Hadoop 3.3.0 单机环境配置

配置环境变量
首先修改当前用户的配置文件,添加 Hadoop 环境变量。修改 ~/.bashrc

Hadoop 解压后即可使用。通过在任意路径下,使用 hadoop version 查看 Hadoop 版本,来判断是否配置成功

启动 与 停止
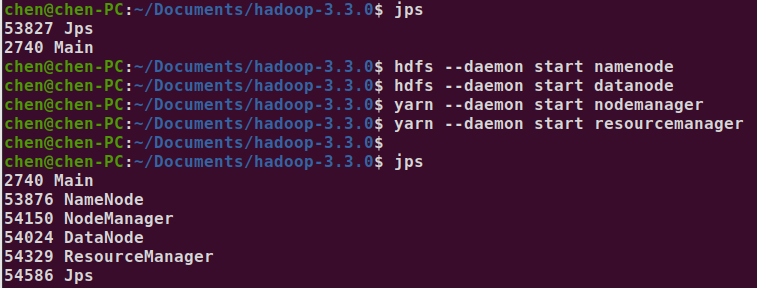
启动 namenode、datanode、resourcemanager
hdfs --daemon start namenode
hdfs --daemon start datanode
yarn --daemon start nodemanager
yarn --daemon start resourcemanager
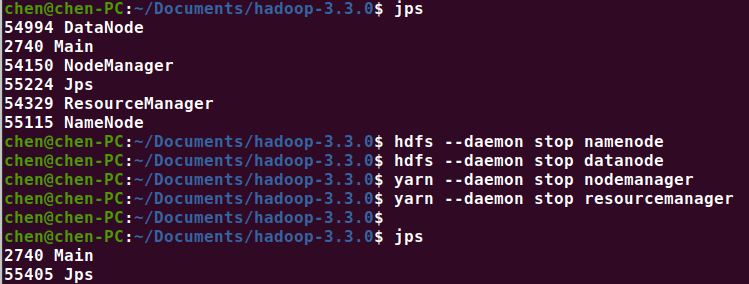
停止 namenode、datanode、resourcemanager
