用正则表达式爬取古诗文网站,边玩边学【python爬虫入门进阶】(09)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
本文重点:这篇文章主要学习正则表达式以及re模块的使用。
为啥写这篇文章?
前面两篇文章我们介绍了正则表达式的基本语法以及一些简单的使用场景。还没有看的小伙伴赶紧看过来吧,
学好正则表达式,啥难匹配的内容都给我匹配上【python爬虫入门进阶】(07)
用正则表达式校验手机号,邮箱就是流弊【python爬虫入门进阶】(08)
花个几分钟就能学会的知识点为啥不学呢?
本文将正则表达式的应用进一步放大,用它来爬取古诗文网站的数据。在本文的学习中,请你暂时将xpath隐藏掉。
分析古诗文网站
下图1展示了古诗文网站—》诗文 栏目的首页数据。该栏目的地址是:https://so.gushiwen.cn/shiwens/

第二页的地址是:https://so.gushiwen.cn/shiwens/default.aspx?page=2&tstr=&astr=&cstr=&xstr= 。依次类推第n页的地址就是page=n。其他不变。
1. 用正则表达式获取总页数

匹配的正则表达式是r'<div class="pagesright">.*?<span .*?>(.*?)</span>'
- 首先,r修饰的字符串是原生字符串,首先匹配到
<div class="pagesright">标签,然后再通过.*?匹配到里面的里面的<a>标签<span>标签等。这里. 可以匹配到任意的一个字符(换行符除外),* 号可以匹配0或者任意多个字符。?号表示只能匹配到1个或者0个。这里加上?号是为了使用非贪婪模式。 <span .*?>通过匹配到存放总页数的<span>标签。在标签里指定.*?(.*?)加上()可以指定不同的分组,这里我们只需要获取页数所以就单独添加一个分组。
所以,最终的代码是:
def get_total_pages():
resp = requests.get(first_url)
# 获取总页数
ret = re.findall(r'<div class="pagesright">.*?<span .*?>(.*?)</span>', resp.text, re.DOTALL)
result = re.search('\d+', ret[0])
for page_num in range(int(result.group())):
url = 'https://so.gushiwen.cn/shiwens/default.aspx?page=' + str(page_num)
parse_page(url)
在findall方法中传入re.DOTALL参数是为了是. 号可以匹配到换行符\n。
