Bert实战:使用Bert实现文本分类。

1、简介
最近使用Bert实现了文本分类,模型使用的是bert的base版本。本文记录一下实现过程。
数据集:cnews,包含三个文件,分别是cnews.train.txt、cnews.test.txt、cnews.val.txt。类别包含10类,分别是:体育、娱乐、家居、房产、教育、时尚、时政、游戏、科技、财经。
代码参考:https://github.com/BeHappyForMe/Multi_Model_Classification,对代码的一些部分作了修改和注解。关注公众号“AI小浩”,回复“bert实战”,获取代码和数据集。
2、下载代码和数据集
数据集的地址:
链接:https://pan.baidu.com/s/1JKiaexp0oQeJF02UUX5eSw
提取码:2222
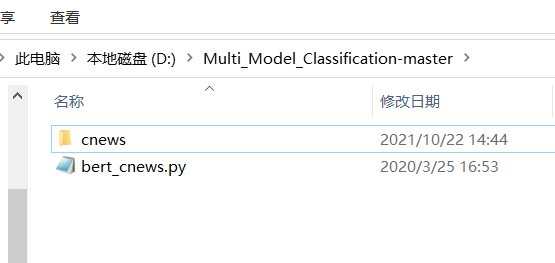
下载代码后,将代码解压到指定的目录,让后将数据集放进去。删除其他的模型只保留bert的。如下图:
安装transformers
pip install transformers
- 1
3、下载预训练模型。
链接:bert-base-chinese at main (huggingface.co),将下图中,画红框的文件下载下来。在项目的根目录新建chinese_wwm_pytorch文件夹,将下载的文件放进去。
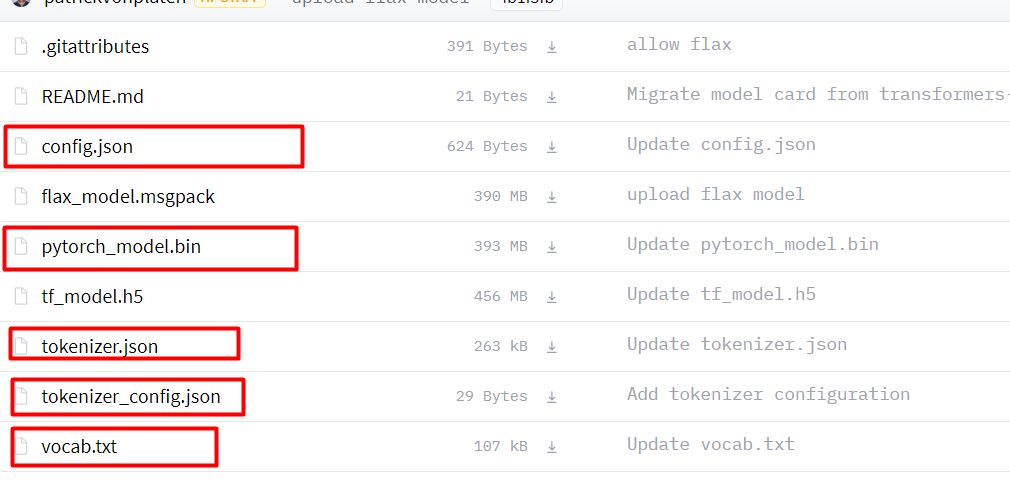
新建outs文件夹,将config.json、tokenizer.json、tokenizer_config.json和vocab.txt复制到outs文件夹中。