hdfs --daemon stop namenode
hdfs --daemon stop datanode
yarn --daemon stop nodemanager
yarn --daemon stop resourcemanager
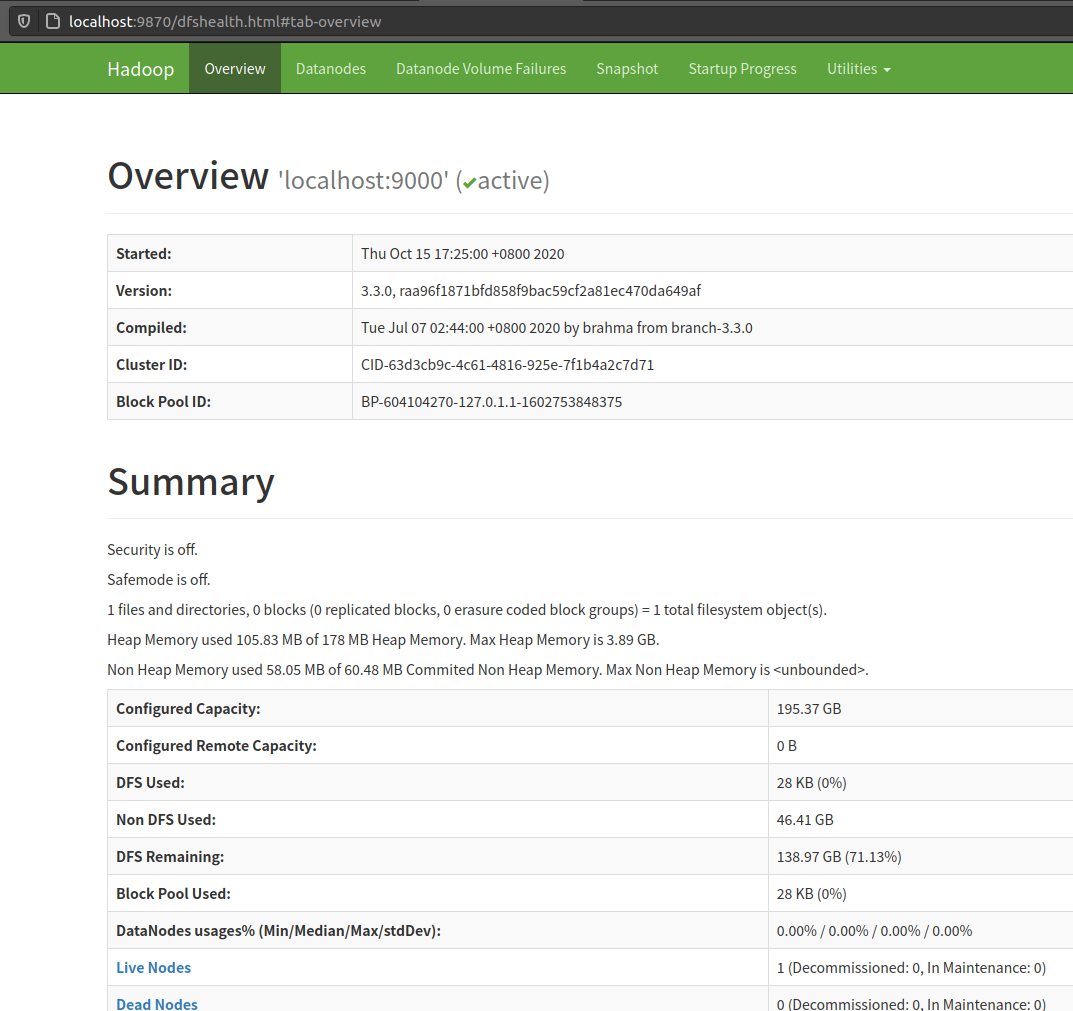
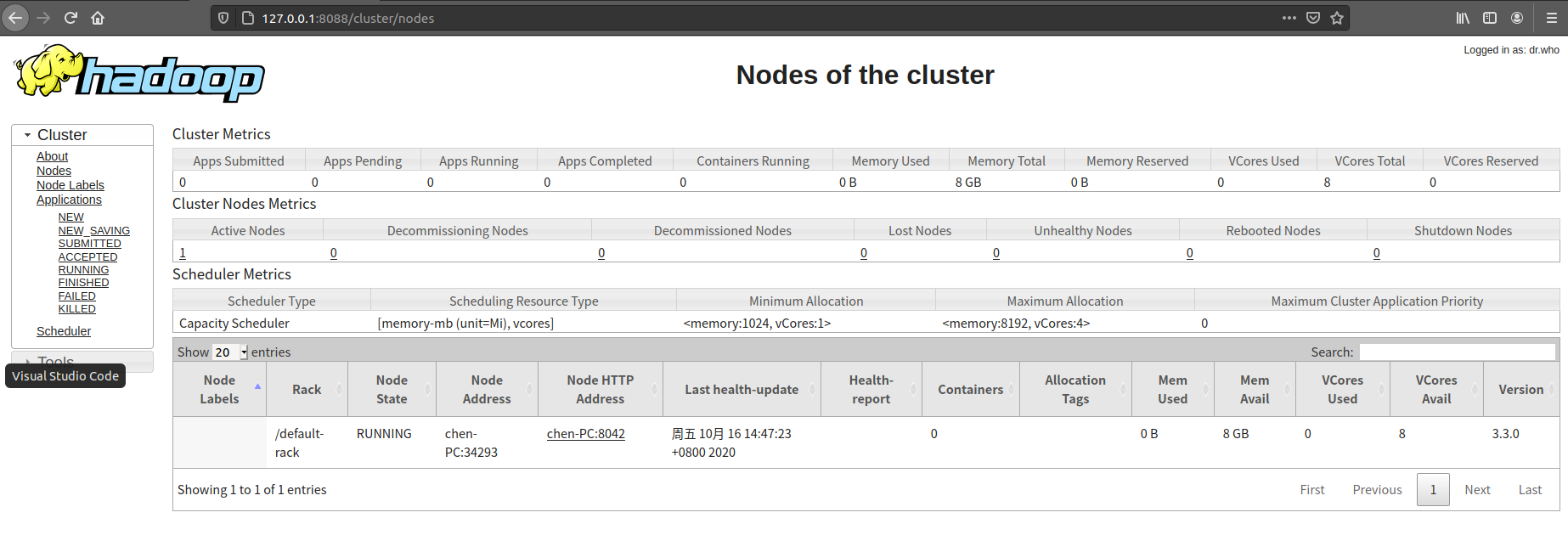
WEB 管理页
- hdfs健康信息 http://localhost:9870
- hadoop集群信息 http://127.0.0.1:8088/
It looks like you are making an HTTP request to a Hadoop IPC port. This is not the correct port for the web interface on this daemon.