前面ret的结果是/ 5页。再获取5这个数字的话,还需要做一次匹配查找,这就是通过re.search('\d+', ret[0]) 来进行查找。
2. 提取诗的标题
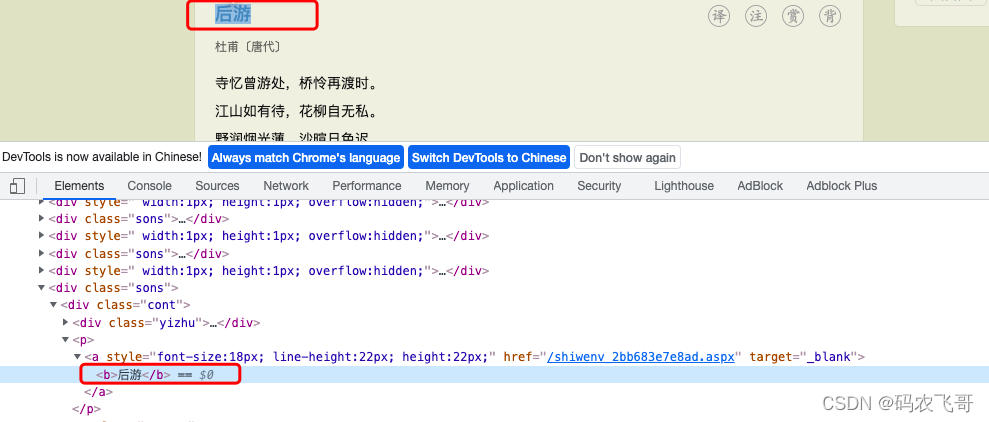
如上图2展示了诗的标题的HTML源码,从中可以看出诗的标题被存在<b>标签 匹配诗的标题的正则表达式是<div class="cont">.*?<b>(.*?)</b>
首先还是匹配到<div class="cont"> 标签,接着就是匹配<b>(.*?)</b> 这里还是采用非贪婪模式来进行匹配。
3. 提取作者和朝代
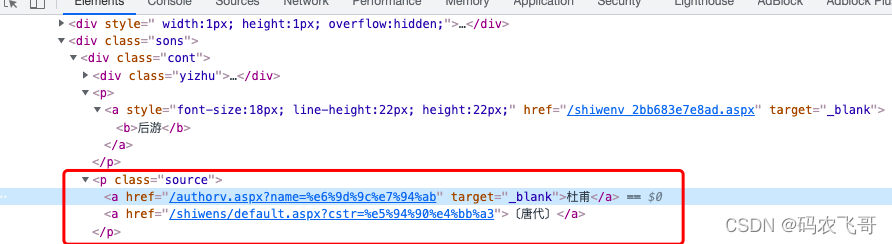
如上图3展示了诗的作者和朝代的HTML源码,从中可以看出作者和朝代都是在<p class="source"></p> 标签下的两个a标签中。
3.1 提取作者
提取作者的正则表达式是<p class="source">.*?<a .*?>(.*?)</a> 首先还是匹配到<p class="source"> 标签。接着就是匹配第一个<a> 标签中的内容。
3.2 提取朝代
提取朝代的正则表达式是<p class="source">.*?<a .*?><a .*?>(.*?)</a> 与提取作者不同的是多了一个<a .*?> ,这是因为朝代在第二个<a>标签中。
5. 提取诗的内容
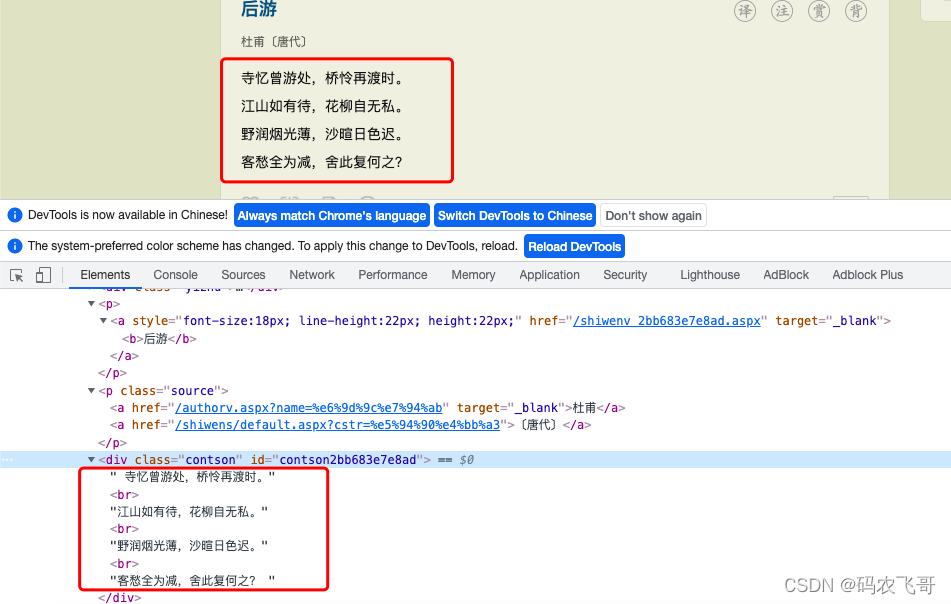
如上图4展示了诗的内容的HTML源码,从中可以看出诗句都在<div class="contson">标签中,所以只需要匹配到这个标签里的内容即可。其正则表达式是<div class="contson" .*?>(.*?)</div>。
但是这样匹配出来的数据是包含<br> 标签的。所以,我们需要通过sub 方法将这个标签替换掉。re.sub(r'<.*?>+', "", content)。
整理代码
至此,我们就将所有想要的数据都提取到了。接下来,我们还需要对数据进行处理。我们期望的最终数据格式是:
poems=[
{
"title": '渔家傲·花底忽闻敲两桨',
"author":'张三',
'dynasty':'唐朝',
'content':'xxxxxx'
}
{
"title": '鹅鹅鹅',
"author":'李四',
'dynasty':'唐朝',
'content':'xxxxxx'
}
]
前面,我们分别得到了所有标题的列表titles;所有作者的列表authors;所有朝代的列表dynastys;所有诗句的列表contents。
那么,我们如何将这些列表组合成上面的那种形式呢?
