Netty基础必备知识,ByteBuffer和ByteBuf底层原理

前言
本文章只讨论ByteBuffer和ByteBuf的底层结构的区别,如果想要了解堆内内存和堆外内存的区别,请看我的另一篇文章:java堆外内存详解(又名直接内存)和ByteBuffer
什么是Buffer
中文称为缓冲区,指的是从网络或者文件读写数据的时候,在他们中间多了个缓冲区,应用程序只需要对着缓冲区 进行读写即可;然后缓冲区在将数据复制到内核或者从内核读取数据;这种方式加快读写速度,减少了IO次数;小文件的读写用不用缓冲区速度都没有多大区别,但是当我们进行大文件进行读写的时候一般都会使用到缓冲区;读写效率会以倍数增长;
为什么需要Buffer
在我们刚学习IO的时候,写入文件都是使用FileInputStream或者FileOutputStream类来读取/写入,但是这种方式是你每调用一次write()或者read()方法都是直接将数据写到到内核中,再由内核复制到磁盘中,每次都需要在内核态和用户态频繁切换,这些切换的工作都是需要系统资源开销的,特别是切换太频繁的话,读写效率就会下降;所以这边会推荐大家使用BufferedOutputStream,当缓冲区的数据大小到达8KB时才会写入文件;
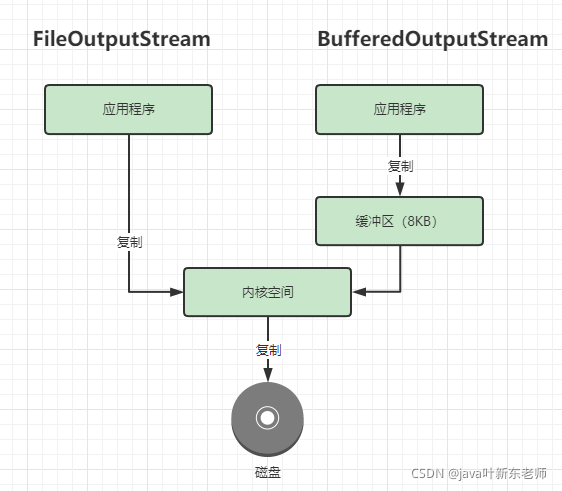
ByteBuffer
当我们在文件或者网络进行数据传输的时候,往往需要使用到缓冲区,常用的缓冲区就是JDK NIO类库提供的java.nio.Buffer;基本上每个基本的数据类型都有缓冲区(Boolean除外)
java.nio.ByteBuffer;
java.nio.CharBuffer;
java.nio.DoubleBuffer;
java.nio.FloatBuffer;
java.nio.IntBuffer;
java.nio.LongBuffer;
java.nio.ShortBuffer;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
一般来说,ByteBuffer 就已经能够满足IO的编程需要了,ByteBuffer 是java NIO(new IO)自带的类,主要有以下特点:
- 长度一旦设定,不可扩容或收缩,要扩容只能创建一个新的ByteBuffer 对象;
- ByteBuffer 内部有一个指针位置position,通过移动指针可实现灵活的读写功能,读写时可通过调用
flip()方法进行翻转指针位置; - 支持堆内和堆外分配;
- 使用者必须小心谨慎地处理这些API,否则很容易导致程序处理失败;
ByteBuffer 内部结构
ByteBuffer 内部有一个byte[]数组,我们添加进去的字节就是加入到这个数组里面的,除此之外,内部还维护了4个指针
position:默认为0;当前下标的位置,表示下一个读/写的起始位置,每写一个字节 或者每读一个字节 position就 + 1;capacity:缓冲区大小,也就是数组的大小,一旦指定,不可修改;limit:结束标记位置,表示进行下一个读写操作时的结束位置;mark: 用户可通过调用mark()方法标记position的当前位置,标记后,在后面的读写发生问题时可通过调用reset()方法回退到标记位置;
代码示例
@Test
public void main() {
// 如果添加的元素超过buffer大小,会抛出BufferOverflowException异常
ByteBuffer buffer = ByteBuffer.allocate(10);
showPosition(buffer);
// 将2个字节的数据写入缓冲区
buffer.put((byte) 34);
buffer.put((byte) 78);
showPosition(buffer);
