在生产环境中使用 Keras、Redis、Flask 和 Apache 进行深度学习

今天我们演示如何在生产环境中使用Keras、Redis、Flask 和 Apache 进行深度学习
项目结构
keras-complete-rest-api
├── helpers.py
├── jemma.png
├── keras_rest_api_app.wsgi
├── run_model_server.py
├── run_web_server.py
├── settings.py
├── simple_request.py
└── stress_test.py
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
文件解释:
- run_web_server.py 包含我们所有的 Flask Web 服务器代码——Apache 将在启动我们的深度学习 Web 应用程序时加载它。
- run_model_server.py 将:
- 从磁盘加载我们的 Keras 模型
- 不断轮询Redis寻找新图像进行分类
- 对图像进行分类(批量处理以提高效率)
- 将推理结果写回 Redis,以便它们可以通过 Flask 返回给客户端。
- settings.py 包含我们深度学习生产服务的所有基于 Python 的设置,例如 Redis 主机/端口信息、图像分类设置、图像队列名称等。
- helpers.py 包含 run_web_server.py 和 run_model_server.py 都将使用的实用函数(即 base64 编码)。
- keras_rest_api_app.wsgi 包含我们的 WSGI 设置,因此我们可以从我们的 Apache 服务器为 Flask 应用程序提供服务。
- simple_request.py 可用于以编程方式使用我们的深度学习 API 服务的结果。
- jemma.png 是我家小猎犬的照片。在调用 REST API 以验证它确实有效时,我们将使用她作为示例图像。
- 最后,我们将使用 stress_test.py 来给我们的服务器施加压力并在整个过程中测量图像分类。
我们在 Flask 服务器上有一个端点 /predict 。此方法位于 run_web_server.py 中,将根据需要计算输入图像的分类。图像预处理也在 run_web_server.py 中处理。
为了使我们的服务器做好生产准备,我从上周的单个脚本中取出了分类过程函数并将其放置在 run_model_server.py 中。这个脚本非常重要,因为它将加载我们的 Keras 模型并从 Redis 中的图像队列中抓取图像进行分类。结果被写回 Redis(/predict 端点和 run_web_server.py 中的相应函数监视 Redis 以将结果发送回客户端)。
但是除非我们知道深度学习 REST API 服务器的功能和局限性,否则它有什么好处呢?
在 stress_test.py 中,我们测试我们的服务器。我们将通过启动 500 个并发线程来实现这一点,这些线程将我们的图像发送到服务器进行并行分类。我建议在服务器 localhost 上运行它以启动,然后从异地客户端运行它。
构建我们的深度学习网络应用
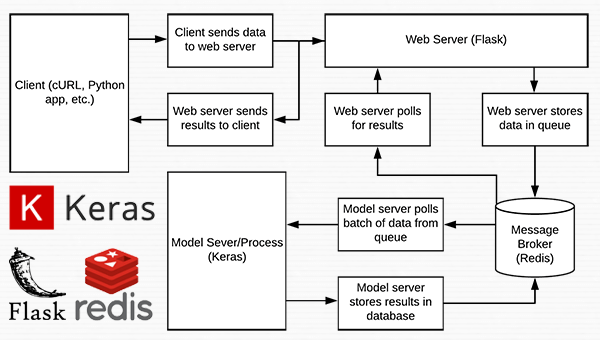
图 1:使用 Python、Keras、Redis 和 Flask 构建的深度学习 REST API 服务器的数据流图。
这个项目中使用的几乎每一行代码都来自我们之前关于构建可扩展深度学习 REST API 的文章——唯一的变化是我们将一些代码移动到单独的文件中,以促进生产环境中的可扩展性。
设置和配置
# initialize Redis connection settings
REDIS_HOST = "localhost"
REDIS_PORT = 6379
REDIS_DB = 0
# initialize constants used to control image spatial dimensions and
# data type
IMAGE_WIDTH = 224
IMAGE_HEIGHT = 224
IMAGE_CHANS = 3
IMAGE_DTYPE = "float32"
# initialize constants used for server queuing
IMAGE_QUEUE = "image_queue"
BATCH_SIZE = 32
SERVER_SLEEP = 0.25
CLIENT_SLEEP = 0.25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在 settings.py 中,您将能够更改服务器连接、图像尺寸 + 数据类型和服务器队列的参数。
# import the necessary packages
import numpy as np
import base64
import sys
def base64_encode_image(a):
# base64 encode the input NumPy array
return base64.b64encode(a).decode("utf-8")
def base64_decode_image(a, dtype, shape):
# if this is Python 3, we need the extra step of encoding the
# serialized NumPy string as a byte object
if sys.version_info.major == 3:
a = bytes(a, encoding="utf-8")
# convert the string to a NumPy array using the supplied data
# type and target shape
a = np.frombuffer(base64.decodestring(a), dtype=dtype)
a = a.reshape(shape)
# return the decoded image
return a
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
helpers.py 文件包含两个函数——一个用于 base64 编码,另一个用于解码。
编码是必要的,以便我们可以在 Redis 中序列化 + 存储我们的图像。 同样,解码是必要的,以便我们可以在预处理之前将图像反序列化为 NumPy 数组格式。
深度学习网络服务器
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.applications.resnet50 import preprocess_input
from PIL import Image
import numpy as np
import settings
import helpers
import flask
import redis
import uuid
import time
import json
import io