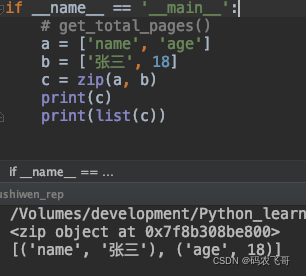
这里,就需要用到 zip 函数了。该函数可以将多个列表组合成一个新的列表,其中列表的元素是元组。比如:
a=['name','age']
b=['张三',18]
c=zip(a,b)
调用zip 方法之后得到一个zip对象,该对象可以转换成list 对象。最终得到的结果如下图5
完整源代码
# -*- utf-8 -*-
"""
@url: https://blog.csdn.net/u014534808
@Author: 码农飞哥
@File: gushiwen_rep.py
@Time: 2021/12/7 07:40
@Desc: 用正则表达式爬取古诗文网站
古诗文网站的地址:
https://www.gushiwen.cn/
"""
import re
import requests
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
first_url = 'https://so.gushiwen.cn/shiwens/default.aspx'
def get_total_pages():
resp = requests.get(first_url)
# 获取总页数
ret = re.findall(r'<div class="pagesright">.*?<span .*?>(.*?)</span>', resp.text, re.DOTALL)
result = re.search('\d+', ret[0])
for page_num in range(int(result.group())):
url = 'https://so.gushiwen.cn/shiwens/default.aspx?page=' + str(page_num)
parse_page(url)
# 解析页面
def parse_page(url):
resp = requests.get(url)
text = resp.text
# 提取标题 (.*) 进行分组,只提取<b>标签中的内容,默认情况下 .不能匹配\n。加上re.DOTALL 表示.号可以匹配所有,贪婪模式
# titles = re.findall(r'<div class="cont">.*<b>(.*)</b>', text,re.DOTALL)
# 非贪婪模式
titles = re.findall(r'<div class="cont">.*?<b>(.*?)</b>', text, re.DOTALL)
# 提取作者
authors = re.findall(r'<p class="source">.*?<a .*?>(.*?)</a>', text, re.DOTALL)
# 提取朝代
dynastys = re.findall(r'<p class="source">.*?<a .*?><a .*?>(.*?)</a>', text, re.DOTALL)
# 提取诗句
content_tags = re.findall(r'<div class="contson" .*?>(.*?)</div>', text, re.DOTALL)
contents = []
for content in content_tags:
content = re.sub(r'<.*?>+', "", content)
contents.append(content)
poems = []
for value in zip(titles, authors, dynastys, contents):
# 解包
title, author, dynasty, content = value
poems.append(
{
"title": title,
"author": author,
'dynasty': dynasty,
'content': content
}
)
print(poems)
"""
poems=[
{
"title": '渔家傲·花底忽闻敲两桨',
"author":'张三',
'dynasty':'唐朝',
'content':'xxxxxx'
}
{
"title": '渔家傲·花底忽闻敲两桨',
"author":'张三',
'dynasty':'唐朝',
'content':'xxxxxx'
}
]
"""
"""
zip 函数
a=['name','age']
b=['张三',18]
c=zip(a,b)
c=[
('name','张三'),
('age',18)
]
"""
if __name__ == '__main__':
get_total_pages()
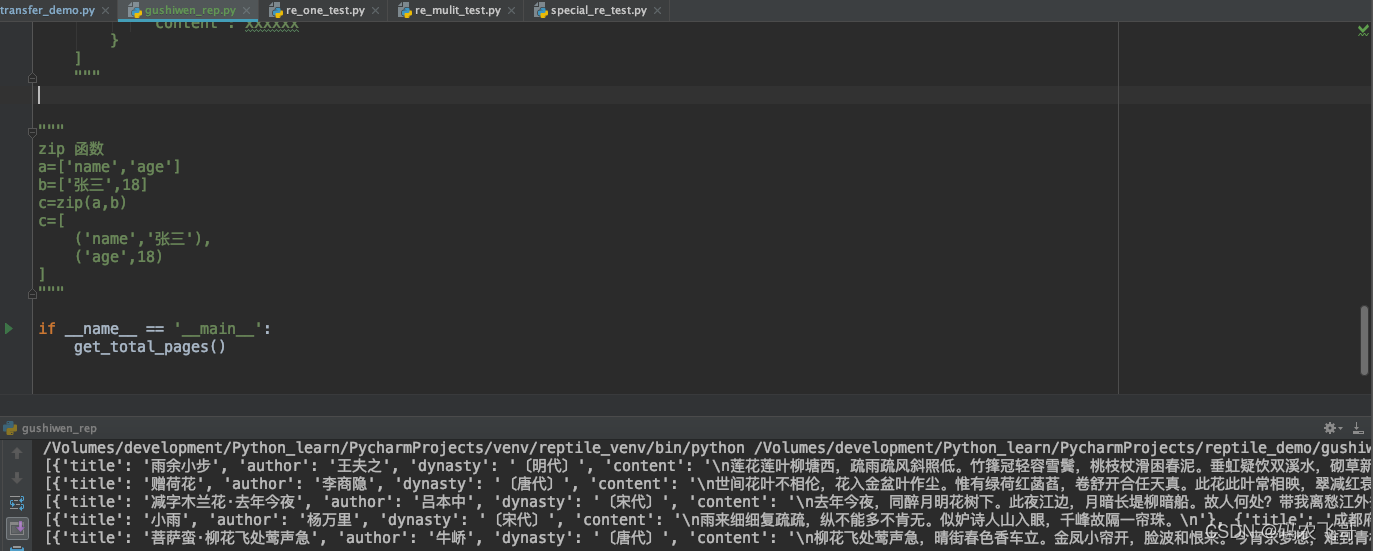
最终的运行结果是:
总结
本文以古诗文网为例演示了如何通过正则表达式来爬取网站数据。

- 点赞
- 收藏
- 关注作者
评论(0)