buffer.flip();// 翻转后可进行读取
//初始化字节数组,用来读取内存
byte[] bytes = new byte[buffer.limit()];
// 进行读取
buffer.get(bytes);
// 讲读取到的内容打印出来
System.out.println(Arrays.toString(bytes));
showPosition(buffer);
// 清除缓冲区,此方法并不是直接清楚buffer内的数组内容,而是将position和limit复位
buffer.clear();
showPosition(buffer);
}
// 显示位置
public void showPosition(ByteBuffer buffer) {
// position 默认为0;当前下标的位置,表示下一个读/写的起始位置,每写一个字节 position就+1;
System.out.println("position 当前位置:" + buffer.position());
// capacity 缓冲区的大小,一旦指定,不可修改;
System.out.println("capacity 缓冲区大小:" + buffer.capacity());
// limit 结束标记位置,表示进行下一个读写操作时的结束位置;
System.out.println("limit 结束标记位置:" + buffer.limit());
try {
// 打印mark 标记位置,mark在Buffer抽象类中,且是私有属性,所以通过反射获取
Field mark = Buffer.class.getDeclaredField("mark");
mark.setAccessible(true);
System.out.println("mark 标记位置:" + mark.get(buffer));
} catch (Exception e) {
e.printStackTrace();
}
System.out.println();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
运行后,打印结果如下,这边就可以看到每走一步后具体的位置下标了,mark标记的值为-1,是因为在代码中并没有调用mark()进行标记了所以为-1;
position 当前位置:0
capacity 缓冲区大小:10
limit 结束标记位置:10
mark 标记位置:-1
position 当前位置:2
capacity 缓冲区大小:10
limit 结束标记位置:10
mark 标记位置:-1
[34, 78]
position 当前位置:2
capacity 缓冲区大小:10
limit 结束标记位置:2
mark 标记位置:-1
position 当前位置:0
capacity 缓冲区大小:10
limit 结束标记位置:10
mark 标记位置:-1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
什么?看不懂? 没关系,我画图给你看,走了每一行代码之后内部结构的变化
1、初始化:ByteBuffer buffer = ByteBuffer.allocate(10)
创建一个堆内内存的ByteBuffer 实例,缓冲区大小为10,此时数组内还没有数据,position 指针在0的位置,所以目前数组内的数据都为0;
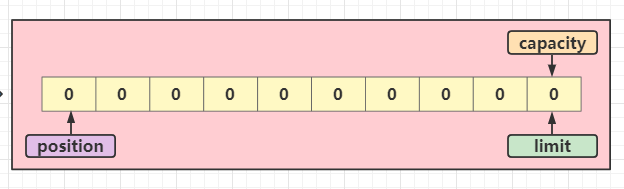
2、写入:buffer.put(byte)
在这一环节中往缓冲区写入了2个字节;
buffer.put((byte) 34);
buffer.put((byte) 78);
- 1
- 2
