利用多线程到电影天堂爬点电影回家慢慢看【python爬虫入门进阶】(05)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
为什么写这篇文章?
已经好久没有更新爬虫类的文章了,从入门到入狱的好技术怎能不好好学习呢。所以,今天我继续来卷了。本文将从实战的角度介绍一个完整的爬虫。这里以妇孺皆知的电影天堂网站为例进行说明。希望读者朋友们能有所启发,有所收获。
@[TOC]
0. 首先分析下
我总觉得在进行爬虫之前我们首先需要明确要爬取的内容,接着就是分析爬取的步骤,先爬取啥,后爬取啥;然后通过Xpath匹配待提取的内容;最后就是编写爬虫代码。
1.明确待爬取的内容
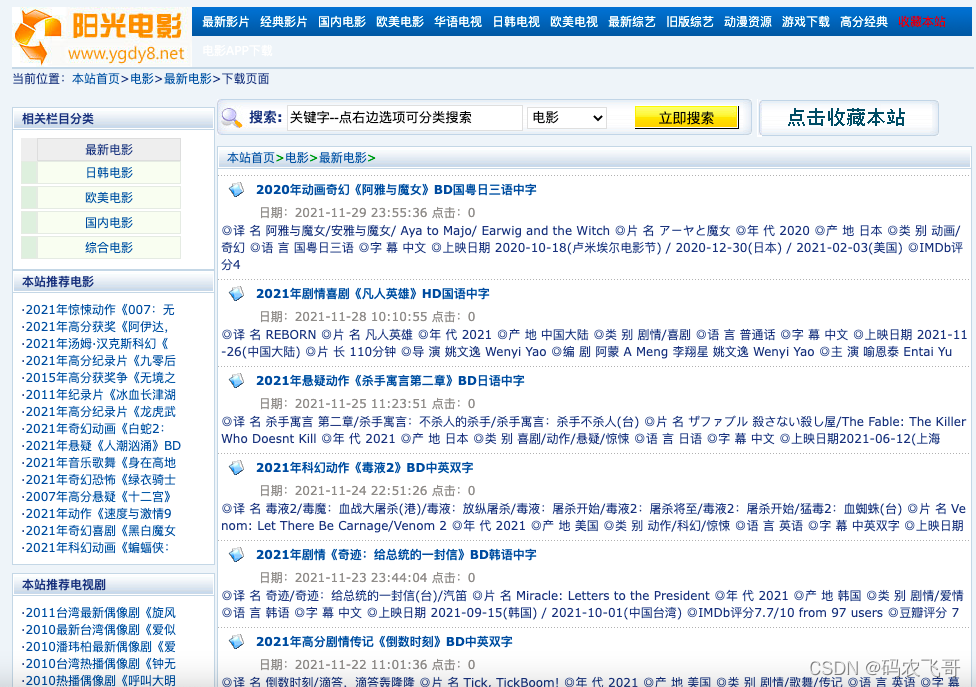
- 这里我们爬取的内容就是最新电影栏目下每个电影的详细信息以及下载链接。最新电影的页面如图1所示:

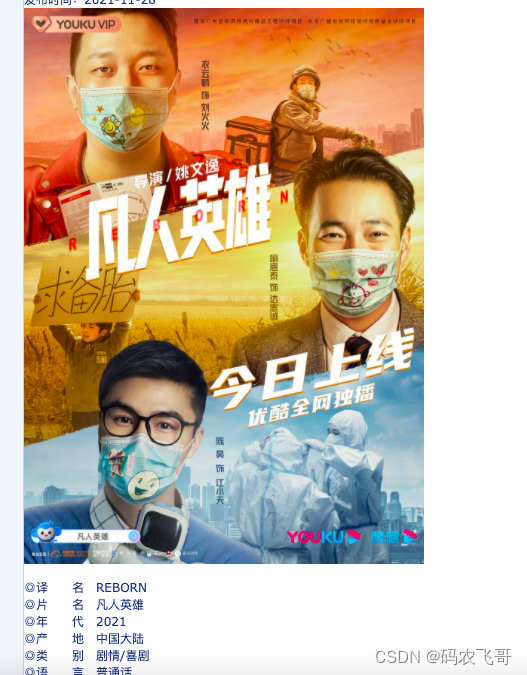
这里以凡人英雄这个电影为例,该电影的详细详细信息,包括片名,导演,演员等信息都是我们需要爬取的内容。
2. 分析爬取步骤
毫无疑问在这个场景下我们首先需要爬取最新电影栏目下列表页的数据,在该页面主要爬取的是每部电影详情页的链接。
然后就是根据详情页的链接爬取详情页的详细数据。
2. 爬取列表页
首先就是爬取列表页获取详情的地址。在Chrome浏览器上通过按下F12按钮打开调试窗口简单的分析下。
2.1. 找出列表页的url的特点
首页的地址是:https://www.ygdy8.net/html/gndy/dyzz/index.html 我们找不出任何特点。
接着我们点击第二页可以看到第二页url变成了https://www.ygdy8.net/html/gndy/dyzz/list_23_2.html
在点击第三页发现第三页的url变成了https://www.ygdy8.net/html/gndy/dyzz/list_23_3.html
依次类推我们可以得出第n页的页面地址是:https://www.ygdy8.net/html/gndy/dyzz/list_23_n.html。
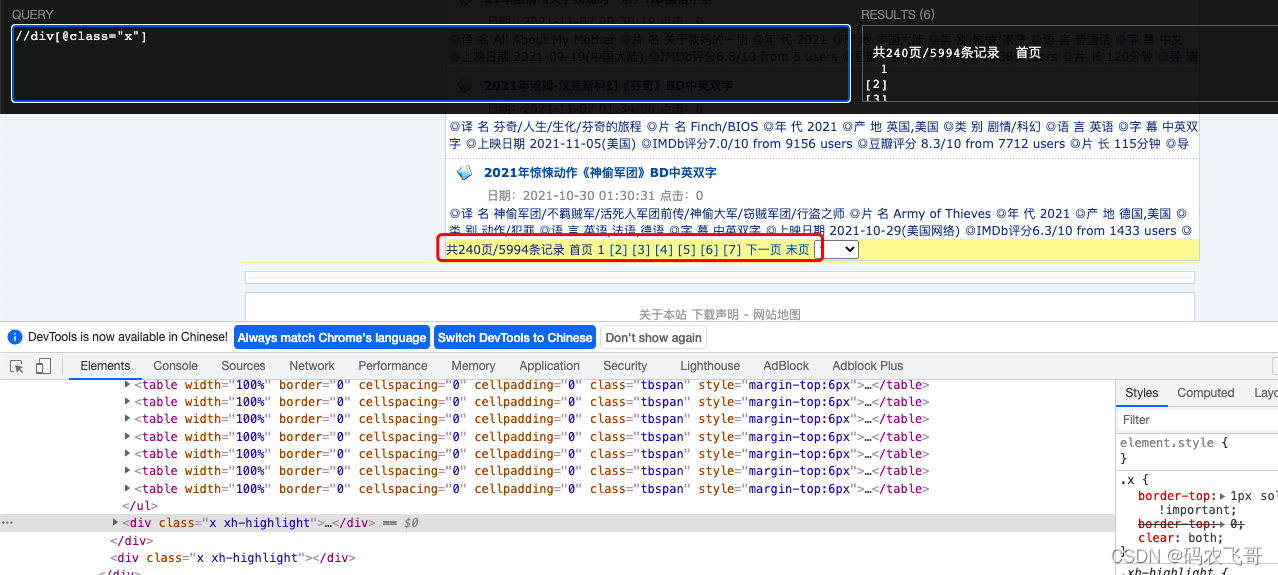
2.2. 找出总页数
打开xpathhelper插件,然后通过分析可以得到//div[@class="x"] 可以获取到包含总页数的div标签,然后通过
//div[@class="x"]//text() 可以获取到我们想要的内容。表达式解释://div[@class="x"]表示从整个页面中匹配class属性是x的div标签。
//text() 表示获取该标签下的所有文本。
# 找到分页插件的内容,strip方法是用于去除空格
total_pages_element = html.xpath('//div[@class="x"]//text()')[1].strip()
#提取 共 字的索引位置
start_index = total_pages_element.find('共')
#提取 页 字的索引位置
end_index = total_pages_element.find('页')
# 共 字和 页 字之间就是我们想要的总页数了
total_pages = total_pages_element[start_index + 1:end_index]