# initialize our Flask application and Redis server
app = flask.Flask(__name__)
db = redis.StrictRedis(host=settings.REDIS_HOST,
port=settings.REDIS_PORT, db=settings.REDIS_DB)
def prepare_image(image, target):
# if the image mode is not RGB, convert it
if image.mode != "RGB":
image = image.convert("RGB")
# resize the input image and preprocess it
image = image.resize(target)
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
image = preprocess_input(image)
# return the processed image
return image
@app.route("/")
def homepage():
return "Welcome to the PyImageSearch Keras REST API!"
@app.route("/predict", methods=["POST"])
def predict():
# initialize the data dictionary that will be returned from the
# view
data = {"success": False}
# ensure an image was properly uploaded to our endpoint
if flask.request.method == "POST":
if flask.request.files.get("image"):
# read the image in PIL format and prepare it for
# classification
image = flask.request.files["image"].read()
image = Image.open(io.BytesIO(image))
image = prepare_image(image,
(settings.IMAGE_WIDTH, settings.IMAGE_HEIGHT))
# ensure our NumPy array is C-contiguous as well,
# otherwise we won't be able to serialize it
image = image.copy(order="C")
# generate an ID for the classification then add the
# classification ID + image to the queue
k = str(uuid.uuid4())
image = helpers.base64_encode_image(image)
d = {"id": k, "image": image}
db.rpush(settings.IMAGE_QUEUE, json.dumps(d))
# keep looping until our model server returns the output
# predictions
while True:
# attempt to grab the output predictions
output = db.get(k)
# check to see if our model has classified the input
# image
if output is not None:
# add the output predictions to our data
# dictionary so we can return it to the client
output = output.decode("utf-8")
data["predictions"] = json.loads(output)
# delete the result from the database and break
# from the polling loop
db.delete(k)
break
# sleep for a small amount to give the model a chance
# to classify the input image
time.sleep(settings.CLIENT_SLEEP)
# indicate that the request was a success
data["success"] = True
# return the data dictionary as a JSON response
return flask.jsonify(data)
# for debugging purposes, it's helpful to start the Flask testing
# server (don't use this for production
if __name__ == "__main__":
print("* Starting web service...")
app.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
在 run_web_server.py 中,您将看到 predict ,该函数与我们的 REST API /predict 端点相关联。
predict 函数将编码的图像推送到 Redis 队列中,然后不断循环/轮询,直到它从模型服务器获取预测数据。 然后我们对数据进行 JSON 编码并指示 Flask 将数据发送回客户端。
深度学习模型服务器
# import the necessary packages
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.applications.resnet50 import decode_predictions
import numpy as np
import settings
import helpers
import redis
import time
import json
# connect to Redis server
db = redis.StrictRedis(host=settings.REDIS_HOST,
port=settings.REDIS_PORT, db=settings.REDIS_DB)
def classify_process():
# load the pre-trained Keras model (here we are using a model
# pre-trained on ImageNet and provided by Keras, but you can
# substitute in your own networks just as easily)
print("* Loading model...")