写完后,position向右移动了2个位置,表示写到了某位置,下次写一个字节时就会往当前的position位置上写入;
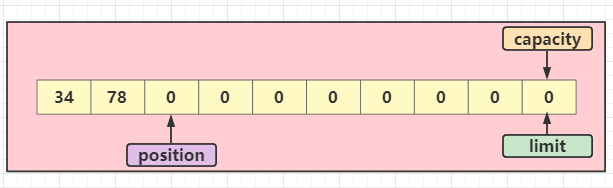
3、翻转:buffer.flip()
如果需要进行读取了,就可以调用翻转方法,翻转后,position的位置又回到了第一个位置,并且limit结束符也到了第2个位置(从0开始算),需要注意的是:如果现在读取或者写入超过了2个字节,将会抛出异常:BufferOverflowException,因为不管在任何情况下,都不能写入或读取超过(limit - position)个字节
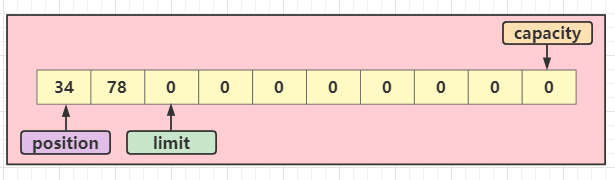
4、读取:buffer.get(bytes)
此时position的位置已经在第一个上面了,所以读取也是从第一个进行读取的,注意:如果现在写入新的字节,将会覆盖之前写入的数据;
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
System.out.println(Arrays.toString(bytes));
- 1
- 2
- 3
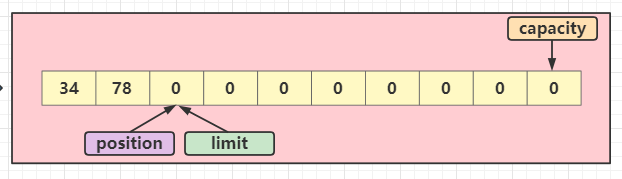
5、清除缓冲区:buffer.clear()
清除缓冲区,clear()方法并不是直接清楚buffer内的数组内容,而是将position和limit复位,position会回到0的位置,limit也会回到数组末尾位置;刚刚加入的数据还是存在数组内部的;
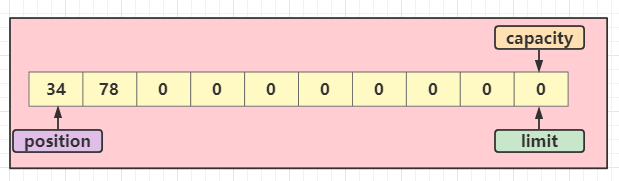
拷贝 duplicate()
内部还提供了一个方法可以讲缓冲区进行拷贝,但是这个拷贝后内部的数组和源对象的数组其实是共享的,只是重新包装了一下,也就是位置变量(position、limit)不同而已,
ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.put((byte) 34);
buffer.put((byte) 78);
// 拷贝
ByteBuffer duplicate = buffer.duplicate();
buffer.put((byte) 77);
buffer.put((byte) 77);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
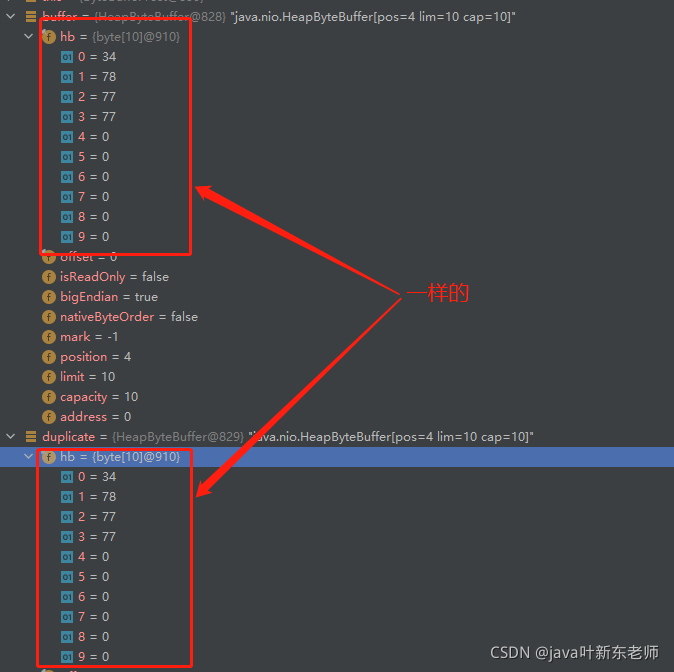
执行后看下图,两个数组的地址是一样的;
flip()和rewind()的区别
看源码就可以得知,flip()只是多了一个结束位的配置,因为limit是限制位,也就是说调用了flip()后可以写入或者读取的数据是根据当前的position来决定的,而rewind()方法则可以写完或者读完数组中的所有内容;
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
public final Buffer rewind() {
position = 0;
mark = -1;
return this;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
ByteBuf
ByteBuf是Netty通过ByteBuffer的原理自己封装的一个类,使用时必须先加入netty依赖才可使用;
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.49.Final</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
ByteBuf 和 ByteBuffer的区别
