python基本数据结构与刷题总结

数据结构必刷类别


1.基本数据结构用法:
heapq, sorted, PriorityQueue default_dict 计数器(Counter)bisect二分查找 String 常见字符串操作
heapq:
这个模块提供了堆队列算法的实现,也称为优先队列算法。它使用了数组来实现:从零开始计数,对于所有的 k ,都有 heap[k] <= heap[2k+1] 和 heap[k] <= heap[2k+2]。 为了便于比较,不存在的元素被认为是无限大。 堆最有趣的特性在于最小的元素总是在根结点:heap[0]。这个模块最常用的是将一个列表转换为一个堆,默认是小根堆(它的每个父节点的值都只会小于或所有孩子节点(的值)),而且常用的主要有三个方法:
① heapq.heappush(heap, item):将 item 的值加入 heap 中,保持堆的不变性
② heapq.heappop(heap):弹出并返回 heap 的最小的元素,保持堆的不变性。如果堆为空,抛出 IndexError 。使用 heap[0] ,可以只访问最小的元素而不弹出它
③ heapq.heapify(x):将list x 转换成堆,原地,线性时间内
此外还有
4)heapq.heappushpop(heap, item) 在堆上推送项目,然后弹出并返回堆中的最小项目
5)heapq.heapreplace(heap, item) 弹出并返回堆中的最小项,并同时推送新项,堆大小不会改变,如果堆为空,IndexError则引发,注意:返回的值可能大于添加的项目
6)heapq.merge(<*iterables>,key = None,reverse = False)将多个已排序的输入合并为单个排序的输出
7)heapq.nlargest(n, iterable, key = None)返回一个列表,其中包含iterable定义的数据集中的n个最大元素
8)heapq.nsmallest(n, iterable, key = None)返回一个列表,其中包含iterable定义的数据集中的n个最小元素
import heapq
# heapq有两种方式创建堆, 一种是使用一个空列表,然后使用heapq.heappush()函数把值加入堆中
#第一种:
nums = [2, 3, 5, 1, 54, 23, 132]
heap = []
for num in nums:
heapq.heappush(heap, num) # 加入堆
print(heap[0]) # 如果只是想获取最小值而不是弹出,使用heap[0]
# out: 1
print([heapq.heappop(heap) for _ in range(len(nums))]) # 堆排序结果
# out: [1, 2, 3, 5, 23, 54, 132]
# 第二种
nums2 = [2, 3, 5, 1, 54, 23, 132]
heapq.heapify(nums2) #转换成堆特性
print([heapq.heappop(nums2) for _ in range(len(nums2))]) # 堆排序结果
# out: [1, 2, 3, 5, 23, 54, 132]
# heapq 模块还有一个heapq.merge(*iterables) 方法,用于合并多个排序后的序列成一个排序后的序列, 返回排序后的值的迭代器。
# 类似于sorted(itertools.chain(*iterables)),但返回的是可迭代的。
import heapq
num1 = [32, 3, 5, 34, 54, 23, 132]
num2 = [23, 2, 12, 656, 324, 23, 54]
num1 = sorted(num1)
num2 = sorted(num2)
res = heapq.merge(num1, num2)
print(list(res))
#out:[2, 3, 5, 12, 23, 23, 23, 32, 34, 54, 54, 132, 324, 656]
# 访问堆内容
# 堆创建好后,可以通过heapq.heappop() 函数弹出堆中最小值。
import heapq
nums = [2, 43, 45, 23, 12]
heapq.heapify(nums)
print(heapq.heappop(nums))
# out: 2
# 如果需要所有堆排序后的元素
result = [heapq.heappop(nums) for _ in range(len(nums))]
print(result)
# out: [12, 23, 43, 45]
# 如果需要删除堆中最小元素并加入一个元素,可以使用heapq.heaprepalce() 函数
import heapq
nums = [1, 2, 4, 5, 3]
heapq.heapify(nums)
heapq.heapreplace(nums, 23)
print([heapq.heappop(nums) for _ in range(len(nums))])
# out: [2, 3, 4, 5, 23]
# 获取堆最大或最小值
# 如果需要获取堆中最大或最小的范围值,则可以使用heapq.nlargest() 或heapq.nsmallest() 函数
import heapq
nums = [1, 3, 4, 5, 2]
print(heapq.nlargest(3, nums))
print(heapq.nsmallest(3, nums))
#out:
#[5, 4, 3]
#[1, 2, 3]
# 这两个函数还接受一个key参数,用于dict或其他数据结构类型使用
import heapq
from pprint import pprint
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