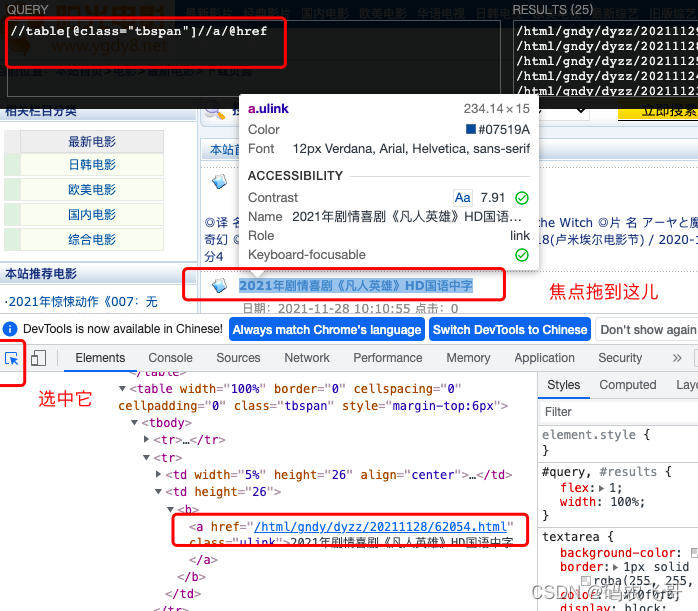
2.3. 找出详情页的url
同样的我们在列表页面选中某个电影标题,通过调试可以知道每个电影详情页面的链接在<table class="tbspan">标签下的<tr>标签下的<td>标签下的<a class="ulink"> 标签中。这样说起来是不是有点绕。没关系的,通过xpath表达式只需要这样就可以了//a[@class="ulink"]/@href 表达式。表达式解释://a[@class="ulink"]表示从整个页面中匹配class属性是ulink的a标签。/@href 表示获取该标签下href的属性值。
当然也通过//table[@class="tbspan"]//a/@href 表达式,这两个表达式都可以提取到我们想要的数据。对xpath表达式还不熟悉的小伙伴可以看下这篇文章 浅识XPath(熟练掌握XPath的语法)【python爬虫入门进阶】(03)。
这里需要注意的是href标签中的链接不是一个完整的链接,完整的链接需要加上域名 https://www.ygdy8.net。所以,链接的代码是:
BASE_DOMAIN = 'https://www.ygdy8.net'
resp = requests.get(page_url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
# 获取电影详情页的地址
detail_url_list = html.xpath('//table[@class="tbspan"]//a/@href')
#将详情页地址拼接成一个完整地址
new_detail_url_list = [BASE_DOMAIN + detail_url for detail_url in detail_url_list]
3.爬取详情页数据
拿到详情页地址之后就是获取详情页的详细数据了。这同样比较简单。首先,还是打开详情页面进行分析。
这里还是以「凡人英雄」为例,还是跟列表页类似的分析步骤。
3.1获取电影标题
通过//div[@class="title_all"]//font/text() ,表达式解释://div[@class="title_all"]表示从整个页面中匹配class属性是title_all的div标签。 //div[@class="title_all"]//font 从标签第一步获取的div标签中获取font标签。text()方法依然是获取标签内容。
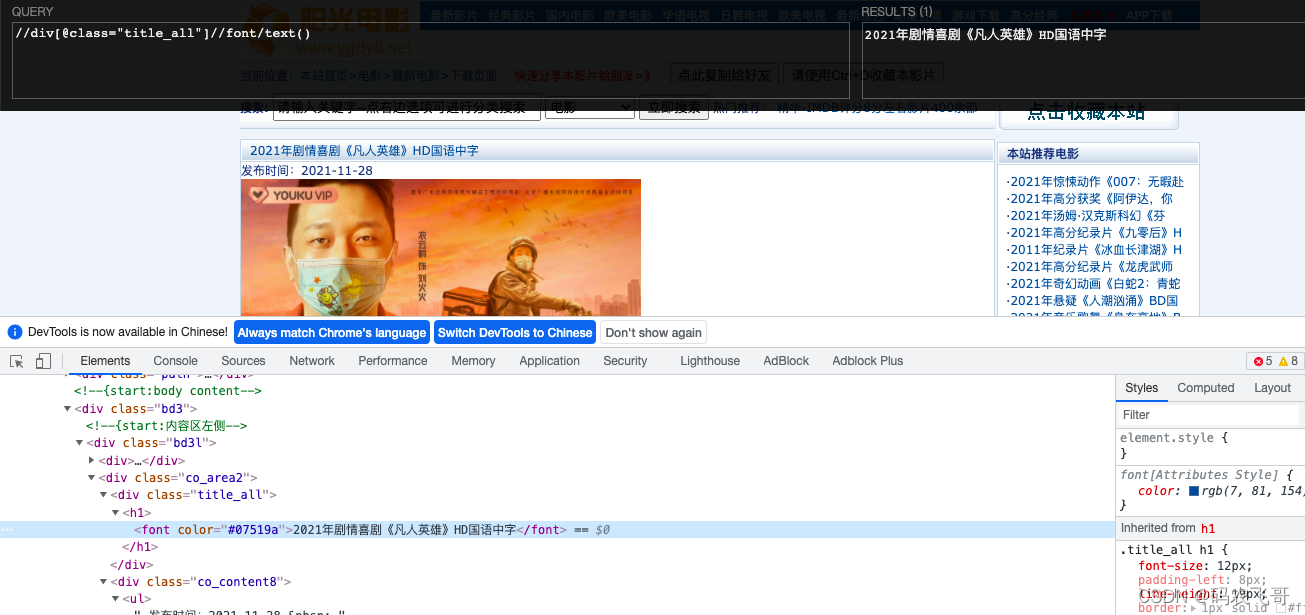
电影的发布时间以及获取电影海报的获取跟电影标题类似,在此就不在赘述了。
获取电影片名&导演&主演等信息
通过调试可以得知电影片名&导演&主演等信息均是在<div id="Zoom">标签下。
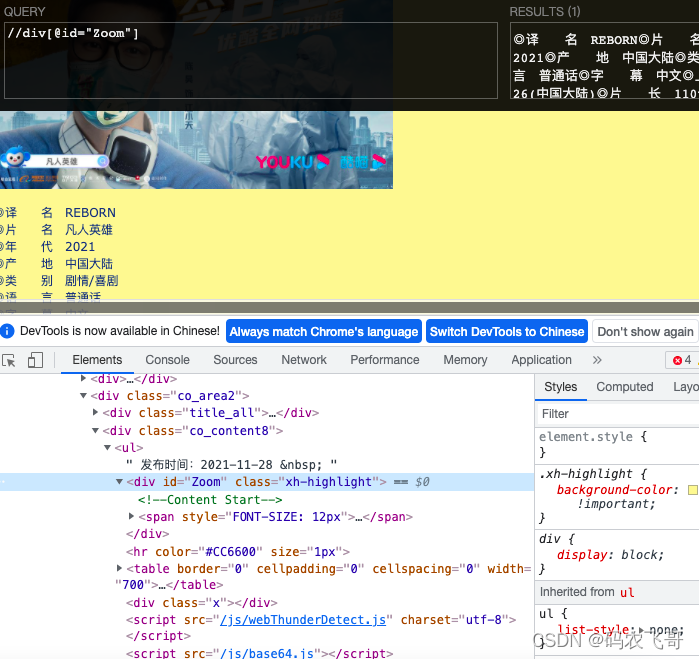
其他的基本信息均被<br>标签分割。所以获取到//div[@id="Zoom"] 标签下的所有文本信息就可以获取到我们想要的数据了,然后就是对获取的数据进行匹配处理。下面就是完整代码。
movie = {}