- 和ByteBuffer最大的区别就是ByteBuf的读写指针是分开的,也就是说ByteBuf内部有一个读指针(
readerIndex)和一个写指针(writerIndex),因此读写时不需要翻转指针;而ByteBuffer只有一个position指针,读写需要调用flip()或者rewind()方法进行翻转; - 和ByteBuffer一样,ByteBuf也支持堆内内存和直接内存的分配,且直接内存都是用Unsafe类实现的;
- 和ByteBuffer最大的不同,就是ByteBuf支持内存池,了解过数据库连接池和线程池的童鞋肯定不陌生,内存池的设计可以加快效率和提高减少资源消耗;
初始化ByteBuf
实例化ByteBuf有四种方式,分别是
- 堆内非池化
- 堆内池化
- 堆外非池化
- 堆外池化
在java代码种实例化方式如下
// 堆内非池化
public ByteBuf heapInnerUnpool(){
return UnpooledByteBufAllocator.DEFAULT.heapBuffer(10,100);
}
// 堆内池化
public ByteBuf heapInnerPool(){
return PooledByteBufAllocator.DEFAULT.heapBuffer(10,100);
}
//堆外非池化
public ByteBuf heapOutUnpool(){
return UnpooledByteBufAllocator.DEFAULT.buffer(10,100);
}
//堆外池化
public ByteBuf heapOutPool(){
return PooledByteBufAllocator.DEFAULT.buffer(10,100);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
ByteBuf 内存池
什么是内存池
从netty 4开始,netty加入了内存池管理,采用内存池管理比普通的ByteBuf性能提高了数十倍;这也是为什么netty快的原因,ByteBuf 支持2种模式,池化和非池化, 池化就是使用内存池,非池化就是不使用内存池,这个很好理解。
为什么要使用内存池
- 在未使用池化之前,每次创建一个ByteBuf 都都需要先向操作系统申请一块内存,并且为这个对象进行
实例化→初始化→引用赋值;这些过程都是需要消耗CPU资源的; - 将ByteBuf池化之后,只有第首次创建对象会进行
实例化→初始化→引用赋值,默认大小16MB,以后使用的时候就直接使用首次创建的对象就可以了;
验证内存池
现在我们来做一个试验,创建2个池化的ByteBuf对象,看看内部是否使用同一块内存空间
ByteBuf byteBuf_one = PooledByteBufAllocator.DEFAULT.heapBuffer(10, 20);
ByteBuf byteBuf_two = PooledByteBufAllocator.DEFAULT.heapBuffer(20, 40);
- 1
- 2
在idea上使用debug功能后发现,在memory这个属性里面存放就是byte[]数组,而byteBuf_one和byteBuf_two 使用的内存地址都是相同的,这足以证明它们使用的是同一块内存地址;
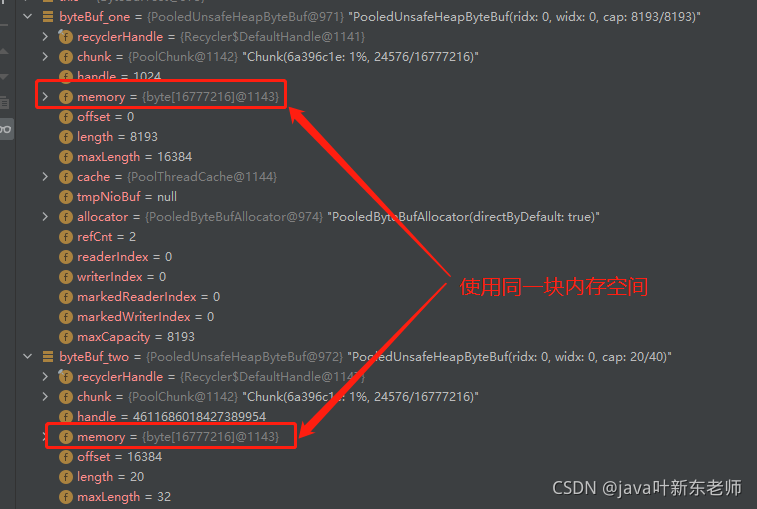
除此之外,在上图种我们还看到一个offset的属性,这个属性就是偏移量,在一个内存池中默认给每个ByteBuf 分配了8192byte的空间,也就是说内存池中0 - 8191 是分配给 byteBuf_one的,而 8192 - 16383 是分配给byteBuf_two的;
读写示例
我们将测试以下代码,并且画出内部结构图,并且分析每一行代码的走向,准备好了吗?