如果出现这段英文,这说明你的配置包括进程启动都没问题,你只是访问了进程中的非web端口

Hadoop单机配置(非分布式)
Hadoop 默认模式为非分布式模式(本地模式),无需任何配置即可运行。通过以下命令,可以执行hadoop 自带的 demo。
这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统,一般仅用于本地MR程序的调试
使用如下命令可以查看可用demo
cd ${HADOOP}
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar
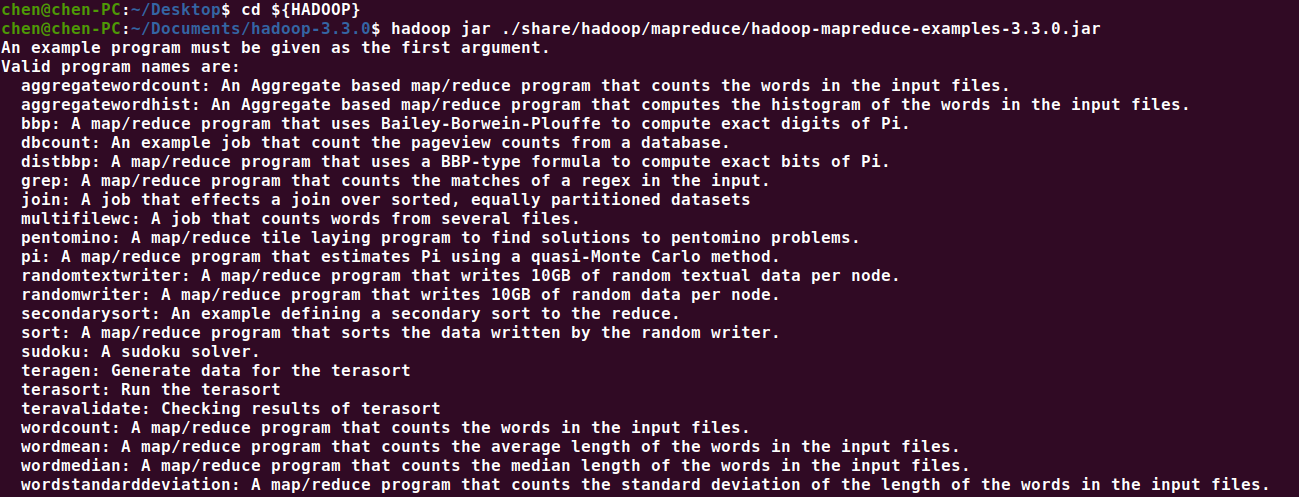
可以看到 hadoop 自带了很多 example
An example program must be given as the first argument.
Valid program names are:
- aggregatewordcount: An Aggregate based map/reduce program that counts the words in the input files.
- aggregatewordhist: An Aggregate based map/reduce program that computes the histogram of the words in the input files.
- bbp: A map/reduce program that uses Bailey-Borwein-Plouffe to compute exact digits of Pi.
- dbcount: An example job that count the pageview counts from a database.
- distbbp: A map/reduce program that uses a BBP-type formula to compute exact bits of Pi.
- grep: A map/reduce program that counts the matches of a regex in the input.
- join: A job that effects a join over sorted, equally partitioned datasets
- multifilewc: A job that counts words from several files.
- pentomino: A map/reduce tile laying program to find solutions to pentomino problems.
- pi: A map/reduce program that estimates Pi using a quasi-Monte Carlo method.
- randomtextwriter: A map/reduce program that writes 10GB of random textual data per node.
- randomwriter: A map/reduce program that writes 10GB of random data per node.
- secondarysort: An example defining a secondary sort to the reduce.
- sort: A map/reduce program that sorts the data written by the random writer.
- sudoku: A sudoku solver.