cheap = heapq.nsmallest(3, portfolio, key=lambda s: s['price'])
expensive = heapq.nlargest(3, portfolio, key=lambda s: s['price'])
pprint(cheap)
pprint(expensive)
#out:
[{'name': 'YHOO', 'price': 16.35, 'shares': 45},
{'name': 'FB', 'price': 21.09, 'shares': 200},
{'name': 'HPQ', 'price': 31.75, 'shares': 35}]
[{'name': 'AAPL', 'price': 543.22, 'shares': 50},
{'name': 'ACME', 'price': 115.65, 'shares': 75},
{'name': 'IBM', 'price': 91.1, 'shares': 100}]
692. 前K个高频单词
# 给一非空的单词列表,返回前 k 个出现次数最多的单词。
# 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
# 示例 1:
# 输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
# 输出: ["i", "love"]
# 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
# 注意,按字母顺序 "i" 在 "love" 之前。
# 示例 2:
# 输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
# 输出: ["the", "is", "sunny", "day"]
# 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
# 出现次数依次为 4, 3, 2 和 1 次。
from collections import Counter
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
data = Counter(words)
data2 = sorted(data.items(), key= lambda x : (-x[1], x[0]))
count = 0
res = []
for i in range(len(data2)):
count += 1
if count <= k:
res.append(data2[i][0])
return res
sorted用法(list)
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法:
sorted(iterable, cmp=None, key=None, reverse=False)
参数说明:
- iterable – 可迭代对象。
- cmp – 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
- key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
- reverse – 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回重新排序的列表。
# 用reverse排序
# 就相当于反顺序排列
arr = [4,3,6,5,1,8,7]
sorted(arr,reverse=True)
#out:[8, 7, 6, 5, 4, 3, 1]
sorted(arr)
#out:[1, 3, 4, 5, 6, 7, 8]
1.高级用法
# 有时候,我们要处理的数据内的元素不是一维的,而是二维的甚至是多维的,那要怎么进行排序呢?这时候,sorted()函数内的key参数就派上用场了!
# 从帮助信息上可以了解到,key参数可传入一个自定义函数
arr=[('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
print(sorted(arr, key=lambda x:x[0]))
sorted(arr, key=lambda x:x[1])
#out:
#[('a', 1), ('b', 2), ('c', 6), ('d', 4), ('e', 3)]
#[('a', 1), ('b', 2), ('e', 3), ('d', 4), ('c', 6)]
sorted(arr, key=lambda x:x[1], reverse=True)
#out:
#[('c', 6), ('d', 4), ('e', 3), ('b', 2), ('a', 1)]
2.其他用法
#这是默认以字符进行排序的,而我们期望的结果往往是类似于['b1', 'b2', 'b3', 'b11', 'b21']的自然排序结果。这里就可以用key来调整
b = ['b1', 'b2', 'b3', 'b11', 'b21']
sorted(b, key=lambda n : int(n[1:]))
#out:['b1', 'b2', 'b3', 'b11', 'b21']
#key也可用来控制排序的对象
members = [('Mark', 30, 12000), ('John', 24, 6000), ('Tim', 27, 8000), ('David', 26, 10000)]
sorted(members)
#out:
[('David', 26, 10000),
('John', 24, 6000),
('Mark', 30, 12000),
('Tim', 27, 8000)]
sorted(members, key=lambda n: n[2])
