我,30岁了,还在为涨粉而抓耳挠腮,自研工具让我找到了方向。。。。

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
😁 1. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
💪🏻 2. Python基础专栏,基础知识一网打尽。 Python从入门到精通
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
为什么写这篇文章?
看着别人家博主的粉丝量蹭蹭的往上涨,看着别人家社区搞得红红火火。老实说我真的很焦虑,太焦虑了。该怎么办呢?
帖子太多了,没时间一一审核怎么办?优秀的帖子来不及加精怎么办?社区帖子杂乱无章怎么办?难道只能到管理后台一条条点么?
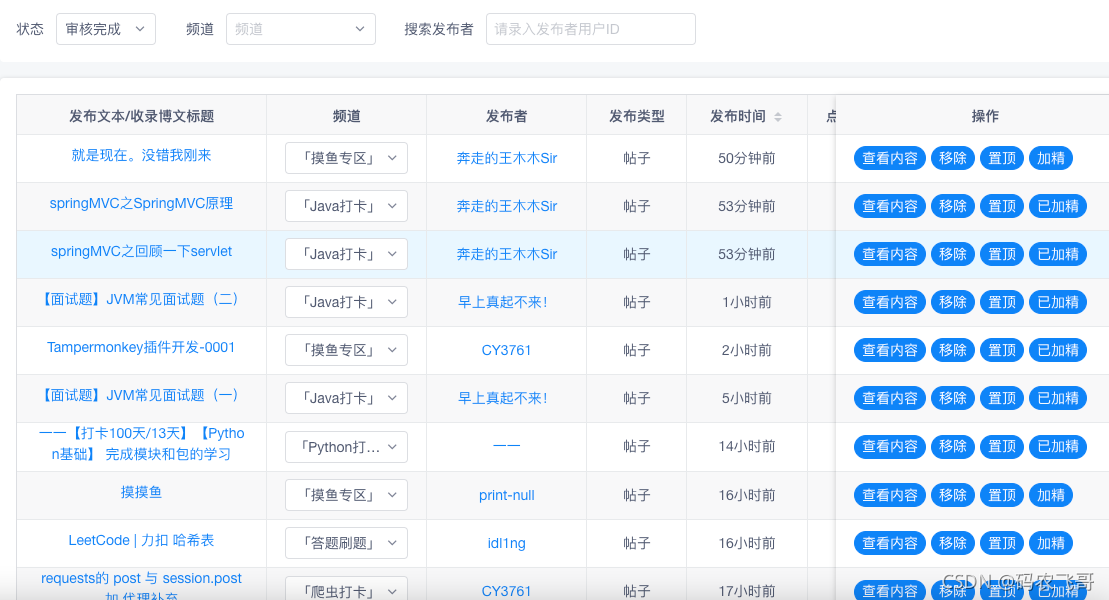
我苦思冥想,思前想后,觉得还是应该用程序去自动帮我们处理这些问题,用程序去自动帮我们给好文章加精,移除无意义的灌水贴,整理帖子的分组。这就开始了下面这篇文章。
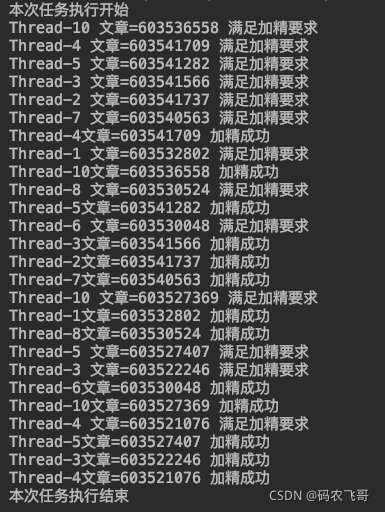
先看看效果
本小工具的作用就是每日定时执行任务,将满足一定我们预设要求对优秀的文章进行加精处理,对不符合要求的灌水文章进行移除。。这样就可以可以大大减轻人工审核的成本。让管理员专注于更有意义的事情。
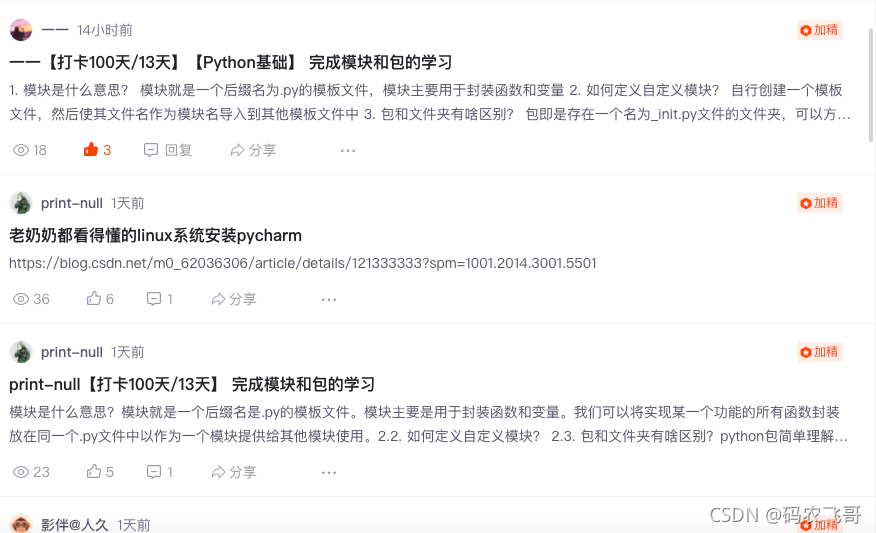
怎么使用?