# 获取所有信息
zoomE = html.xpath('//div[@id="Zoom"]')[0]
# 获取所有信息
infos = zoomE.xpath('.//text()')
for info in infos:
info = info.strip()
if info.startswith('◎译 名'):
movie['translate_name'] = info.replace('◎译 名', "")
elif info.startswith('◎片 名'):
movie['name'] = info.replace('◎片 名', "")
elif info.startswith('◎年 代'):
movie['year'] = info.replace('◎年 代', "")
elif info.startswith('◎产 地'):
movie['place'] = info.replace('◎产 地', "'")
elif info.startswith('◎上映日期'):
movie['release_time'] = info.replace('◎上映日期', "")
elif info.startswith('◎豆瓣评分'):
movie['score'] = info.replace('◎豆瓣评分', "")
elif info.startswith('◎片 长'):
movie['film_time'] = info.replace('◎片 长', "")
elif info.startswith('◎导 演'):
movie['director'] = info.replace('◎导 演', "")
elif info.startswith('◎主 演'):
# 获取演员
index = infos.index(info)
info = info.replace('◎主 演', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith('◎标 签'):
movie['label'] = info.replace('◎标 签', "")
elif info.startswith('◎简 介'):
try:
index = infos.index(info)
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('磁力链'):
break
movie['profile'] = profile
except Exception:
pass
这里定义了一个movie字典用于存放所获取到的电影详细信息。这里遍历获取到的所有数据,通过字符串匹配的方法获取每一行数据。
以译名为例,首先,匹配当前的字符串是否是以◎译 名 开头。如果是话的,则将◎译 名 替换掉,就得到我们想要的数据REBORN 了。
其他的片名,产地也是一样的原理,在此就不在赘述了。
重点需要说下的是:主演的信息,因为主演不止一个,所有需要特殊的处理下。
elif info.startswith('◎主 演'):
# 获取演员
index = infos.index(info)
info = info.replace('◎主 演', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