model = ResNet50(weights="imagenet")
print("* Model loaded")
# continually pool for new images to classify
while True:
# attempt to grab a batch of images from the database, then
# initialize the image IDs and batch of images themselves
queue = db.lrange(settings.IMAGE_QUEUE, 0,
settings.BATCH_SIZE - 1)
imageIDs = []
batch = None
# loop over the queue
for q in queue:
# deserialize the object and obtain the input image
q = json.loads(q.decode("utf-8"))
image = helpers.base64_decode_image(q["image"],
settings.IMAGE_DTYPE,
(1, settings.IMAGE_HEIGHT, settings.IMAGE_WIDTH,
settings.IMAGE_CHANS))
# check to see if the batch list is None
if batch is None:
batch = image
# otherwise, stack the data
else:
batch = np.vstack([batch, image])
# update the list of image IDs
imageIDs.append(q["id"])
# check to see if we need to process the batch
if len(imageIDs) > 0:
# classify the batch
print("* Batch size: {}".format(batch.shape))
preds = model.predict(batch)
results = decode_predictions(preds)
# loop over the image IDs and their corresponding set of
# results from our model
for (imageID, resultSet) in zip(imageIDs, results):
# initialize the list of output predictions
output = []
# loop over the results and add them to the list of
# output predictions
for (imagenetID, label, prob) in resultSet:
r = {"label": label, "probability": float(prob)}
output.append(r)
# store the output predictions in the database, using
# the image ID as the key so we can fetch the results
db.set(imageID, json.dumps(output))
# remove the set of images from our queue
db.ltrim(settings.IMAGE_QUEUE, len(imageIDs), -1)
# sleep for a small amount
time.sleep(settings.SERVER_SLEEP)
# if this is the main thread of execution start the model server
# process
if __name__ == "__main__":
classify_process()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
run_model_server.py 文件包含我们的classify_process 函数。 这个函数加载我们的模型,然后对一批图像运行预测。 这个过程最好在 GPU 上执行,但也可以使用 CPU。
在这个例子中,为了简单起见,我们将使用在 ImageNet 数据集上预训练的 ResNet50。 您可以修改classify_process 以利用您自己的深度学习模型。
WSGI 配置
# add our app to the system path
import sys
sys.path.insert(0, "/var/www/html/keras-complete-rest-api")
# import the application and away we go...
from run_web_server import app as application
- 1
- 2
- 3
- 4
- 5
文件 keras_rest_api_app.wsgi 是我们深度学习 REST API 的一个新组件。 这个 WSGI 配置文件将我们的服务器目录添加到系统路径并导入 Web 应用程序以启动所有操作。 我们在 Apache 服务器设置文件 /etc/apache2/sites-available/000-default.conf 中指向此文件,稍后将在本博文中介绍。
压力测试
# import the necessary packages
from threading import Thread
import requests
import time
# initialize the Keras REST API endpoint URL along with the input
# image path
KERAS_REST_API_URL = "http://localhost/predict"
IMAGE_PATH = "jemma.png"
# initialize the number of requests for the stress test along with
# the sleep amount between requests
NUM_REQUESTS = 500