- teragen: Generate data for the terasort
- terasort: Run the terasort
- teravalidate: Checking results of terasort
- wordcount: A map/reduce program that counts the words in the input files.
- wordmean: A map/reduce program that counts the average length of the words in the input files.
- wordmedian: A map/reduce program that counts the median length of the words in the input files.
- wordstandarddeviation: A map/reduce program that counts the standard deviation of the length of the words in the input files.
下面测试 grep 小程序
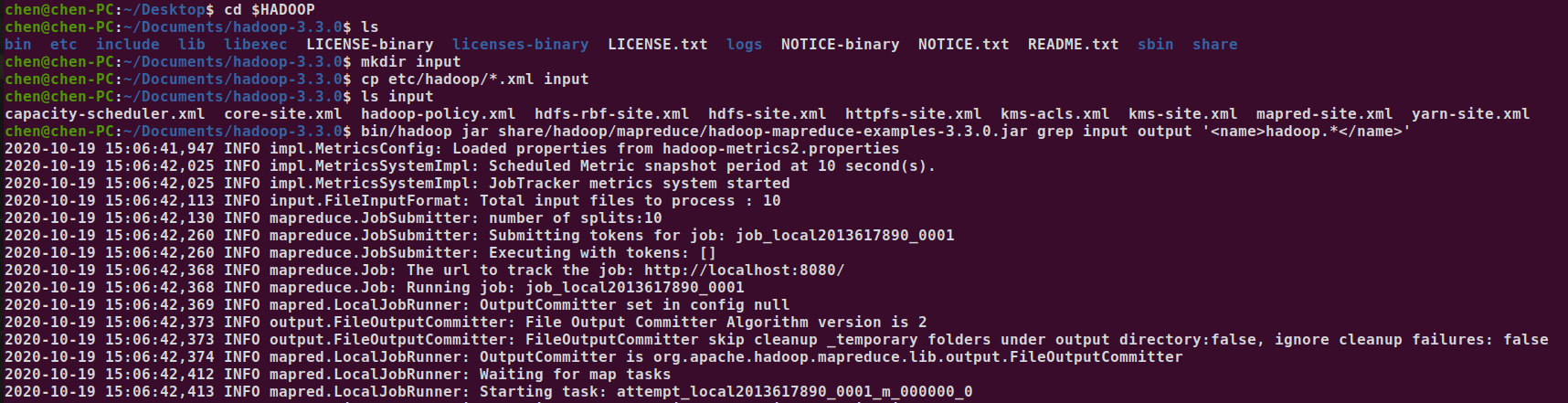
cd $HADOOP
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoopmapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output '<name>hadoop.*</name>'
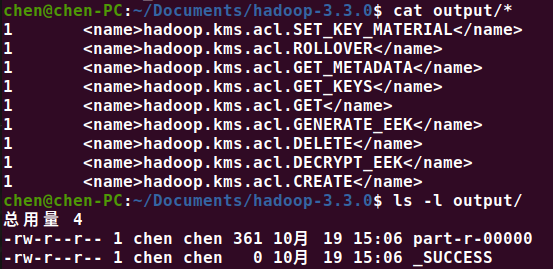
查看执行结果
- _SUCCESS 是一个空文件,标志执行成功
- part-r-00000 保存了执行结果

Hadoop伪分布式配置
这种模式也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点 (NameNode, DataNode, JobTracker, TaskTracker, SecondaryNameNode)
请注意分布式运行中的这几个结点的区别:
- 从分布式存储的角度来说,集群中的结点由一个NameNode和若干个DataNode组成,另有一个SecondaryNameNode作为NameNode的备份。
- 从分布式应用的角度来说,集群中的结点由一个JobTracker和若干个TaskTracker组成,JobTracker负责任务的调度,TaskTracker负责并行执行任务。TaskTracker必须运行在DataNode上,这样便于数据的本地计算。JobTracker和NameNode则无须在同一台机器上。一个机器上,既当namenode,又当datanode,或者说 既 是jobtracker,又是tasktracker。没有所谓的在多台机器上进行真正的分布式计算,故称为"伪分布式"。开启多个进程模拟完全分布式,但是并没有真正提高程序执行的效率