首先是获取当前信息info在infos列表中的位置index,就是定义一个列表,列表中的第一个元素就是排名在第一的主演姓名。
接着遍历infos中的元素。遍历的起始位置是index+1,结束位置是 len(infos) 不包括该位置。
当匹配到下一个◎符号是该循环结束。
多线程操作
正如标题所说,为了提高爬虫效率,这里将每个页面的数据爬取任务交给一个单独的线程来执行。这些线程由线程池来管理。具体代码是:
from multiprocessing.pool import ThreadPool
#创建一个大小为20的线程池
page_pool = ThreadPool(processes=20)
#异步请求详情页的数据
page_pool.apply_async(func=get_current_page_detail_url,
args=(
BASE_DOMAIN + '/html/gndy/dyzz/' + 'list_23_' + str(
current_page) + '.html',))
保存数据
这里将爬取的数据简单的保存到txt文本中。保存数据的代码是:
def save_data(content):
content_json = json.dumps(content, ensure_ascii=False)
with open(file='content.txt', mode='a', encoding='utf-8') as f:
f.write(content_json + '\n')
最终完整源代码
# -*- utf-8 -*-
"""
@url: https://blog.csdn.net/u014534808
@Author: 码农飞哥
@File: list.py
@Time: 2021/12/3 10:15
@Desc: 爬取列表页
"""
from lxml import etree
import requests
from multiprocessing.pool import ThreadPool
import threading
import json
BASE_DOMAIN = 'https://www.ygdy8.net'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36',
'Cookie': 'XLA_CI=f6efcd6e626919703161043f280f26e6'
}
BASE_ENCODING = 'gbk'
page_pool = ThreadPool(processes=20)
# 获取所有页面的地址
def get_total_page():
url = 'https://www.ygdy8.net/html/gndy/dyzz/index.html'
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
total_pages_element = html.xpath('//div[@class="x"]//text()')[1].strip()
start_index = total_pages_element.find('共')
end_index = total_pages_element.find('页')
