学好正则表达式,啥难匹配的内容都给我匹配上【python爬虫入门进阶】(07)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
本文重点:这篇文章主要学习正则表达式以及re模块的使用。
关注下方公众号,众多福利免费嫖;加我VX进群学习,学习的路上不孤单

正则表达式是什么?
按照一定的规则,从某个字符串中匹配出想要的数据,这个规则就是正则表达式。
正则表达式的使用
正则表达式的使用也很简单,标准的使用方式是:
- 使用match方法进行匹配,match方法只能从字符串开始的地方匹配。
语法结构:match(pattern, string, flags=0)其中参数pattern传入的是正则表达式,string传入的是待匹配的字符串,表示从字符串的开始位置查找满足正则表达式pattern的字符。如果能匹配到则返回一个Match对象,匹配不到的话则返回None对象。
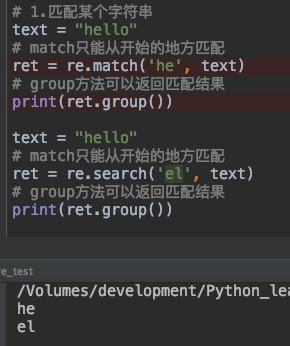
比如下面代码ret = re.match('he', text)表示匹配出以he开头的字符。
import re
text = "hello"
# match只能从开始的地方匹配
ret = re.match('he', text)
# group方法可以返回匹配结果
print(ret.group())
group方法可以返回到的字符结果。
2. 使用search 方法进行查找,search方法表示找出整个字符串中
语法结构:search(pattern, string, flags=0) 其中参数pattern传入的是正则表达式,string传入的是待匹配的字符串,表示从整个字符串中查找满足正则表达式pattern的字符。如果能匹配到则返回一个Match对象,匹配不到的话则返回None对象。
text = "hello"
# match只能从开始的地方匹配
ret = re.search('el', text)
# group方法可以返回匹配结果
print(ret.group())
1. 点 . 符号可以匹配任意的字符,只能匹配一个字符,不能匹配换行符
text = "1hello"
# match只能从开始的地方匹配
ret = re.match('.', text)
# group方法可以返回匹配结果
print(ret.group())
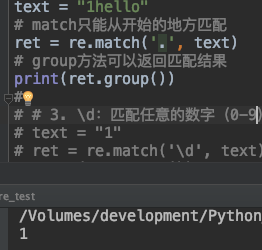
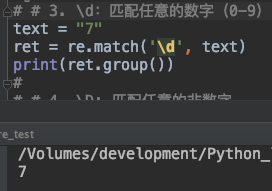
2. \d:匹配任意的数字(0-9 范围内)
\d:用于匹配任意的数字(0-9 范围内)
text = "712"
ret = re.match('\d', text)
print(ret.group())
4. \D: 匹配任意的非数字
\D 与**\d** 恰恰相反,\D 表示匹配任意的非数字
text = "dbc"
ret = re.match('\D', text)
print(ret.group())
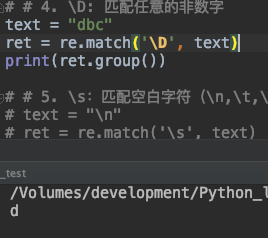
5. \s : 匹配空白字符(\n,\t,\r以及空格)
\s 用于匹配空白字符,包括:\n,\t,\r以及空格 等。
text = "\n"
ret = re.match('\s', text)
print(ret.group())
运行结果虽然打印的结果虽然看不到字符,但是确实是匹配到了,因为\n是一个换行符。