#out:
[('John', 24, 6000),
('Tim', 27, 8000),
('David', 26, 10000),
('Mark', 30, 12000)]
#上例就是按收入(成员第3项)进行排序的。也可以先按年龄,再按收入进行排序
sorted(members, key=lambda n: (n[1], n[2]))
#out:
[('John', 24, 6000),
('David', 26, 10000),
('Tim', 27, 8000),
('Mark', 30, 12000)]
例子
3.通过内置库from operator import itemgetter, attrgetter的骚操作
from operator import itemgetter, attrgetter
members = [('Mark', 30, 12000), ('John', 24, 6000), ('Tim', 27, 8000), ('David', 26, 10000)]
sorted(members, key=itemgetter(1))
#out:
[('John', 24, 6000),
('David', 26, 10000),
('Tim', 27, 8000),
('Mark', 30, 12000)]
# operator.itemgetter函数
# operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为一些序号。看下面的例子
import operator
a = [1,2,3]
b=operator.itemgetter(1) #定义函数b,获取对象的第1个域的值
b(a)
#out:2
b=operator.itemgetter(1,0) # 定义函数b,获取对象的第1个域和第0个的值
b(a)
#out:(2, 1)
# 要注意,operator.itemgetter函数获取的不是值,而是定义了一个函数,通过该函数作用到对象上才能获取值。
# sorted函数用来排序,sorted(iterable[, cmp[, key[, reverse]]])
# 其中key的参数为一个函数或者lambda函数。所以itemgetter可以用来当key的参数
students = [('john', 'A', 15), ('jane', 'B', 12), ('dave', 'B', 10)]
# 根据第二个域和第三个域进行排序
sorted(students, key=operator.itemgetter(1,2))
#out:[('john', 'A', 15), ('dave', 'B', 10), ('jane', 'B', 12)]
# operator.attrgetter()
# 返回:返回从其操作数获取attr的可调用对象。如果请求多个属性,则返回属性元组
class Teacher():
def __init__(self, name, salary, age):
self.name = name
self.age = age
self.salary = salary
def __repr__(self): # repr() 函数将对象转化为供解释器读取的形式。
return repr((self.name,self.age,self.salary))
teachers = [
Teacher("A",1200,30),
Teacher("B",1200,31),
Teacher("C",1300,30)
]
from operator import attrgetter
print(sorted(teachers,key=attrgetter("age"))) # 根据age排序
print(sorted(teachers,key=attrgetter("salary","age"))) # 根据salary和age排序
# out:
# [('A', 30, 1200), ('C', 30, 1300), ('B', 31, 1200)]
# [('A', 30, 1200), ('B', 31, 1200), ('C', 30, 1300)]
4.涉及字典的排序
# 按照key排序
# 要对字典按照key排序,可以直接调用sorted函数。
my_dict = {'lilee':25, 'age':24, 'phone':12}
sorted(my_dict.keys())
#out:['age', 'lilee', 'phone']
# 按照value值排序
# 共有三种方法可以实现将字典按照value值进行排序
d = {'lilee':25, 'wangyan':21, 'liqun':32, 'age':19}
sorted(d.items(), key=lambda item:item[1])
#out:[('age', 19), ('wangyan', 21), ('lilee', 25), ('liqun', 32)]
sorted(d.items(), key=lambda item:item[0])
#out:[('age', 19), ('lilee', 25), ('liqun', 32), ('wangyan', 21)]
哈希结构 dict和map:
集合set与字典dict,都是以hash值分布存储的,是无序的数据结构
①python中set的值得存储方式也是和dict一样。所以dict的key和set的值都必须是可hash(即不可修改的)的对象。
②dict的花销大,因为会空出进1/3的内存主来,但是查询速度快。
dict是用来存储键值对结构的数据的,set其实也是存储的键值对,只是默认键和值是相同的。Python中的dict和set都是通过散列表来实现的。下面来看与dict相关的几个比较重要的问题:
a.dict中的数据是无序存放的
b.操作的时间复杂度,插入、查找和删除都可以在O(1)的时间复杂度