total_pages = total_pages_element[start_index + 1:end_index]
for current_page in range(1, int(total_pages)):
page_pool.apply_async(func=get_current_page_detail_url,
args=(
BASE_DOMAIN + '/html/gndy/dyzz/' + 'list_23_' + str(
current_page) + '.html',))
def get_current_page_detail_url(page_url):
resp = requests.get(page_url, headers=headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
# 获取电影详情页的地址
detail_url_list = html.xpath('//table[@class="tbspan"]//a/@href')
new_detail_url_list = [BASE_DOMAIN + detail_url for detail_url in detail_url_list]
movies = []
for detail_url in new_detail_url_list:
print(threading.current_thread().getName() + " " + detail_url)
movies.append(get_movie_detail(detail_url))
save_data(movies)
return movies
def get_movie_detail(movie_url):
resp = requests.get(movie_url, headers)
html = etree.HTML(resp.content.decode(BASE_ENCODING))
movie = {}
# 获取电影标题
movie_title = html.xpath('//div[@class="title_all"]//font/text()')[0].strip()
movie['movie_title'] = movie_title
# 获取发布时间
publish_time = html.xpath('//div[@class="co_content8"]/ul/text()')[0].strip()
movie['publish_time'] = publish_time
# 获取电影海报
movie_poster_url = html.xpath('//div[@class="co_content8"]//img/@src')[0].strip()
movie['movie_poster_url'] = movie_poster_url
# 获取所有信息
zoomE = html.xpath('//div[@id="Zoom"]')[0]
# 获取所有信息
infos = zoomE.xpath('.//text()')
for info in infos:
info = info.strip()
if info.startswith('◎译 名'):
movie['translate_name'] = info.replace('◎译 名', "")