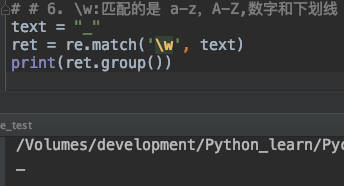
6. \w:匹配的是 a-z,A-Z,数字和下划线
\w 匹配的是a到z之间的所有字符,A到Z之间的所有字符,数字以及下划线
text = "_"
ret = re.match('\w', text)
print(ret.group())
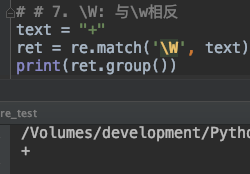
7. \W: 与\w 刚好相反
\W: 匹配的数据与**\w**匹配的刚刚相反,\W 匹配的就是非字符,非数字以及非下划线
text = "+"
ret = re.match('\W', text)
print(ret.group())
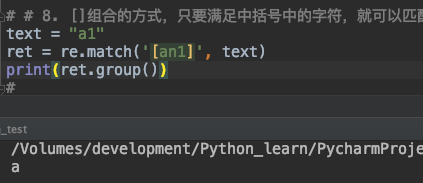
8. []组合的方式,只要满足中括号中的字符,就可以被匹配
[] 中括号组合的方式,只要满足中括号中的字符,就可以被匹配到。
text = "a1"
ret = re.match('[an1]', text)
print(ret.group())
9. ^(脱字号): 表示以非xxx开始
^(脱字号): 表示以非xxx开始
text = "非数字"
ret = re.match('[^0-9]', text)
print(ret.group())
10. + 匹配多个字符
前面介绍的都是单个字符的匹配,如果有多个字符满足匹配要求也是不能匹配输出的。+ 就是将满足条件的字符串都匹配输出。
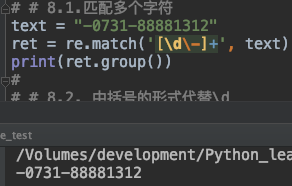
text = "-0731-88881312"
ret = re.match('[\d\-]+', text)
print(ret.group())
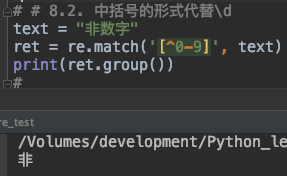
11. 中括号的形式代替\d
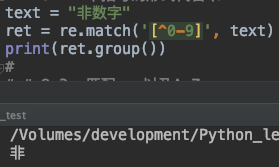
text = "非数字"
ret = re.match('[^0-9]', text)
print(ret.group())
其中表达式 [^0-9] 等价于[^\d] 表示匹配出非数字
12. 中括号匹配a-z,A-Z以及0-9
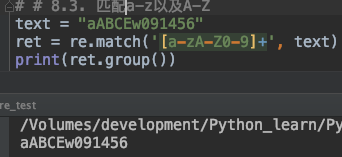
表达式[a-zA-Z0-9]+ 表示匹配所有a-z,A-Z以及0-9的字符。
text = "aABCEw091456"
ret = re.match('[a-zA-Z0-9]+', text)
print(ret.group())
13. * 匹配0或者任意多个字符
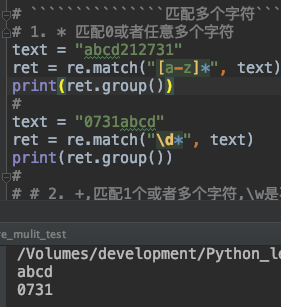
** * ** 用于匹配0个或者任意多个字符。下面代码中[a-z]*表示匹配出所有以a-z开头的字符串中的字符。\d* 表示匹配出所有以数字开头的字符串中的字符。
text = "abcd212731"
ret = re.match("[a-z]*", text)
print(ret.group())
text = "0731abcd"
ret = re.match("\d*", text)
print(ret.group())
14. +,匹配1个或者多个字符
+ 号用于匹配1个或这个多个字符。\w 表示匹配所有 a-z,A-Z,数字和下划线的字符,但是不包括+。所以 ,\w+ 表达式在字符串ab+cd中匹配出的结果是ab。
text = "ab+cd"
ret = re.match('\w+', text)
print(ret.group())

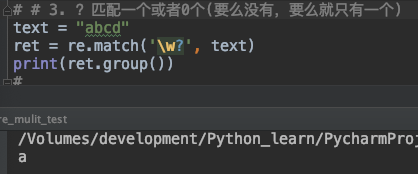
14. ?匹配一个或者0个(要么没有,要么就只有一个)
? 用于匹配一个或者0个 (要么没有,要么就只有一个)字符
text = "abcd"
ret = re.match('\w?', text)
print(ret.group())
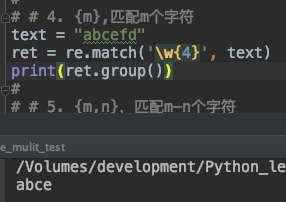
15. {m} 表示匹配m个字符
{m} 表示匹配m个字符。
text = "abcefd"
ret = re.match('\w{4}', text)
print(ret.group())
16. {m,n},匹配m-n个字符
**{m,n}**用于匹配第m到第n之间的字符
text = "hbcefd"
ret = re.match('\w{1,5}', text)
print(ret.group())

总结
本文详细罗列了正则表达式的各种语法,简单移动,读者朋友们如有问题欢迎扫描下方二维码联系我。

- 点赞
- 收藏
- 关注作者
评论(0)