c.键的限制,只有可哈希的对象才能作为字典的键和set的值。可hash的对象即python中的不可变对象和自定义的对象。可变对象(列表、字典、集合)是不能作为字典的键和st的值的。
d.与list相比:list的查找和删除的时间复杂度是O(n),添加的时间复杂度是O(1)。但是dict使用hashtable内存的开销更大。为了保证较少的冲突,hashtable的装载因子,一般要小于0.75,在python中当装载因子达到2/3的时候就会自动进行扩容。
如果需要有序的字典,在collections模块中有个collections.OrderedDict可参考
默认字典 collections.default_dict
# 默认字典(defaultdict)
# 在Python中字典收集数据通常是很有用的。在字典中获取一个 key 有两种方法, 第一种 get , 第二种 通过 [] 获取.使用dict时,
# 如果引用的Key不存在,就会抛出KeyError。如果希望key不存在时,返回一个默认值,就可以用defaultdict
from collections import defaultdict
# dict1 = {}
# dict1['k1'].append('hello') #正常情况会报错
# print(dict1)
# 使用 list 作为 default_factory,很轻松地将(键-值对组成的)序列转换为(键-列表组成的)字典:
dict = defaultdict(list)
dict['k1'].append('hello')
dict['k1'].append('hello2')
print(dict)
#out:defaultdict(<class 'list'>, {'k1': ['hello', 'hello2']})
values = [11, 12, 14, 19, 20, 33, 44, 55, 66, 78]
my_dict = defaultdict(list)
# 用默认字典精简代码
for value in values:
if value > 66:
my_dict['k1'].append(value)
else:
my_dict['k2'].append(value)
print(my_dict)
#out:defaultdict(<class 'list'>, {'k2': [11, 12, 14, 19, 20, 33, 44, 55, 66], 'k1': [78]})
# 使用 list 作为 default_factory
s = [('yellow', 1), ('blue', 2), ('yellow', 3), ('blue', 4), ('red', 1)]
d = defaultdict(list)
for k, v in s:
d[k].append(v)
sorted(d.items())
#out:[('blue', [2, 4]), ('red', [1]), ('yellow', [1, 3])]
sorted(s, key = lambda x : x[1])
#out:[('yellow', 1), ('red', 1), ('blue', 2), ('yellow', 3), ('blue', 4)]
collections.OrderedDict
# 有序字典-OrderedDict
# 有序词典就像常规词典一样,但有一些与排序操作相关的额外功能。
# 由于内置的 dict 类获得了记住插入顺序的能力(在 Python 3.7 中保证了这种新行为),它们变得不那么重要了。
dict字典
PriorityQueue优先队列
优先队列也是一种抽象数据类型。优先队列中的每个元素都有优先级,而优先级高(或者低)的将会先出队,而优先级相同的则按照其在优先队列中的顺序依次出队。
也就是说优先队列,通常会有下面的操作:
这样的话,我们完全可以使用链表来实现,例如以O(1)复杂度插入,每次在表头插入,而以O(N)复杂度执行删除最小元素;或者以O(N)复杂度插入,保持链表有序,而以O(1)复杂度删除。然而优先队列往往使用堆来实现,以至于通常说堆时,就自然而然地想到了优先队列。
在优先队列中,优先级高的元素先出队列。标准库默认使用元素类型的<操作符来确定它们之间的优先级关系。优先队列和堆一样,也有两种形式:最大优先队列和最小优先队列。下面首先介绍一下优先队列,然后介绍其具体的应用。
一、 优先队列
优先对列(priority queue)是一种用来维护由一组元素构成的集合S的数据结构,其中的每一个元素都有一个相关值,称为关键字(key)。一个最大优先队列支持以下操作:
- push(S, x):把元素x插入集合S中。
- top(S):返回S中具有最大关键字的元素。
- pop(S):去掉S中的具有最大关键字的元素。
下面是一个最大优先队列的结构图,实际上就是一个大顶堆。
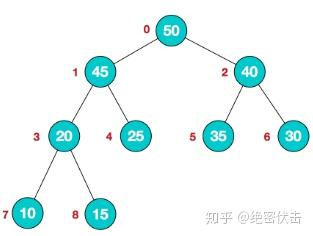
二、最大优先队列应用
- 问题描述
假设有N个降序数组,每个数组有M个元素,现在需要从中取出最大的K个元素,如何解决?
- 具体解法
首先建立一个最大优先队列,初始的时候插入每个数组的首元素,即插入 ![[公式]](https://res-hd.hc-cdn.cn/ecology/9.3.209/v2_resources/ydcomm/libs/images/loading.gif) ,堆顶即为最大的元素,删除堆顶,假设删除的是 ,则第二大的元素出现在 中,因此将 插入优先队列中,重复以上过程,直到输出最大的K个元素。具体步骤如下:
,堆顶即为最大的元素,删除堆顶,假设删除的是 ,则第二大的元素出现在 中,因此将 插入优先队列中,重复以上过程,直到输出最大的K个元素。具体步骤如下:
- 建立最大优先队列,初始为N个数组的首元素
- 删除最大堆堆顶( ),输出到数组中,然后向最大堆插入删除元素所在数组的下一个元素( )
