()
-
for line in lines:
-
print(line)
-
line = "/".join(line.split('/')[-5:]).strip()
-
shutil.copy(line, "../VOC/images/%s" % file)
-
line = line.replace('JPEGImages', 'labels')
-
line = line.replace('jpg', 'txt')
-
shutil.copy(line, "../VOC/labels/%s/" % file)
执行完成后,会在yolov5工程下生成最终的数据集。
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/108782268

- 点赞
- 收藏
- 关注作者
评论(0)