用正则表达式校验手机号,邮箱就是流弊【python爬虫入门进阶】(08)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
本文重点:这篇文章主要学习正则表达式以及re模块的使用。
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

说在前面
上一篇文章我们主要介绍了正则表达式的各种语法。学好正则表达式,啥难匹配的内容都给我匹配上【python爬虫入门进阶】(07) 还没看的小伙伴赶紧去看看哦!!!这篇文章主要将介绍正则表达式的一些实战小案例。比如:用正则表达式校验邮箱,手机号等等。
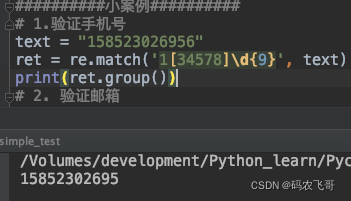
验证手机号
手机号的格式一般是首位是1,第二位是34578中间的任意一个数,最后9位是随机数字。所以,他的正则表达式是:1[34578]\d{9}
text = "158523026956"
ret = re.match('1[34578]\d{9}', text)
print(ret.group())
验证邮箱
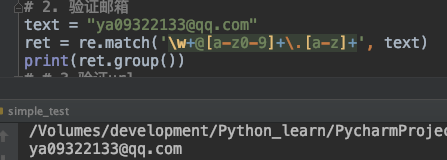
邮箱的格式比较多,但是基本的格式可以分为三块: ya09322133@qq.com
第一部分是 @符号前面是字母或者数字,所以这部分就是\w+,
第二部分是@符号之后. 号之前这部分一般是a-z之间的字母或者数字,所以这部分的表达式是:[a-z0-9]+。
最后一部分就是**.**符号之后的部分,这部分就是a-z之间的字母,所以这部分的表达式是[a-z]+。
所以,最终的表达式是:\w+@[a-z0-9]+\.[a-z]+
text = "ya09322133@qq.com"
ret = re.match('\w+@[a-z0-9]+\.[a-z]+', text)
print(ret.group())
验证url
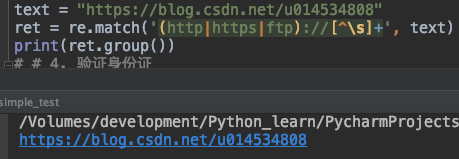
url的格式分为两个部分: https://blog.csdn.net/u014534808
第一部分是::// 之前的部分,这部分一般是以http,https或者ftp。所以,这部分的表达式是:http|https|ftp
第二部分是::// 之后的部分,这部分的要求就是不能以空白字符开头或者以\n,\t 等开头。所以,这部分的表达式是:[^\s]+
text = "https://blog.csdn.net/u014534808"
ret = re.match('(http|https|ftp)://[^\s]+', text)
print(ret.group())
验证身份证号
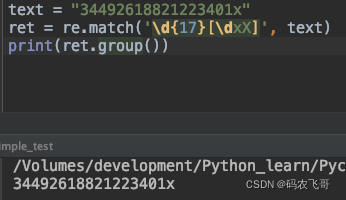
身份证号有一个标准的格式,如:34492618821223401x 。 它的位数一共是18位,前面17位都是数字。最后一位的话可能是数字也可能是x。所以,验证身份证的表达式可以写为:\d{17}[\dxX]。
text = "34492618821223401x"
ret = re.match('\d{17}[\dxX]', text)
print(ret.group())
转义字符和原生字符
在正则表达式中,有些字符是有特殊意义的字符,因此如果要匹配这些字符,那么久必须要使用反斜杠进行转义。比如:
,那么就必须使用\$ ,示例代码如下:
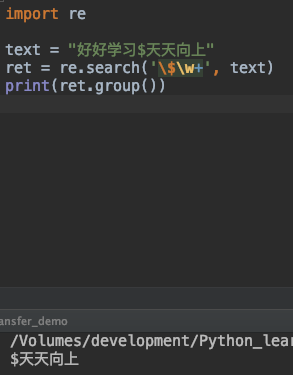
import re
text = "好好学习$天天向上"
ret = re.search('\$\w+', text)