- 重复以上步骤,直到输出K个元素
# 调用方法:
# from queue import PriorityQueue
# 最常用的成员函数
# put(). get()取队首元素的值并将其弹出. 当优先队列为空时,调用get()不会报错,而是会一直等待取出元素,可能和 PriorityQueue
# 支持并发的特性有关. full() 判断是否为满. empty() 判断是否为空.
# que.qsize()优先队列中元素的个数
# que.get()返回根(优先队列第一个出队的元素)
from queue import PriorityQueue
#PriorityQueue创建的是大顶堆,即值越小优先级越高。
customers = PriorityQueue() #we initialise the PQ class instead of using a function to operate upon a list.
# 元组也可以排序。根据元组的第一个值
customers.put((2, "Harry"))
customers.put((3, "Charles"))
customers.put((1, "Riya"))
customers.put((4, "Stacy"))
while not customers.empty():
print(customers.get())
#out:
(1, 'Riya')
(2, 'Harry')
(3, 'Charles')
(4, 'Stacy')
# 自定义优先级
from queue import PriorityQueue
class Skill(object):
def __init__(self, priority, description):
self.priority = priority
self.description = description
def __lt__(self, other):
return self.priority < other.priority
def __str__(self):
return '(' + str(self.priority)+',\'' + self.description + '\')'
def PriorityQueue_class():
que = PriorityQueue()
que.put(Skill(7,'proficient7'))
que.put(Skill(5,'proficient5'))
que.put(Skill(6,'proficient6'))
que.put(Skill(10,'expert'))
que.put(Skill(1,'novice'))
print ('end')
while not que.empty():
print (que.get())
PriorityQueue_class()
#out:
end
(1,'novice')
(5,'proficient5')
(6,'proficient6')
(7,'proficient7')
(10,'expert')
# 从大到小 优先级
items = [3,1,2]
que = PriorityQueue()
for element in items:
que.put((-element,element))
# print (pq.get()[1])
while not que.empty():
print (que.get())
#out:
(-3, 3)
(-2, 2)
(-1, 1)
692. 前K个高频单词
# 给一非空的单词列表,返回前 k 个出现次数最多的单词。
# 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
# 示例 1:
# 输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
# 输出: ["i", "love"]
# 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
# 注意,按字母顺序 "i" 在 "love" 之前。
# 示例 2:
# 输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
# 输出: ["the", "is", "sunny", "day"]
# 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
# 出现次数依次为 4, 3, 2 和 1 次。
from collections import Counter
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
data = Counter(words)
# print(sorted(data.items(), key= lambda x : (-x[1], x[0])))
# data2 = sorted(data.items(), key= lambda x : (-x[1], x[0]))
from queue import PriorityQueue
queues = PriorityQueue()
for key, value in data.items():
queues.put((-value, key))
count = 0
res = []
while not queues.empty():
# print(queues.get())
temp = queues.get()
# print(temp)
# print(temp[1])
count += 1
if count <= k:
res.append(temp[1])
return res
692. 前K个高频单词
# 给一非空的单词列表,返回前 k 个出现次数最多的单词。
# 返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
# 示例 1:
# 输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
# 输出: ["i", "love"]
# 解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
# 注意,按字母顺序 "i" 在 "love" 之前。
# 示例 2:
# 输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
# 输出: ["the", "is", "sunny", "day"]
# 解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
# 出现次数依次为 4, 3, 2 和 1 次。
from collections import Counter
class Solution:
def topKFrequent(self, words: List[str], k: int) -> List[str]:
data = Counter(words)