elif info.startswith('◎片 名'):
movie['name'] = info.replace('◎片 名', "")
elif info.startswith('◎年 代'):
movie['year'] = info.replace('◎年 代', "")
elif info.startswith('◎产 地'):
movie['place'] = info.replace('◎产 地', "'")
elif info.startswith('◎上映日期'):
movie['release_time'] = info.replace('◎上映日期', "")
elif info.startswith('◎豆瓣评分'):
movie['score'] = info.replace('◎豆瓣评分', "")
elif info.startswith('◎片 长'):
movie['film_time'] = info.replace('◎片 长', "")
elif info.startswith('◎导 演'):
movie['director'] = info.replace('◎导 演', "")
elif info.startswith('◎主 演'):
# 获取演员
index = infos.index(info)
info = info.replace('◎主 演', "")
actors = [info]
for x in range(index + 1, len(infos)):
actor = infos[x].strip()
if actor.startswith("◎"):
break
actors.append(actor)
movie['actors'] = actors
elif info.startswith('◎标 签'):
movie['label'] = info.replace('◎标 签', "")
elif info.startswith('◎简 介'):
try:
index = infos.index(info)
for x in range(index + 1, len(infos)):
profile = infos[x].strip()
if profile.startswith('磁力链'):
break
movie['profile'] = profile
except Exception:
pass
return movie
def save_data(content):
content_json = json.dumps(content, ensure_ascii=False)
with open(file='content.txt', mode='a', encoding='utf-8') as f:
f.write(content_json + '\n')
if __name__ == '__main__':
get_total_page()
page_pool.close()
page_pool.join()
最终运行效果

最后说点
本文以电影天堂为例,主要是运用所学的xpath表达式,requests库的相关知识点进行爬虫。

- 点赞
- 收藏
- 关注作者
评论(0)