print(ret.group())
对\n 进行转移
- 用python的方式可以写成
r'\n' - 用正则表达式的方式可以写成
\\n。
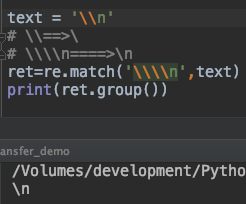
text = '\\n'
# \\==>\
# \\\\n====>\n
ret=re.match('\\\\n',text)
print(ret.group())
或者
text = '\\n'
# r修饰的就是原生字符串
ret=re.match(r'\\n',text)
print(ret.group())
group分组
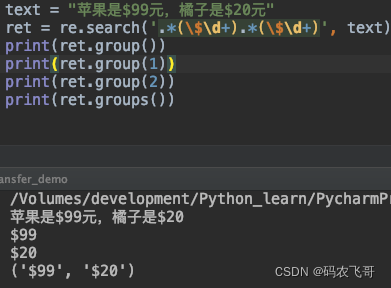
在正则表达式中,可以对过滤到的字符串进行分组,分组使用圆括号()的方式。
- group: 和group(0) 是等价的,返回的是整个满足条件的字符串
- groups : 返回的是里面的子组,索引从1开始。
- group(1) :返回的是第一个子组,可以传入多个。
text = "苹果是$99元,橘子是$20元"
ret = re.search('.*(\$\d+).*(\$\d+)', text)
print(ret.group())
print(ret.group(1))
print(ret.group(2))
print(ret.groups())
find_all 函数
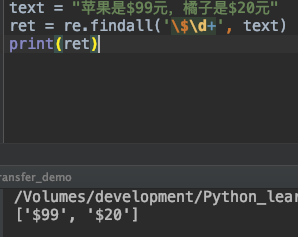
find_all函数用于找出所有满足条件的,返回的是一个列表。
text = "苹果是$99元,橘子是$20元"
ret = re.findall('\$\d+', text)
print(ret)
sub 用来替换字符串
sub 用来替换字符串,将匹配的字符串替换成其他字符串。
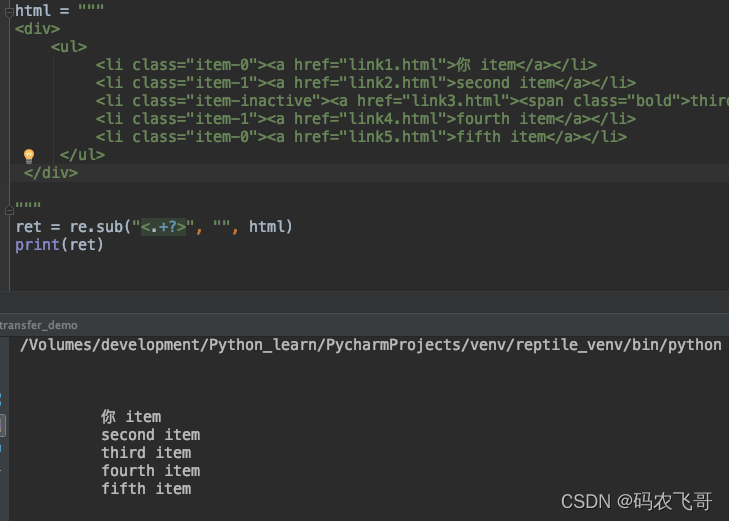
html = """
<div>
<ul>
<li class="item-0"><a href="link1.html">你 item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
"""
ret = re.sub("<.+?>", "", html)
print(ret)
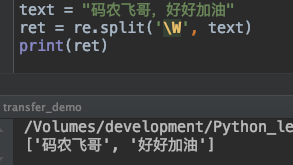
split函数
split函数是用于分割匹配的字符串
text = "码农飞哥,好好加油"
ret = re.split('\W', text)
print(ret)
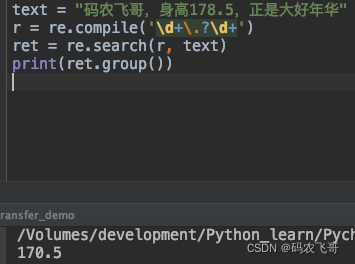
compile
对于一些经常要用到的正则表达式,可以使用compile进行编译,后期再使用的时候可以直接拿来使用,执行效率要更快,而且compile还可以指定 flag=re.VERBOSE,在写正则表达式的时候可以做注释,示例代码如下:
text = "码农飞哥,身高178.5,正是大好年华"
r = re.compile('\d+\.?\d+')
ret = re.search(r, text)
print(ret.group())
添加注释
text = "码农飞哥,身高178.5,正是大好年华"
r = re.compile(r"""
\d+ # 小数点前面的数字
\.? #小数点本身
\d* #小数点后面的数字
""",re.VERBOSE)
ret = re.search(r, text)
print(ret.group())
总结
本文详细介绍了正则表达式的使用,希望对读者朋友们有所帮助。

- 点赞
- 收藏
- 关注作者
评论(0)