# print(sorted(data.items(), key= lambda x : (-x[1], x[0])))
# data2 = sorted(data.items(), key= lambda x : (-x[1], x[0]))
from queue import PriorityQueue
queues = PriorityQueue()
for key, value in data.items():
queues.put((-value, key))
count = 0
res = []
while not queues.empty():
# print(queues.get())
temp = queues.get()
# print(temp)
# print(temp[1])
count += 1
if count <= k:
res.append(temp[1])
return res
计数器(Counter)
Counter
Counter作为字典dicit()的一个子类用来进行hashtable计数,将元素进行数量统计,计数后返回一个字典,键值为元素,值为元素个数
常用方法:
| most_common(int) | 按照元素出现的次数进行从高到低的排序,返回前int个元素的字典 |
|---|---|
| elements | 返回经过计算器Counter后的元素,返回的是一个迭代器 |
| update | 和set集合的update一样,对集合进行并集更新 |
| substract | 和update类似,只是update是做加法,substract做减法,从另一个集合中减去本集合的元素 |
| iteritems | 返回由Counter生成的字典的所有item |
| iterkeys | 返回由Counter生成的字典的所有key |
| itervalues | 返回由Counter生成的字典的所有value |
用法和例子
from collections import Counter
c = Counter('gallahas')
print(c)
#out:Counter({'a': 3, 'l': 2, 'g': 1, 'h': 1, 's': 1})
c = Counter({'red' : 4, 'blue' : 2, 'red' : 5})
print(c)
#out:Counter({'red': 5, 'blue': 2})
str = "hello world"
str1 = ['h', 'e', 'l', 'l', 'o', 'w', 'o', 'r', 'l', 'd']
#Counter获取各元素的个数,返回字典
print(Counter(str))
print(Counter(str1))
#out:
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, 'w': 1, 'r': 1, 'd': 1})
#most_common(int)按照元素出现的次数进行从高到低的排序,返回前int个元素的字典
d1 = Counter(str)
print ("str.most_common(2):", d1.most_common(2))
#out:str.most_common(2): [('l', 3), ('o', 2)]
#elements返回经过计算器Counter后的元素,返回的是一个迭代器
print('sorted(d1.elements())', sorted(Counter(str).elements()))
#out:sorted(d1.elements()) [' ', 'd', 'e', 'h', 'l', 'l', 'l', 'o', 'o', 'r', 'w']
#若是字典的话返回value个key
d2 = Counter(str1)
print(d2)
print("若是字典的话返回value个key:", sorted(d2.elements()))
print(d2.keys())
print(d2.values())
#out:
Counter({'l': 3, 'o': 2, 'h': 1, 'e': 1, 'w': 1, 'r': 1, 'd': 1})
若是字典的话返回value个key: ['d', 'e', 'h', 'l', 'l', 'l', 'o', 'o', 'r', 'w']
dict_keys(['h', 'e', 'l', 'o', 'w', 'r', 'd'])
dict_values([1, 1, 3, 2, 1, 1, 1])
bisect二分查找
bisect是 python 的内置模块,主要用来排序,主要方法:
bisect.bisect_left(a, x, lo=0, hi=len(a)) 返回将x插入到列表a中的索引位置,如果已有x,则返回第一个x的位置
bisect.bisect_right(a, x, lo=0, hi=len(a)) 返回将x插入到列表a中的索引位置,如果已有x,则返回最后一个x位置的下一个位置
bisect.bisect(a, x, lo=0, hi=len(a)) 与bisect_right相同
bisect.insort_left(a, x, lo=0, hi=len(a)) 将x插入到列表a中,如果已有x,插入到所有x的最左边
bisect.insort_right(a, x, lo=0, hi=len(a)) 将x插入到列表a中,如果已有x,插入到所有x的最右边
bisect.insort(a, x, lo=0, hi=len(a)) 与insort_right相同
import bisect
nums = [1, 3, 4, 6, 8, 12, 15]
x = 3
#返回将x插入到列表a中的索引位置,如果已有x,则返回第一个x的位置
x_insert_point = bisect.bisect_left(nums, x)
print(x_insert_point)
#out:1
nums = [1, 3, 4, 6, 8, 12, 15]
x = 3
x_insert_point2 = bisect.bisect_right(nums, x)
# 返回将x插入到列表a中的索引位置,如果已有x,则返回最后一个x位置的下一个位置
print(x_insert_point2)
#out:2
x = 3
nums = [1, 3, 4, 6, 8, 12, 15]
x_insert_right = bisect.insort_right(nums, x) #将x插入到列表a中,如果已有x,插入到所有x的最右边
print(nums)
#out:[1, 3, 3, 4, 6, 8, 12, 15]
x = 3.1
nums = [1, 3, 4, 6, 8, 12, 15]
x_insert_right = bisect.insort_left(nums, x) # 将x插入到列表a中,如果已有x,插入到所有x的最左边
print(nums)
#out:[1, 3, 3.1, 4, 6, 8, 12, 15]
String 常见字符串操作:
lines = "Hello.I am qiwsir.Welcome you."
