计算机的局部性原理该如何利用

服务端软件开发时,通常会把数据存储在DB。而服务端系统遇到的第一个性能瓶颈,往往发生在访问DB时。
这时大部分开发会拿出“缓存”,通过使用Redis在DB前提供一层缓存数据,缓解DB压力,提升服务端性能。
- 在数据库前添加数据缓存是常见的性能优化方式

这种添加缓存的策略一定有效吗?这种策略在什么情况下是有效的呢?理论分析,添加缓存最佳策略么?
如果我们对访问性能要求高,希望数据在1ms,乃至100微妙内完成处理,我们还能用这个添加缓存的策略么?

理解局部性原理
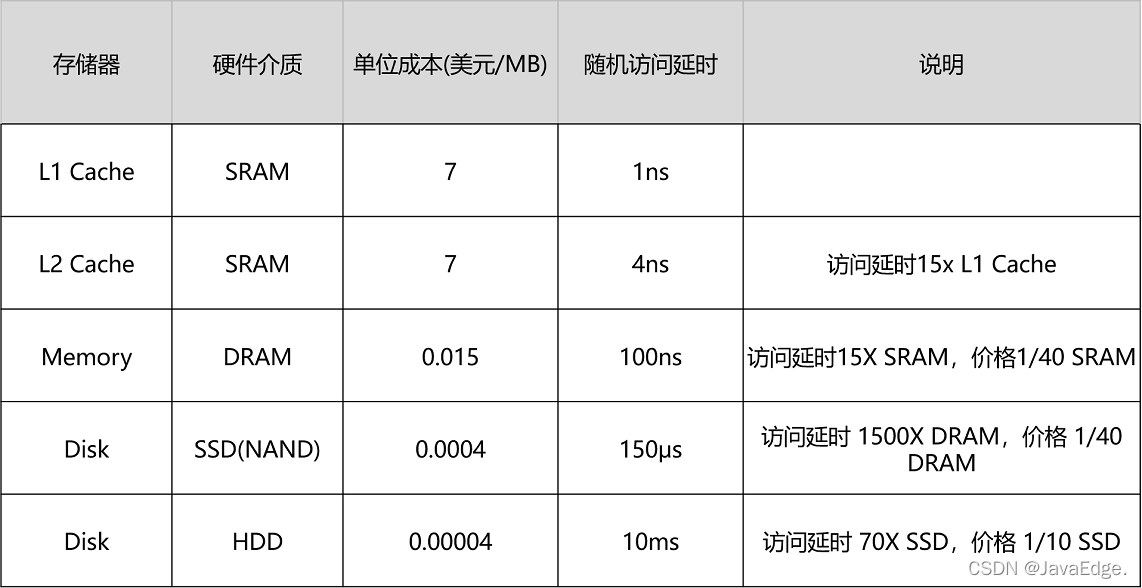
Intel 8265U的CPU L1 Cache只有256K,L2 Cache有个1MB,L3 Cache有12MB。共13MB存储空间,如按7美元/1MB的价格计算,就要91美元。
内存8GB,容量是CPU Cache 600多倍,120美元。如按今天价格,恐怕不到40美元。128G的SSD和1T的HDD,现在的价格加起来也不会超过100美元。虽容量是内存16倍乃至128倍,但访问速度不到内存1/1000。
性能和价格的巨大差异,给我们工程师带来挑战:能不能既享受CPU Cache速度,又享受内存、硬盘巨大的容量和低廉的价格呢?
想要同时享受到这三点,答案就是存储器中数据的局部性原理(Principle of Locality)。可利用这个原理制定管理和访问数据的策略。这个局部性原理包括时间局部性(temporal locality)和空间局部性(spatial locality)这两种策略。
时间局部性
如果一个数据被访问了,那它在短时间内还会被再次访问。
如小说,今天读了一会儿,没读完,明天还会继续读。同理电子商务系统,一个用户打开App,看到首屏。推断他应该很快还会再次访问网站的其他内容或页面,就将这个用户的个人信息,从存储在硬盘的数据库读取到内存的缓存中来。这利用的就是时间局部性。
- 同一份数据在短时间内会反复多次被访问