SLEEP_COUNT = 0.05
def call_predict_endpoint(n):
# load the input image and construct the payload for the request
image = open(IMAGE_PATH, "rb").read()
payload = {"image": image}
# submit the request
r = requests.post(KERAS_REST_API_URL, files=payload).json()
# ensure the request was sucessful
if r["success"]:
print("[INFO] thread {} OK".format(n))
# otherwise, the request failed
else:
print("[INFO] thread {} FAILED".format(n))
# loop over the number of threads
for i in range(0, NUM_REQUESTS):
# start a new thread to call the API
t = Thread(target=call_predict_endpoint, args=(i,))
t.daemon = True
t.start()
time.sleep(SLEEP_COUNT)
# insert a long sleep so we can wait until the server is finished
# processing the images
time.sleep(300)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
我们的 stress_test.py 脚本将帮助我们测试服务器并确定其限制。 我总是建议对您的深度学习 REST API 服务器进行压力测试,以便您知道是否(更重要的是,何时)需要添加额外的 GPU、CPU 或 RAM。 此脚本启动 NUM_REQUESTS 线程和 POST 到 /predict 端点。 这取决于我们的 Flask 网络应用程序。
编译安装Redis
Redis 是一种高效的内存数据库,它将充当我们的队列/消息代理。 获取和安装Redis非常简单:
$ wget http://download.redis.io/redis-stable.tar.gz
$ tar xvzf redis-stable.tar.gz
$ cd redis-stable
$ make
$ sudo make install
- 1
- 2
- 3
- 4
- 5
创建您的深度学习 Python 虚拟环境
安装附加包:
$ workon dl4cv
$ pip install flask
$ pip install gevent
$ pip install requests
$ pip install redis
- 1
- 2
- 3
- 4
- 5
安装 Apache Web 服务器
可以使用其他 Web 服务器,例如 nginx,但由于我对 Apache 有更多的经验(因此通常更熟悉 Apache),因此我将在此示例中使用 Apache。 Apache 可以通过以下方式安装:
$ sudo apt-get install apache2
- 1
如果您使用 Python 3 创建了一个虚拟环境,您将需要安装 Python 3 WSGI + Apache 模块:
$ sudo apt-get install libapache2-mod-wsgi-py3
$ sudo a2enmod wsgi
- 1
- 2
要验证是否安装了 Apache,请打开浏览器并输入 Web 服务器的 IP 地址。 如果您看不到服务器启动画面,请确保打开端口 80 和端口 5000。 就我而言,我服务器的 IP 地址是 54.187.46.215(你的会有所不同)。 在浏览器中输入这个,我看到:
Sym-link链接您的 Flask + 深度学习应用程序
默认情况下,Apache 提供来自 /var/www/html 的内容。 我建议创建一个从 /var/www/html 到 Flask Web 应用程序的符号链接。 我已将我的深度学习 + Flask 应用程序上传到名为 keras-complete-rest-api 的目录中的主目录:
$ ls ~
keras-complete-rest-api
- 1
- 2
我可以通过以下方式将其符号链接到 /var/www/html:
$ cd /var/www/html/
$ sudo ln -s ~/keras-complete-rest-api keras-complete-rest-api
- 1
- 2
更新您的 Apache 配置以指向 Flask 应用程序
为了将 Apache 配置为指向我们的 Flask 应用程序,我们需要编辑 /etc/apache2/sites-available/000-default.conf 。 在你最喜欢的文本编辑器中打开(这里我将使用 vi ):
$ sudo vi /etc/apache2/sites-available/000-default.conf
- 1
在文件的顶部提供您的 WSGIPythonHome(Python bin 目录的路径)和 WSGIPythonPath(Python 站点包目录的路径)配置:
WSGIPythonHome /home/ubuntu/.virtualenvs/keras_flask/bin
WSGIPythonPath /home/ubuntu/.virtualenvs/keras_flask/lib/python3.5/site-packages
<VirtualHost *:80>
...
</VirtualHost>
- 1
- 2
- 3
- 4
- 5
在 Ubuntu 18.04 上,您可能需要将第一行更改为:
WSGIPythonHome /home/ubuntu/.virtualenvs/keras_flask
由于我们在本示例中使用 Python 虚拟环境(我将我的虚拟环境命名为 keras_flask ),因此我们为 Python 虚拟环境提供 bin 和 site-packages 目录的路径。 然后在 的正文中,在 ServerAdmin 和 DocumentRoot 之后,添加:
<VirtualHost *:80>
...