lines.split(".") # 以英文的句点为分隔符,得到list
#out:['Hello', 'I am qiwsir', 'Welcome you', '']
lines.split(".", 1) # 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串
#out:['Hello', 'I am qiwsir.Welcome you.']
list用法:
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
2.刷题时按类别刷 一个种类4-5题,第2周刷第二遍,总结思路代码考前看看(python几行代码解决的也看看)
2.刷题时按类别刷 一个种类4-5题,第二周刷第二遍,总结思路代码考前看看(python几行代码解决的也看看)
系统设计题:
答题思路总结
对于专业级科目一考试,设计类题在考试中前两道中出现,难度也一般为中等,题目形式、答题思路比较固定。
设计题的『设计』在于设计一个『系统』,这个系统有以下特点:
•有输入
•有输出
•输入易处理,输出是难点
•需要进行合理的信息管理
设计的核心在于,设计出合适的数据结构,数据结构设计出来了,题目也就顺手写出来了。为此,总结出四条建议: i.优先使用字典{key: value},其次考虑列表(数组)
i.以输出为主要考虑,设计核心数据结构
i.数据更新问题兼顾考虑,调整核心数据结构
i.对于输入,如有需要,设计辅助数据结构
下面结合题目一一说明。
1396. 设计地铁系统
请你实现一个类 UndergroundSystem ,它支持以下 3 种方法:
1. checkIn(int id, string stationName, int t)
编号为 id 的乘客在 t 时刻进入地铁站 stationName 。
一个乘客在同一时间只能在一个地铁站进入或者离开。
2. checkOut(int id, string stationName, int t)
编号为 id 的乘客在 t 时刻离开地铁站 stationName 。
3. getAverageTime(string startStation, string endStation)
返回从地铁站 startStation 到地铁站 endStation 的平均花费时间。
平均时间计算的行程包括当前为止所有从 startStation 直接到达 endStation 的行程。
调用 getAverageTime 时,询问的路线至少包含一趟行程。
你可以假设所有对 checkIn 和 checkOut 的调用都是符合逻辑的。也就是说,如果一个顾客在 t1 时刻到达某个地铁站,那么他离开的时间 t2 一定满足 t2 > t1 。所有的事件都按时间顺序给出。
输入:
["UndergroundSystem","checkIn","checkIn","checkIn","checkOut","checkOut","checkOut","getAverageTime","getAverageTime","checkIn","getAverageTime","checkOut","getAverageTime"]
[[],[45,"Leyton",3],[32,"Paradise",8],[27,"Leyton",10],[45,"Waterloo",15],[27,"Waterloo",20],[32,"Cambridge",22],["Paradise","Cambridge"],["Leyton","Waterloo"],[10,"Leyton",24],["Leyton","Waterloo"],[10,"Waterloo",38],["Leyton","Waterloo"]]
输出:
[null,null,null,null,null,null,null,14.0,11.0,null,11.0,null,12.0]
解释:
UndergroundSystem undergroundSystem = new UndergroundSystem();
undergroundSystem.checkIn(45, "Leyton", 3);
undergroundSystem.checkIn(32, "Paradise", 8);
undergroundSystem.checkIn(27, "Leyton", 10);
undergroundSystem.checkOut(45, "Waterloo", 15);
undergroundSystem.checkOut(27, "Waterloo", 20);
undergroundSystem.checkOut(32, "Cambridge", 22);
undergroundSystem.getAverageTime("Paradise", "Cambridge"); // 返回 14.0。从 "Paradise"(时刻 8)到 "Cambridge"(时刻 22)的行程只有一趟
undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 11.0。总共有 2 躺从 "Leyton" 到 "Waterloo" 的行程,编号为 id=45 的乘客出发于 time=3 到达于 time=15,编号为 id=27 的乘客于 time=10 出发于 time=20 到达。所以平均时间为 ( (15-3) + (20-10) ) / 2 = 11.0
undergroundSystem.checkIn(10, "Leyton", 24);
undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 11.0
undergroundSystem.checkOut(10, "Waterloo", 38);
undergroundSystem.getAverageTime("Leyton", "Waterloo"); // 返回 12.0
总共最多有 20000 次操作。
1 <= id, t <= 10^6
所有的字符串包含大写字母,小写字母和数字。
1 <= stationName.length <= 10
与标准答案误差在 10^-5 以内的结果都视为正确结果。