空间局部性
如果一个数据被访问了,那么和它相邻的数据也很快会被访问。
读完了这本书之后,感觉这书不错,所以就会借阅整套。程序访问了数组首项后,多半会循环访问下一项。因为,在存储数据的时候,数组内的多项数据会存储在相邻的位置。这就好比图书馆会把“哈利波特”系列放在一个书架上,摆放在一起,加载时,也会一并加载。我们去图书馆借书,往往会一次性把7本都借回来。
相邻的数据会被连续访问
有了时间局部性和空间局部性,不用再把所有数据都放在内存,也不用都放在HDD,而是把访问次数多的数据,放在贵但快的存储器,把访问次数少的数据,放在慢但大点的存储器。
这样组合使用内存、SSD硬盘以及HDD硬盘,最低成本提供实际所需的数据存储、管理和访问需求。
花最少的钱,装下亚马逊的所有商品?
通过局部性原理,利用不同层次存储器的组合,究竟会有什么样的好处。
提供一个亚马逊电商网站。假设里面有6亿件商品,如果每件商品需要4MB的存储空间,需2400TB( = 6亿 × 4MB)数据存储。
如把数据都放在内存,就需3600万美元( = 2400TB/1MB × 0.015美元 = 3600万美元)。但这6亿件商品,不是每件商品都会被经常访问。如有Kindle,也一定有无人问津商品,如缅甸语词典。
如只在内存里放前1%热门商品,即600万件热门商品,而把剩下商品,放在机械式HDD硬盘,则需存储成本下降到45.6万美元( = 3600 万美元 × 1% + 2400TB / 1MB × 0.00004 美元),是原来成本的1.3%左右。
这就是时间局部性。把有用户访问过数据,加载到内存,一旦内存放不下,就把最长时间没在内存被访问过的数据,从内存移走,这就是LRU(Least Recently Used)。
热门商品被访问得多,就会始终被保留在内存,冷门商品被访问得少,就只存放在HDD,数据读取也都是直接访问硬盘。即使加载到内存中,也会很快被移除。越热门,越容易在内存中找到,也就更好地利用了内存的随机访问性能。
只放600万件商品真的可以满足我们实际的线上服务请求吗?
要看LRU缓存命中率(Hit Rate/Hit Ratio),即访问的数据中,可在我们设置的内存缓存中找到的占比。
内存随机访问请求需要100ns。极限情况下,内存可以支持1000万次随机访问。我们用了24TB内存,如果8G一条的话,意味着有3000条内存,可以支持每秒300亿次( = 24TB/8GB × 1s/100ns)访问。以亚马逊2017年3亿的用户数来看,我们估算每天的活跃用户为1亿,这1亿用户每人平均会访问100个商品,那么平均每秒访问的商品数量,就是12万次。
但如数据没有命中内存,那么对应的数据请求就要访问到HDD磁盘了。一块HDD硬盘只能支撑每秒100次的随机访问,2400TB的数据,以4TB一块磁盘来计算,有600块磁盘,也就是能支撑每秒 6万次( = 2400TB/4TB × 1s/10ms )的随机访问。
这意味所有商品访问请求,都直接到了HDD磁盘,HDD磁盘支撑不了这样的压力。我们至少要50%的缓存命中率,HDD磁盘才能支撑对应的访问次数。不然的话,我们要么选择添加更多数量的HDD硬盘,做到每秒12万次的随机访问,或者将HDD替换成SSD硬盘,让单个硬盘可以支持更多的随机访问请求。
这只是一个简单估算。实际应用程序中,查看一个商品数据意味着不止一次随机内存或随机磁盘访问。对应数据存储空间也不止要考虑数据,还需要考虑维护数据结构的空间,而缓存的命中率和访问请求也要考虑均值和峰值的问题。
估算过程要理解如何进行存储器的硬件规划。要考虑硬件的成本、访问的数据量以及访问的数据分布,然后根据这些数据的估算,来组合不同的存储器,能用尽可能低的成本支撑所需要的服务器压力。而当你用上了数据访问的局部性原理,组合起了多种存储器,你也就理解了怎么基于存储器层次结构,来进行硬件规划了。
总结
实际的计算机日常的开发和应用中,对于数据的访问总是会存在一定的局部性。有时候,这个局部性是时间局部性,就是我们最近访问过的数据还会被反复访问。有时候,这个局部性是空间局部性,就是我们最近访问过数据附近的数据很快会被访问到。
而局部性的存在,使得我们可以在应用开发中使用缓存这个有利的武器。比如,通过将热点数据加载并保留在速度更快的存储设备里面,我们可以用更低的成本来支撑服务器。
通过亚马逊这个例子,我们可以看到,我们可以通过快速估算的方式,来判断这个添加缓存的策略是否能够满足我们的需求,以及在估算的服务器负载的情况下,需要规划多少硬件设备。这个“估算+规划”的能力,是每一个期望成长为架构师的工程师,必须掌握的能力。
遇到性能问题,特别是访问存储器的性能问题的时候,是否可以简单地添加一层数据缓存就能让问题迎刃而解呢?
亚马逊网站商品数据的例子,似乎给了我们一个“Yes”。那这个答案是否放之四海皆准呢?下回分解
参考
- 《计算机组成与设计:硬件/软件接口》的5.1~5.2小节

- 点赞
- 收藏
- 关注作者
评论(0)