@Test
public void test(){
// 使用内存池
ByteBuf buffer = PooledByteBufAllocator.DEFAULT.buffer(10,10);
print(buffer);
buffer.writeBytes(new byte[]{1,2,3,4,5});
print(buffer);
// 读取2个字节
byte[] bytes = new byte[2];
buffer.readBytes(bytes, buffer.readerIndex(), 2);
System.out.println(Arrays.toString(bytes));
print(buffer);
// 丢弃已读字节;
buffer.discardReadBytes();
print(buffer);
// 设置读取位置,从0开始,相当于设置ByteBUffer的position值
buffer.readerIndex(2);
print(buffer);
// 释放内存空间
buffer.release();
}
//打印 ByteBuf 信息
public void print(ByteBuf buf){
System.out.println("默认大小:"+buf.capacity());
System.out.println("最大值:"+buf.maxCapacity());
System.out.println("是否可读:"+buf.isReadable());
System.out.println("可读的字节数:"+buf.readableBytes());
System.out.println("读的位置:"+buf.readerIndex());
System.out.println("是否可写:"+buf.isWritable());
System.out.println("可写字节的字节数:"+buf.writableBytes());
System.out.println("写的位置:"+buf.writerIndex());
System.out.println("是否堆外分配:"+buf.isDirect());
System.out.println("-------------------------");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
打印结果如下
默认大小:10
最大值:10
是否可读:false
可读的字节数:0
读的位置:0
是否可写:true
可写字节的字节数:10
写的位置:0
是否堆外分配:true
-------------------------
默认大小:10
最大值:10
是否可读:true
可读的字节数:5
读的位置:0
是否可写:true
可写字节的字节数:5
写的位置:5
是否堆外分配:true
-------------------------
[1, 2]
默认大小:10
最大值:10
是否可读:true
可读的字节数:3
读的位置:2
是否可写:true
可写字节的字节数:5
写的位置:5
是否堆外分配:true
-------------------------
默认大小:10
最大值:10
是否可读:true
可读的字节数:3
读的位置:0
是否可写:true
可写字节的字节数:7
写的位置:3
是否堆外分配:true
-------------------------
默认大小:10
最大值:10
是否可读:true
可读的字节数:1
读的位置:2
是否可写:true
可写字节的字节数:7
写的位置:3
是否堆外分配:true
-------------------------
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