# 建议一:优先使用字典{key: value},其次考虑列表(数组)
# ————『根据……返回……』,使用字典{key:value}作为数据结构
# 建议二:以输出为主要考虑,设计核心数据结构
# ————“返回从地铁站 startStation 到地铁站 endStation 的平均花费时间”, 根据输出设计数据结构:dict{(in_station,out_station): aver_time}
# 建议三:数据更新问题兼顾考虑,调整核心数据结构
# ————考虑到新增一名乘客信息后,{(in_station,out_station): aver_time}不方便更新,调整为:{(in_station,out_station): total_time, person_num}
# 此时,只需{key: total_time + cur_time, person_num + 1}即可
# 建议四:对于输入,如有需要,设计辅助数据结构
# ————乘客入站、出站信息分别输入,要想拿到完整的(in_station,out_station)信息,增加辅助数据结构:{id: [in_station, in_time]}
class UndergroundSystem:
def __init__(self):
# 核心数据结构、辅助数据结构
self.station_spend_time = {} # {(in_station,out_station): total_time, person_num}
self.person_in_info = {} #{id: [in_station, in_time]}
def checkIn(self, id: int, stationName: str, t: int) -> None:
self.person_in_info[id] = [stationName, t]
def checkOut(self, id: int, stationName: str, t: int) -> None:
in_station, in_time = self.person_in_info[id]
total_time, person_num = self.station_spend_time.get((in_station,stationName), [0, 0])
self.station_spend_time[(in_station,stationName)] = [total_time+t-in_time, person_num+1]
def getAverageTime(self, startStation: str, endStation: str) -> float:
total_time, person_num = self.station_spend_time.get((startStation, endStation), [0,0])
return total_time / person_num
2.2 例题2
订单预定系统
题目:
网上某个店铺订单管理,有两个对象:顾客(int编号)、货物(int编号)
操作一:顾客预定货物(只有货物编号,没有数量。例如预定一件101和两件102,则输入[102, 101, 102])
操作二:该店铺发货(同样只有货物编号,没有数量,一件一件发送,发送顺序取决于顾客预定顺序。并且,顾客后面追加预定的商品,即使前面预定未发货,两次没有任何联系)
操作三:返回所有顾客中未收货的数量最少的那名顾客,如果都全部收货完毕,返回-1.
# 创建两个数据结构字典,goods{good_id: queue[顾客1, 顾客2, 顾客1, 顾客3,……]}、customer{customer_id: queue[商品1,商品2,商品1,……]}
# 每次预定操作:goods中customer_id入队,customer中good_id入队即可;
# 发货操作:对应出队即可;
# 对customer字典中,根据value的大小排序即可
# 代码已通过全部测试用例
class OrderSystem:
def __init__(self):
self.goods = {}
self.customer = {}
def order(self, customer_id: int, goods: List[int]) -> None:
for good in goods:
order_customer_list = self.goods.get(good, [])
order_customer_list.append(customer_id)
self.goods[good] = order_customer_list
customer_order_num = self.customer.get(customer_id, 0)
customer_order_num += 1
self.customer[customer_id] = customer_order_num
# 这里看来dict.get()操作换成defaultdict(list)更简洁
def deliver(self, goods: List[int]) -> None:
for good in goods:
order_customer_list = self.goods[good]
customer_id = order_customer_list.pop(0)
self.customer[customer_id] -= 1
def query(self) -> int:
min_customer_num = 0
ans_id = []
for customer_id in self.customer:
order_num = self.customer[customer_id]
if order_num > min_customer_num:
ans_id = []
ans_id.append(customer_id)
min_customer_num = order_num
elif order_num == min_customer_num and min_customer_num != 0:
ans_id.append(customer_id)
if min_customer_num == 0:
return -1
else:
return min(ans_id)

- 点赞
- 收藏
- 关注作者
评论(0)