注:模型的类型在configuration_bert.py中查看。选择合适的模型很重要,比如这次是中文文本的分类。选择用bert-base-uncased只能得到86%的准确率,但是选用bert-base-chinese就可以轻松达到96%。
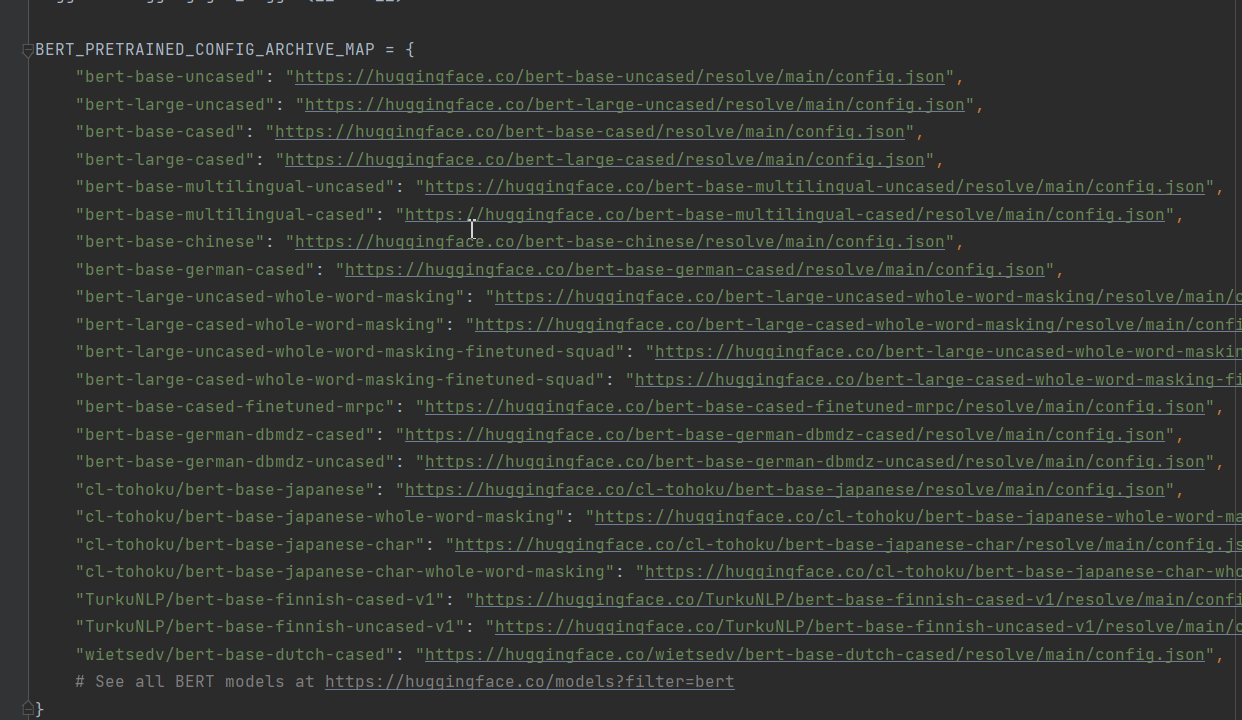
4、修改bert_cnews.py代码
对68行的代码做修改。原始代码如下:
ALL_MODELS = sum((tuple(conf.pretrained_config_archive_map.keys()) for conf in (BertConfig, XLNetConfig, XLMConfig,
RobertaConfig, DistilBertConfig)), ())
- 1
- 2
修改为:
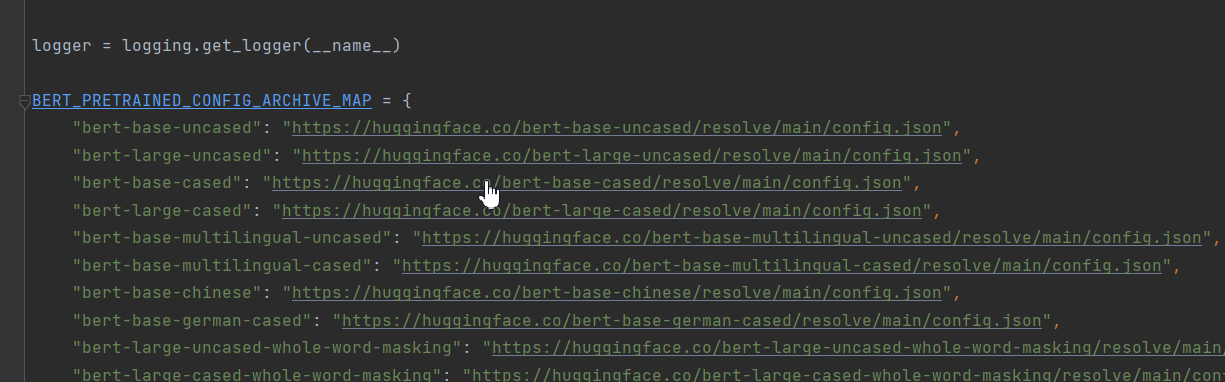
ALL_MODELS=tuple(BERT_PRETRAINED_CONFIG_ARCHIVE_MAP)
- 1
作者想把BertConfig、XLNetConfig、XLMConfig、RobertaConfig, DistilBertConfig等都导进来。可能是版本的升级pretrained_config_archive_map这个字段做了修改,以Bert为例,这个字段改为了‘BERT_PRETRAINED_CONFIG_ARCHIVE_MAP’。本次案例只是对Bert的讲解,所以我只保留了Bert的字段。
5、修改main()方法中的参数。
data_dir:数据集的路径,改为“./cnews”。
parser.add_argument("--data_dir", default='./cnews', type=str, required=False,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.")