首先是下载源代码,点击https://docs.qq.com/doc/DUFJ0REhIRHFJdHlL

安装依赖库
源代码下载之后,安装好如下依赖库
pip install lxml
pip install requests
pip install urllib3
修改社区ID以及cookie
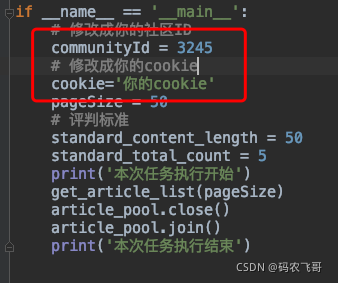
if __name__ == '__main__':
# 修改成你的社区ID
communityId = 3245
# 修改成你的cookie
cookie='你的cookie'
pageSize = 50
# 评判标准
standard_content_length = 50
standard_total_count = 5
print('本次任务执行开始')
get_article_list(pageSize)
article_pool.close()
article_pool.join()
print('本次任务执行结束')
代码说明,这里:
communityId:指你当前的社区ID,
cookie :就是你当前请求的cookie,
pageSize:每页条数表示一次查询的数据量,默认是50条,如果数据量大的话可以加大。
standard_content_length: 表示文章内容的长度,默认是文章内容最少要达到50个字符
standard_total_count: 表示点赞和评论的总数量,默认是不少于5个。
怎么实现的?
怎么实现的呢?本质上还是通过程序去自动调用CSDN相关功能的接口,从而代替了人工调用。下面都是以码农飞哥社区为例进行说明。
第一步:查找相关接口
首先,从码农飞哥社区主页 点击 管理社区 按钮 进入社区管理后台,然后点击内容 tab 页面—》内容管理。F12看下调用的相关接口。相关接口如下图1所示。