WSGIDaemonProcess keras_rest_api_app threads=10
WSGIScriptAlias / /var/www/html/keras-complete-rest-api/keras_rest_api_app.wsgi
<Directory /var/www/html/keras-complete-rest-api>
WSGIProcessGroup keras_rest_api_app
WSGIApplicationGroup %{GLOBAL}
Order deny,allow
Allow from all
</Directory>
...
</VirtualHost>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
符号链接 CUDA 库(可选,仅限 GPU)
如果您将 GPU 用于深度学习并希望利用 CUDA(您为什么不这样做),不幸的是,Apache 不了解 /usr/local/cuda/lib64 中的 CUDA 的 *.so 库。
我不确定什么是“最正确”的方式向 Apache 指示这些 CUDA 库所在的位置,但“完全破解”解决方案是将所有文件从 /usr/local/cuda/lib64 符号链接到 /usr/lib :
$ cd /usr/lib
$ sudo ln -s /usr/local/cuda/lib64/* ./
- 1
- 2
重新启动 Apache Web 服务器
编辑完 Apache 配置文件并可选择符号链接 CUDA 深度学习库后,请务必通过以下方式重新启动 Apache 服务器:
$ sudo service apache2 restart
- 1
测试您的 Apache Web 服务器 + 深度学习端点
要测试 Apache 是否已正确配置以提供 Flask + 深度学习应用程序,请刷新您的 Web 浏览器:
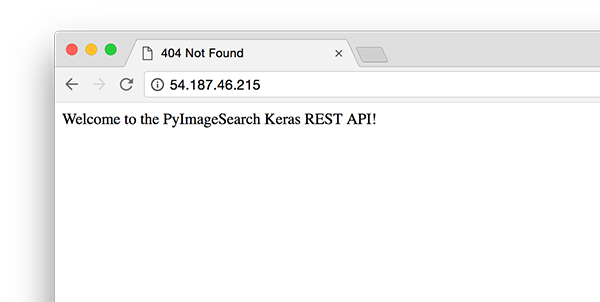
您现在应该看到文本“欢迎使用 PyImageSearch Keras REST API!” 在您的浏览器中。 一旦你达到这个阶段,你的 Flask 深度学习应用程序就应该准备好了。 综上所述,如果您遇到任何问题,请确保参考下一节……
提示:如果遇到问题,请监控 Apache 错误日志
多年来,我一直在使用 Python + Web 框架,例如 Flask 和 Django,但在正确配置环境时仍然会出错。 虽然我希望有一种防弹的方法来确保一切顺利,但事实是,在此过程中可能会出现一些问题。 好消息是 WSGI 将 Python 事件(包括失败)记录到服务器日志中。 在 Ubuntu 上,Apache 服务器日志位于 /var/log/apache2/ :
$ ls /var/log/apache2
access.log error.log other_vhosts_access.log
- 1
- 2
调试时,我经常打开一个运行的终端:
$ tail -f /var/log/apache2/error.log
- 1
…所以我可以看到第二个错误滚滚而来。 使用错误日志帮助您在服务器上启动和运行 Flask。
启动您的深度学习模型服务器
您的 Apache 服务器应该已经在运行。 如果没有,您可以通过以下方式启动它:
$ sudo service apache2 start
- 1
然后,您将要启动 Redis 存储:
$ redis-server
- 1
并在单独的终端中启动 Keras 模型服务器:
$ python run_model_server.py
* Loading model...
...