接下来我们开始分析ByteBuf内部结构走向
1、实例化:ByteBuf buffer = PooledByteBufAllocator.DEFAULT.buffer(10,10)
因为我们用到了PooledByteBufAllocator,所以这里使用的是内存池;效率更快,这行代码是实例化了ByteBuf,创一个堆外分配的对象;虽然我们只用到了10个字节,但是内存池给这个实例分配了8192byte的字节空间;所以 0 ~ 8191 的字节是给ByteBuf 占用了的;
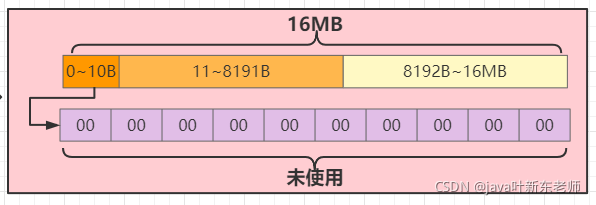
2、写入缓冲区:buffer.writeBytes(new byte[]{1,2,3,4,5})
这行代码很简单,就是往缓冲区写入了5个字节,写入后,结构如下
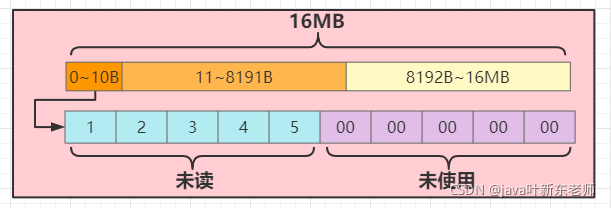
3、读取2字节:buffer.readBytes(bytes, buffer.readerIndex(), 2)
读取2个字节内容,并打印出来;这边读取到的内容为 1和2,也就是前2个元素
byte[] bytes = new byte[2];
// 将读取到的内容放入bytes,第二个参数是读取的起始位置,第三个参数是你需要读取几个字节的数据;注意不要超过最大容量;
buffer.readBytes(bytes, buffer.readerIndex(), 2);
System.out.println(Arrays.toString(bytes));
- 1
- 2
- 3
- 4
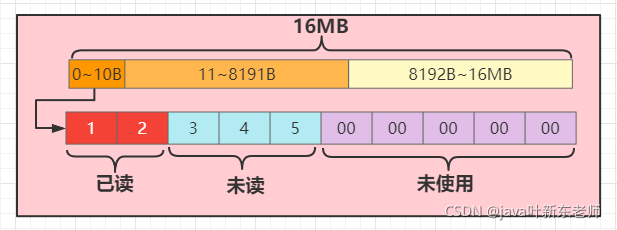
4、丢弃已读字节:buffer.discardReadBytes();
这个方法会将已读的字节删除,过程中需要的开销应该会比较大,基于数组的特性,插入删除比较慢,因为得需要移动比较多的元素指针,删除后结构如下图:
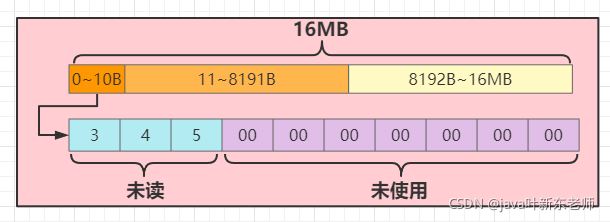
5、自定义读取位置:buffer.readerIndex(2);
这种方法相当于设置ByteBUffer的position值,这边将读取位置指向了2的位置,所以2之前的位置就会被认为是已经读取过了;
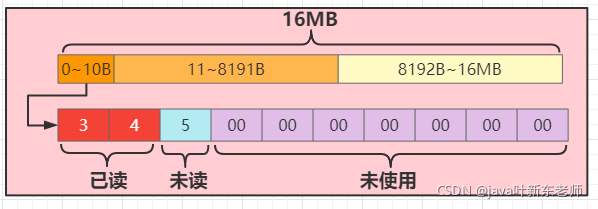
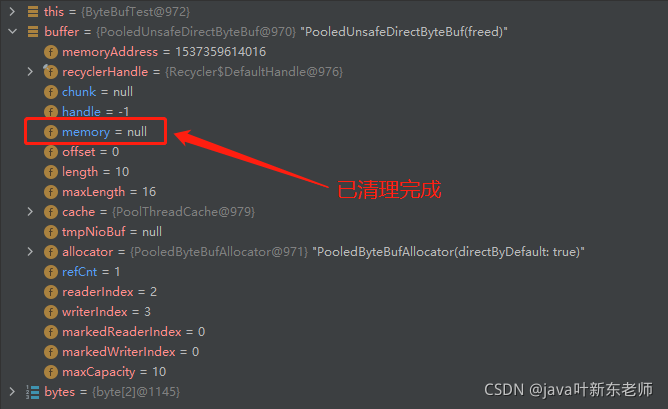
6、释放缓冲区:buffer.release()
因为是内存池堆外分配的,所以每次用完之后都需要手动释放,释放后,内部的memory数组就是空的了,表示已经被释放成功了,这时候这个变量就不能在使用了,会等待垃圾回收将其清理;
动态扩容
ByteBuf 在实例化时有2个参数,初始容量(initialCapacity)和 最大容量(maxCapacity),也就是说,实例化后,缓冲区的容量就是10,当你写入的字节数超过10个时(比如11)就会进行扩容;
int initialCapacity = 10;
int maxCapacity = 20;
UnpooledByteBufAllocator.DEFAULT.heapBuffer(initialCapacity ,maxCapacity );
- 1
- 2
- 3
如何扩容?
知道ByteBuf会扩容,那它是什么时候进行扩容呢?每次扩多少呢?其实啊,ByteBuf 没有负载因子一说,只有当容量不足时才会扩容;如果你的容量为10,而你写入的字节数也是10,那么这种情况不会进行扩容,当你的字节数到达11个时才会扩容;如果你的最大容量是20,那么它就会扩到20;
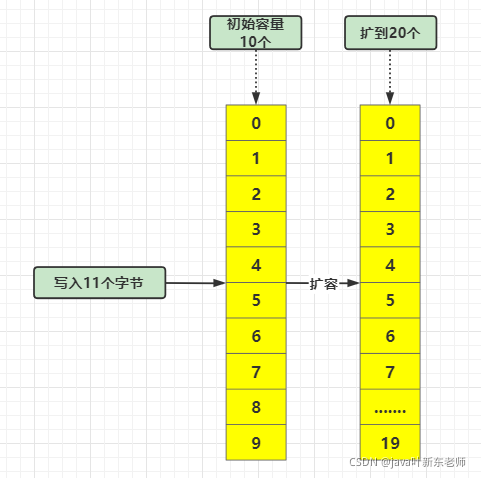
如果我的最大容量有511呢?