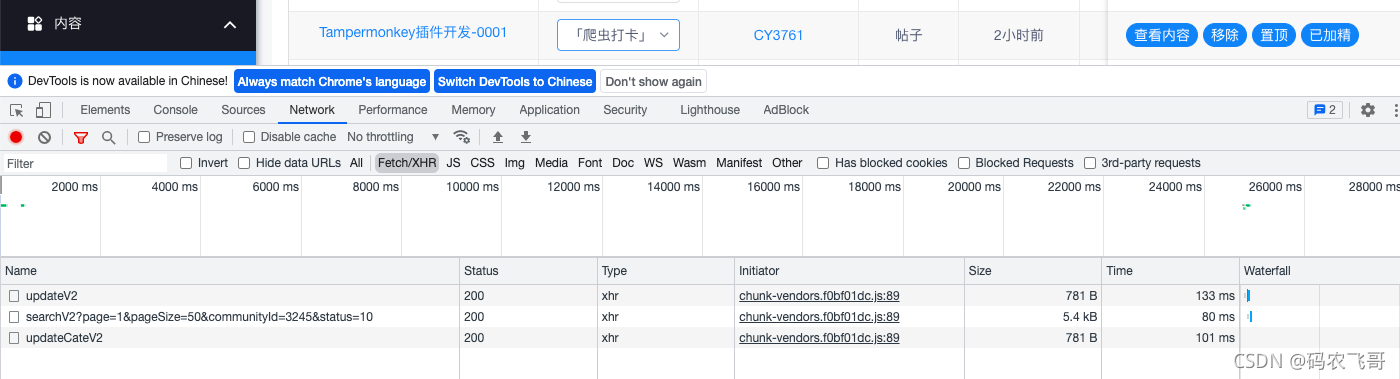
图1展示了内容管理涉及到的几个重要的接口。其中:
- updateV2 接口用于置顶和加精操作
- searchV2 接口用于查询内容列表
- updateCateV2 接口用于将文章移动到不同的频道中。
第二步:调用相关接口
确定好调用的相关接口之后,接下来就是调用每个接口了。首先,让我们来看下直接调用接口。这里以最简单内容列表查询接口为例,因为该接口是一个Get请求的接口。可以直接在浏览器上输入访问。https://bizapi.csdn.net/community-cloud/v1/admin/api/content/searchV2?page=1&pageSize=50&communityId=3245&status=10,访问结果如下图2所示。
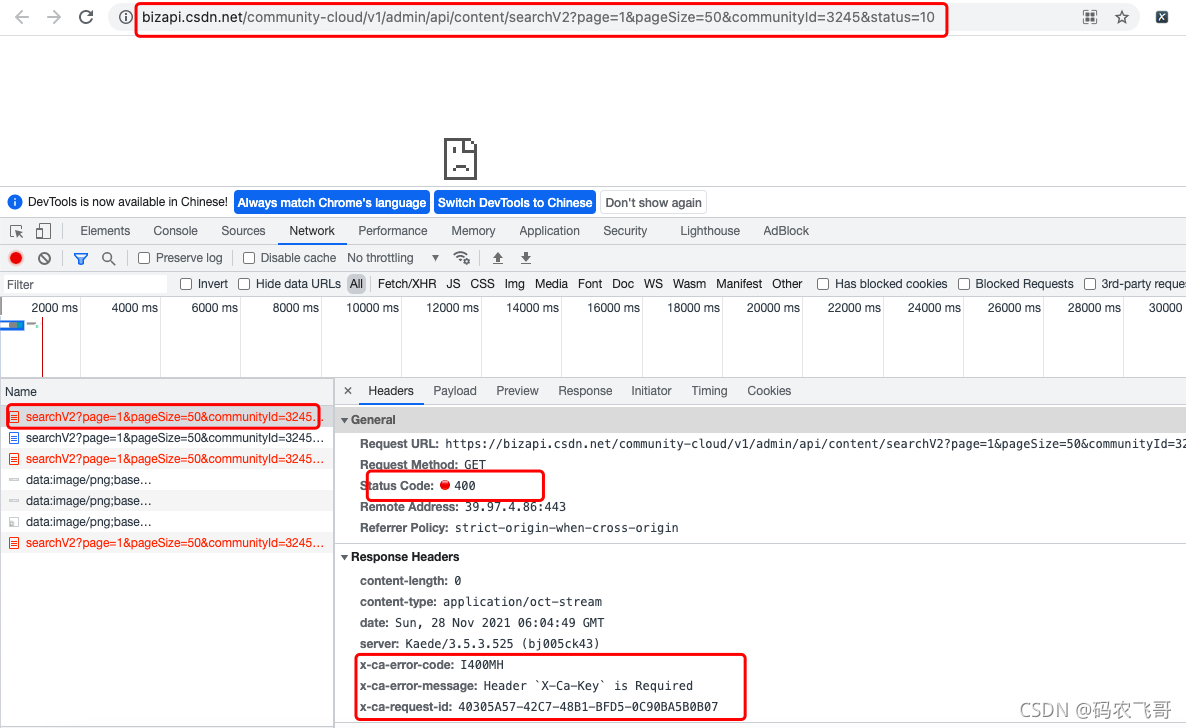
不幸的是,直接在浏览器上访问该接口报了个400的错误。F12看了下,原来是请求头中缺少了 x-ca-key 这个属性。
进一步分析,x-ca-key 是个啥东东
在回到我们前面打开的那个内容管理页面查看下原来他们那个x-ca-key属性是个啥东西。如下图3和图4所示。
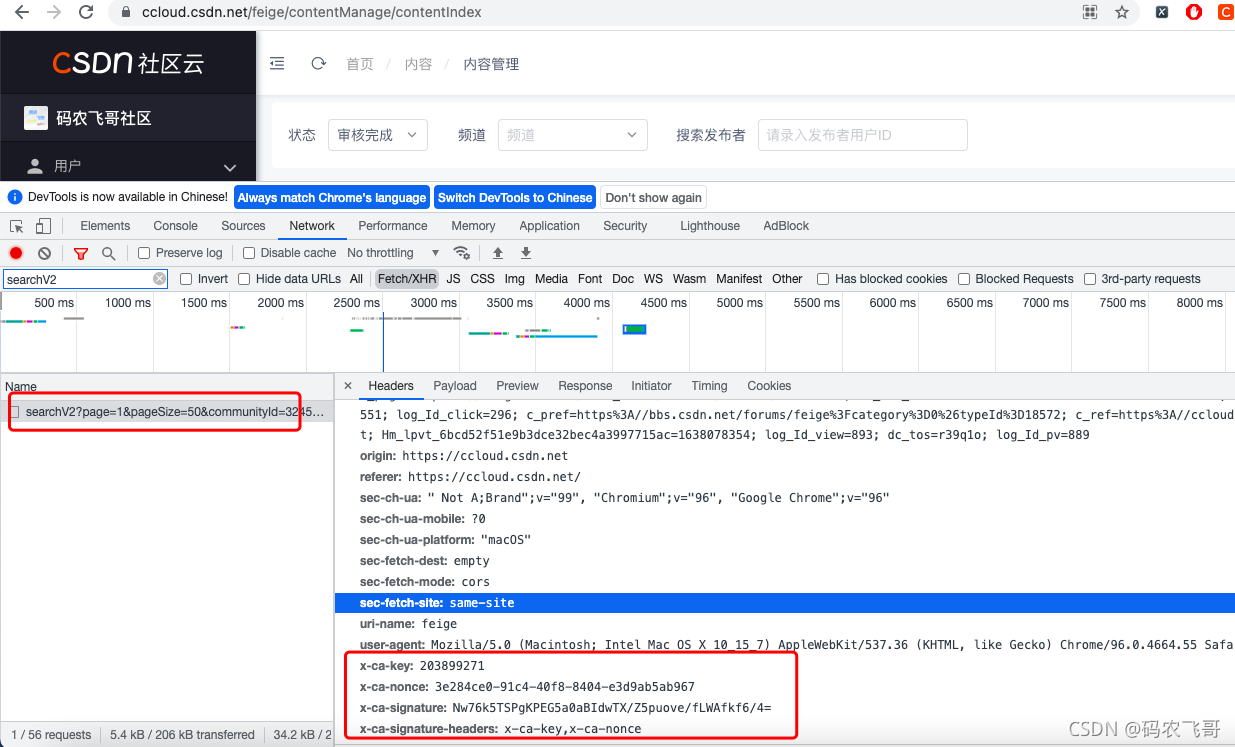
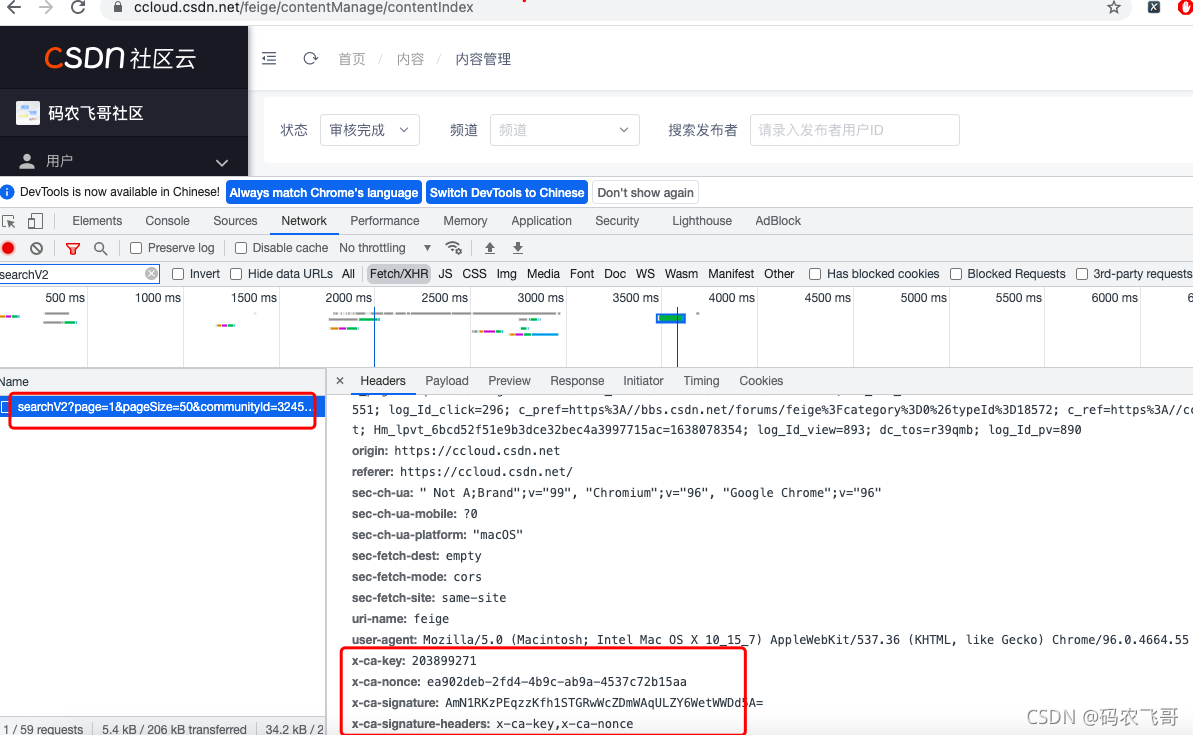
从图3和图4,我们不难看出,在每次请求接口的时候都会在请求头中传入x-ca-key;x-ca-nonce;x-ca-signature;x-ca-signature-headers这四个参数。简单的分析不难得出x-ca-key和x-ca-signature-headers是两个固定值。而x-ca-signature和x-ca-signature-headers 每次请求的时候都不同,这就有点难顶了。