- 1
- 2
model_type:模型的类型,MODEL_CLASSES的参数,本次使用bert。
parser.add_argument("--model_type", default='bert', type=str, required=False,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()))
- 1
- 2
- 3
model_name_or_path:预训练模型的存放路径,设置为‘chinese_wwm_pytorch’。
parser.add_argument("--model_name_or_path", default='chinese_wwm_pytorch', type=str, required=False,
help="Path to pre-trained model or shortcut name selected in the list: " + ", ".join(
ALL_MODELS))
- 1
- 2
- 3
这个文件下面的文件详见下图:

task_name:任务名称。我写的cnews
parser.add_argument("--task_name", default='cnews', type=str, required=False,
help="The name of the task to train selected in the list: " + ", ".join(processors.keys()))
- 1
- 2
- 3
do_train:是否训练。需要训练则设置为true。
parser.add_argument("--do_train", default=True,action='store_true',
help="Whether to run training.")
- 1
- 2
do_eval:是否验证,如果设置为true,则将outs的模型一一验证。和do_train可以同时配置为true,这样训练完成后就开始验证。
parser.add_argument("--do_eval",default=True, action='store_true',
help="Whether to run eval on the dev set.")
- 1
- 2
evaluate_during_training:是否在训练期间验证。默认没有配置。如果需要配置,则将其设置为true。
parser.add_argument("--evaluate_during_training", action='store_true',
help="Rul evaluation during training at each logging step.")
- 1
- 2
do_lower_case:是否转小写。使用uncased模型时需要设置。
parser.add_argument("--do_lower_case",action='store_true',
help="Set this flag if you are using an uncased model.")
- 1
- 2
per_gpu_train_batch_size和per_gpu_eval_batch_size:batch_size大小,根据显卡合理设置。
parser.add_argument("--per_gpu_train_batch_size", default=4, type=int,
help="Batch size per GPU/CPU for training.")
parser.add_argument("--per_gpu_eval_batch_size", default=4, type=int,
help="Batch size per GPU/CPU for evaluation.")
- 1
- 2
- 3
- 4
learning_rate:学习率,默认设置即可。
parser.add_argument("--learning_rate", default=2e-5, type=float,
help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float,
- 1
- 2
- 3
num_train_epochs:epochs大小。
parser.add_argument("--num_train_epochs", default=50.0, type=float,
help="Total number of training epochs to perform.")
- 1
- 2
save_steps:迭代多少次保存一次模型。
parser.add_argument('--save_steps', type=int, default=12500,
help="Save checkpoint every X updates steps.")
- 1
- 2
上面的参数是比较重要的参数,将这些参数配置好可以训练了。
5、验证
验证还有一步要做,config.json、tokenizer.json、tokenizer_config.json、vocab.txt。复制一份到outs文件夹。
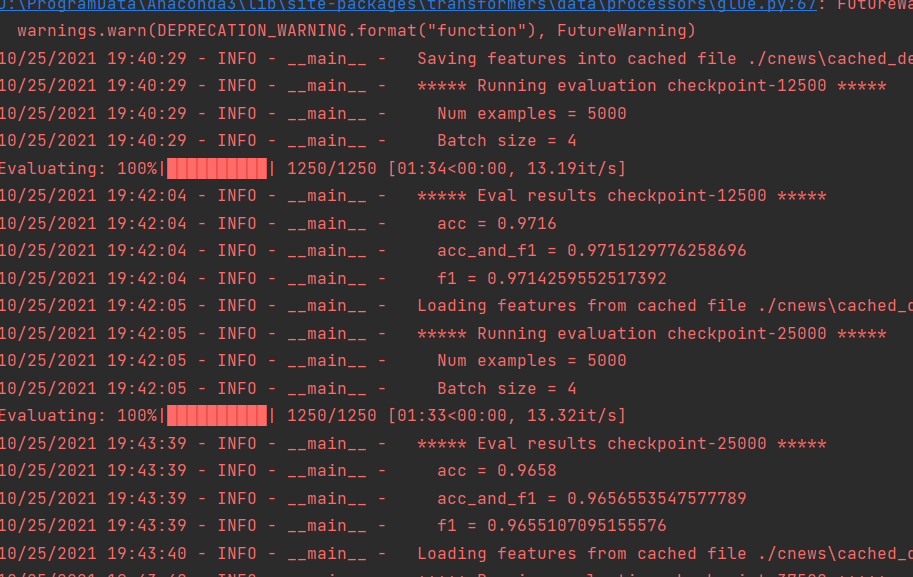
等训练完成就可以测试了。
关注公众号“AI小浩”,回复‘bert分类’,获取代码、模型和数据。
文章来源: wanghao.blog.csdn.net,作者:AI浩,版权归原作者所有,如需转载,请联系作者。
原文链接:wanghao.blog.csdn.net/article/details/120959018

- 点赞
- 收藏
- 关注作者
评论(0)