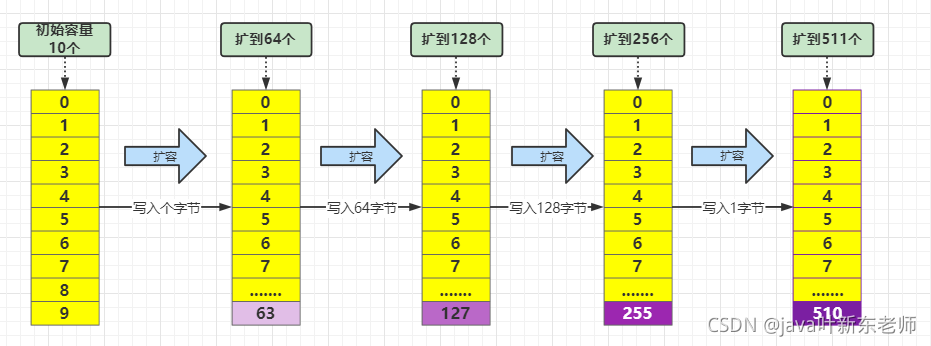
当容量不足64时,会扩容到64,以后开始从64字节每次增加2倍,以下面的代码为例
ByteBuf byteBuf = UnpooledByteBufAllocator.DEFAULT.heapBuffer(10, 511);
System.out.println("初始容量:"+byteBuf.capacity() + ",当前已写入字节数:"+byteBuf.writerIndex());
byteBuf.writeBytes( new byte[64]);
System.out.println("第一次扩容,写入64字节 ,当前容量:"+byteBuf.capacity() + ",当前已写入字节数: "+byteBuf.writerIndex());
byteBuf.writeBytes( new byte[64]);
System.out.println("第二次扩容,写入64字节 ,当前容量:"+byteBuf.capacity() + ",当前已写入字节数:"+byteBuf.writerIndex());
byteBuf.writeBytes( new byte[128]);
System.out.println("第三次扩容,写入128字节,当前容量:"+byteBuf.capacity() + ",当前已写入字节数:"+byteBuf.writerIndex());
byteBuf.writeBytes( new byte[1]);
System.out.println("第四次扩容,写入1字节 ,当前容量:"+byteBuf.capacity() + ",当前已写入字节数:"+byteBuf.writerIndex());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
打印结果如下
初始容量:10,当前已写入字节数:0
第一次扩容,写入64字节 ,当前容量:64,当前已写入字节数: 64
第二次扩容,写入64字节 ,当前容量:128,当前已写入字节数:128
第三次扩容,写入128字节,当前容量:256,当前已写入字节数:256
第四次扩容,写入1字节 ,当前容量:511,当前已写入字节数:257
- 1
- 2
- 3
- 4
- 5
扩容时序图如下
mark标记和回退
ByteBuffer和ByteBuf都支持标记,只是用法不同而已,进行标记后,不管你下一步是读还是写,执行reset()方法后都能回到标记位置;
ByteBuffer标记
ByteBuffer buffer = ByteBuffer.allocate(10);
// 将数据写入缓冲区
buffer.put((byte) 34);
buffer.put((byte) 78);
// 标记当前位置
buffer.mark();
// 继续写入
buffer.put((byte) 96);
// 回退到标记位置
buffer.reset();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
ByteBuf标记
ByteBuf byteBuf = UnpooledByteBufAllocator.DEFAULT.heapBuffer(10, 511);
// 标记读的位置
byteBuf.markReaderIndex();
// 标记写的位置
byteBuf.markWriterIndex();
// 回退到读的标记位置
byteBuf.resetReaderIndex();
//回退到写的标记位置
byteBuf.resetWriterIndex();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
文章来源: yexindong.blog.csdn.net,作者:java叶新东老师,版权归原作者所有,如需转载,请联系作者。
原文链接:yexindong.blog.csdn.net/article/details/120924595

- 点赞
- 收藏
- 关注作者
评论(0)