该怎么知道x-ca-signature和x-ca-signature-headers 的生成机制呢?
调试x-ca-signature和x-ca-signature-headers的生成机制真的是一段痛苦的回忆。这玩意有点难搞。在 source—>js 中点开每个js文件进行匹配查找。默认情况下这里的js文件都是被压缩过的,如下图5所示,非常不方便查找。这里就需要点击Pretty-print 按钮进行美化输出。
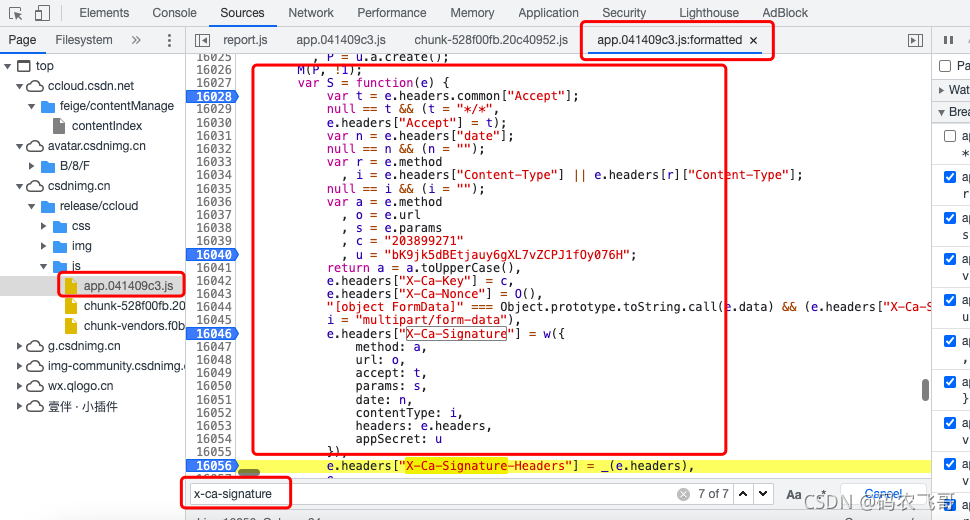
美化后的结果结果如下图6所示。很幸运的是通过变量名匹配在 app.041409c3.js 文件中找到了x-ca-signature的生成代码。
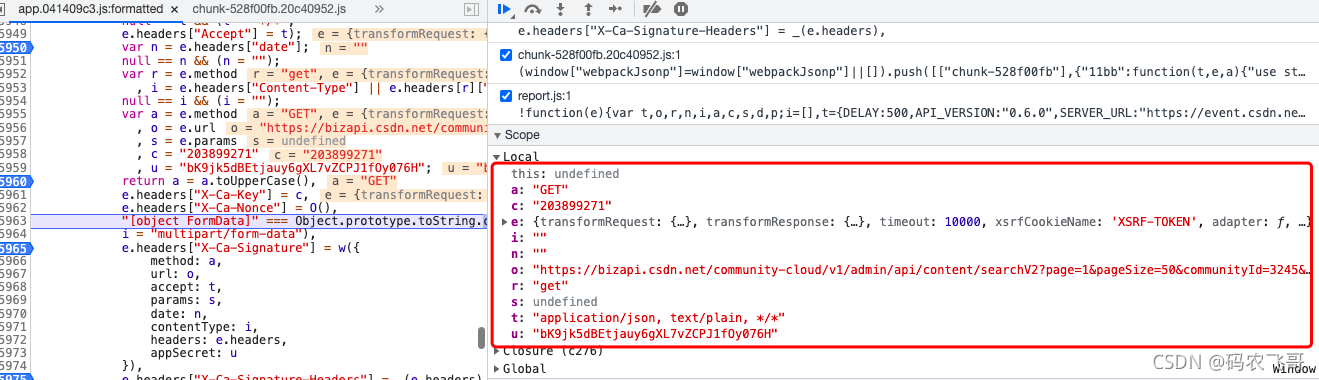
x-ca-nonce的代码如下图7所示:

接下来就是一番痛苦的js调试工作,调试的部分截图如下图8所示:
直接上代码吧:
1. 生成x-ca-nonce的代码如下所示:
#x-ca-nonce
def createUuid():
text = ""
char_list = []
for c in range(97, 97 + 6):
char_list.append(chr(c))
for c in range(49, 58):
char_list.append(chr(c))
for i in "xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx":
if i == "4":
text += "4"
elif i == "-":
text += "-"
else:
text += random.choice(char_list)
return text