* Model loaded
- 1
- 2
- 3
- 4
从那里尝试向您的深度学习 API 服务提交示例图像:
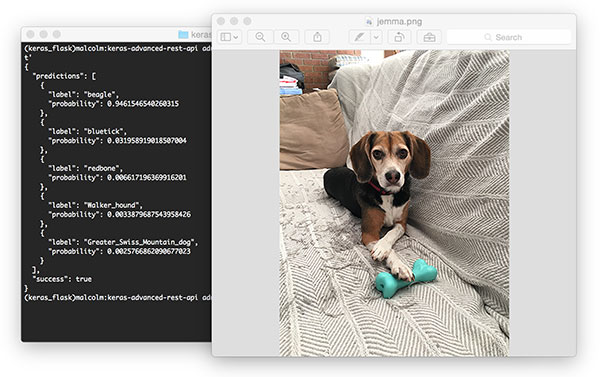
$ curl -X POST -F image=@jemma.png 'http://localhost/predict'
{
"predictions": [
{
"label": "beagle",
"probability": 0.9461532831192017
},
{
"label": "bluetick",
"probability": 0.031958963721990585
},
{
"label": "redbone",
"probability": 0.0066171870566904545
},
{
"label": "Walker_hound",
"probability": 0.003387963864952326
},
{
"label": "Greater_Swiss_Mountain_dog",
"probability": 0.0025766845792531967
}
],
"success": true
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
如果一切正常,您应该会收到来自深度学习 API 模型服务器的格式化 JSON 输出,其中包含类别预测 + 概率。
对您的深度学习 REST API 进行压力测试
当然,这只是一个例子。 让我们对深度学习 REST API 进行压力测试。 打开另一个终端并执行以下命令:
$ python stress_test.py
[INFO] thread 3 OK
[INFO] thread 0 OK
[INFO] thread 1 OK
...
[INFO] thread 497 OK
[INFO] thread 499 OK
[INFO] thread 498 OK
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在 run_model_server.py 输出中,您将开始看到记录到终端的以下行:
* Batch size: (4, 224, 224, 3)
* Batch size: (9, 224, 224, 3)
* Batch size: (9, 224, 224, 3)
* Batch size: (8, 224, 224, 3)
...
* Batch size: (2, 224, 224, 3)
* Batch size: (10, 224, 224, 3)
* Batch size: (7, 224, 224, 3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
即使每 0.05 秒有一个新请求,我们的批次大小也不会超过每批次约 10-12 张图像。 我们的模型服务器可以轻松处理负载而不会出汗,并且可以轻松扩展到此之外。 如果您确实使服务器超载(可能是您的批大小太大并且 GPU 内存不足并显示错误消息),您应该停止服务器,并使用 Redis CLI 清除队列:
$ redis-cli
> FLUSHALL
- 1
- 2
从那里您可以调整 settings.py 和 /etc/apache2/sites-available/000-default.conf 中的设置。 然后您可以重新启动服务器。
将您自己的深度学习模型部署到生产环境的建议
我能给出的最好建议之一是将您的数据,尤其是 Redis 服务器,靠近 GPU。 您可能想启动一个具有数百 GB RAM 的巨型 Redis 服务器来处理多个图像队列并为多个 GPU 机器提供服务。 这里的问题将是 I/O 延迟和网络开销。
假设 224 x 224 x 3 图像表示为 float32 数组,32 张图像的批量大小将是 ~19MB 的数据。 这意味着对于来自模型服务器的每个批处理请求,Redis 将需要提取 19MB 的数据并将其发送到服务器。 在快速切换上,这没什么大不了的,但您应该考虑在同一台服务器上同时运行模型服务器和 Redis,以使数据靠近 GPU。
总结
在今天的博文中,我们学习了如何使用 Keras、Redis、Flask 和 Apache 将深度学习模型部署到生产环境中。 我们在这里使用的大多数工具都是可以互换的。您可以将 TensorFlow 或 PyTorch 换成 Keras。可以使用 Django 代替 Flask。 Nginx 可以换成 Apache。
我不建议换掉的唯一工具是 Redis。 Redis 可以说是内存数据存储的最佳解决方案。除非您有不使用 Redis 的特定原因,否则我建议您使用 Redis 进行排队操作。 最后,我们对深度学习 REST API 进行了压力测试。
我们向我们的服务器提交了总共 500 个图像分类请求,每个请求之间有 0.05 秒的延迟——我们的服务器没有分阶段(CNN 的批量大小从未超过约 37%)。
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/121135129

- 点赞
- 收藏
- 关注作者
评论(0)