2. 生成x-ca-signature代码如下所示:
def get_sign(uuid, url, method):
s = urlparse(url)
ekey = "bK9jk5dBEtjauy6gXL7vZCPJ1fOy076H".encode()
if method == 'get':
to_enc = f"GET\n{accept}\n\n\n\nx-ca-key:{xcakey}\nx-ca-nonce:{uuid}\n{s.path+'?'+s.query}".encode()
else:
to_enc = f"POST\n{accept}\n\n{content_type}\n\nx-ca-key:{xcakey}\nx-ca-nonce:{uuid}\n{s.path}".encode()
sign = b64encode(hmac.new(ekey, to_enc, digestmod=hashlib.sha256).digest()).decode()
return sign
这里特别需要注意的是在生成x-ca-signature时,POST请求和GET请求并不相同,我们需要区分处理。最明显的两个区别是请求方法Method不同,content_type不同。
第三步:实现我们想要的逻辑
最关键的一步搞定了,接下来就是实现我们想要的逻辑了。首先是调用获取帖子列表的接口,运行的结果是:

这里特别特别需要注意的是:请求头一定不能搞错了。
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'origin': 'https://ccloud.csdn.net',
'referer': 'https://ccloud.csdn.net/',
'sec-ch-ua': '"Google Chrome";v="96", "Chromium";v="96", ";Not A Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'uri-name': 'feige',
'cookie': 改成你的cookie
}
CSDN对请求头的校验非常严格,这里请求头的相关参数缺一不可。一定要切记切记。
这里提供一下调用searchV2接口的相关代码。
search_list_url = 'https://bizapi.csdn.net/community-cloud/v1/admin/api/content/searchV2'
def get_article_list(pageSize):
if pageSize is None:
pageSize = 50
param = {
'communityId': communityId,
'page': 1,
'pageSize': pageSize,
'status': 10
}
new_search_list_url = search_list_url + '?' + parse.urlencode(param)
get_ca_sign(new_search_list_url, headers, 'get')
resp = requests.get(new_search_list_url, headers=headers, verify=False)
# 查询所有的文章
if resp.status_code == 200:
resp_dict = resp.json()
print(resp_dict)
最后说点
这个小工具本质上不难,就是调用CSDN的接口。难点主要是在于请求头中x-ca-nonce和x-ca-signature这两个参数比较难搞。搞定了这两个参数后面的调用逻辑就比较简单。

- 点赞
- 收藏
- 关注作者
评论(0)