如果像单机模式一样直接启动,会报错 hdfs://localhost:9000 连接不上,解决办法是启动 namenode 和 datanode

在未做任何配置的情况下,namenode是无法直接启动的,会报 Error: Cannot set priority of namenode process 57675 的错误(datanode到是可以直接启动的)

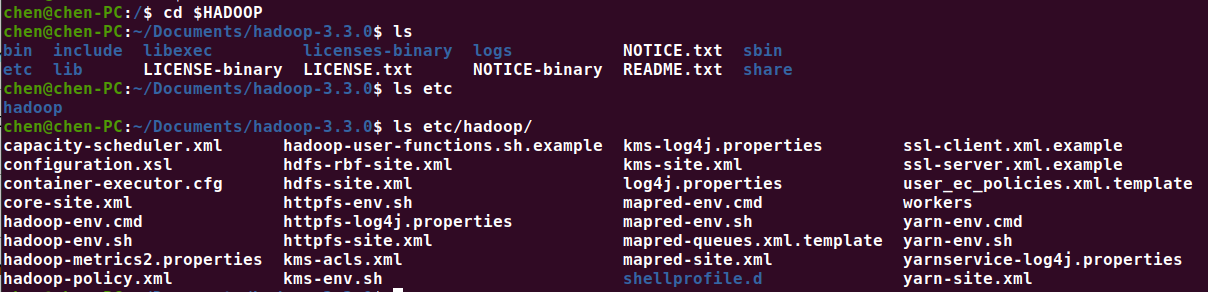
需要修改 Hadoop 的配置文件,位置在 $HADOOP/etc/hadoop/ 目录下。要操作如下3个配置文件:
- core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)
- hdfs-site.xml(配置HDFS集群的工作属性)
- mapred-site.xml(配置MapReduce集群的属性)
etc/hadoop/core-site.xml是必须修改的。
要添加hadoop.tmp.dir和fs.defaultFS属性。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/chen/.hadoop/tmp</value>
<description>a temporary directory for hadoop</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
/etc/hadoop/hdfs-site.xml(非必须,可不修改,不影响运行)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
/etc/hadoop/yarn-site.xml(非必须,可不修改,不影响运行)
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
修改后启动 namenode 和 datanode。 但依旧会报错,因为 hdfs://localhost:9000/user/<用户名>/input 文件夹不存在

初次使用 hadoop 时,它的目录下并没有任何文件。也就是说初次使用ls,只有 hadoop fs -ls / 是正确的。hadoop 可以通过和 linux 一样的命令创建和操作文件或文件夹,唯一的区别就是需要加上 hadoop fs 的前缀
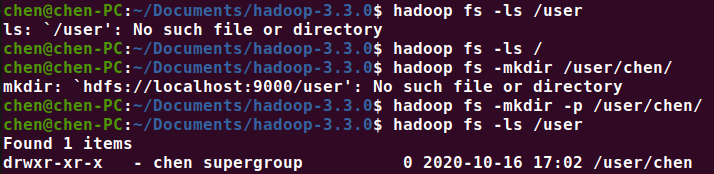
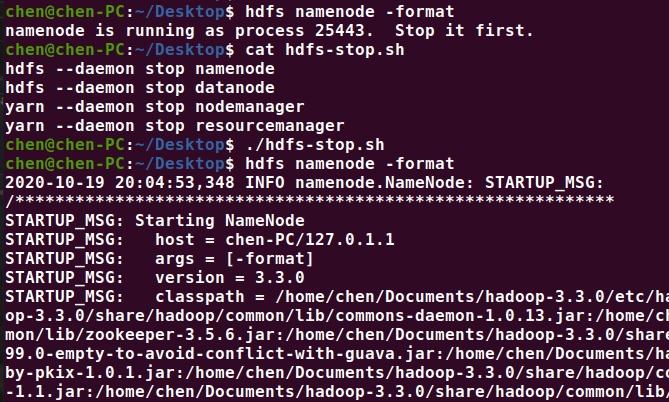
很多文章说,第一次使用 hadoop的时候要格式化 hdfs namenode -format(实验后发现貌似不格式化也行),另外格式化之前,必须关闭 hdfs 服务。
hdfs --daemon stop namenode
hdfs --daemon stop datanode
hdfs namenode -format
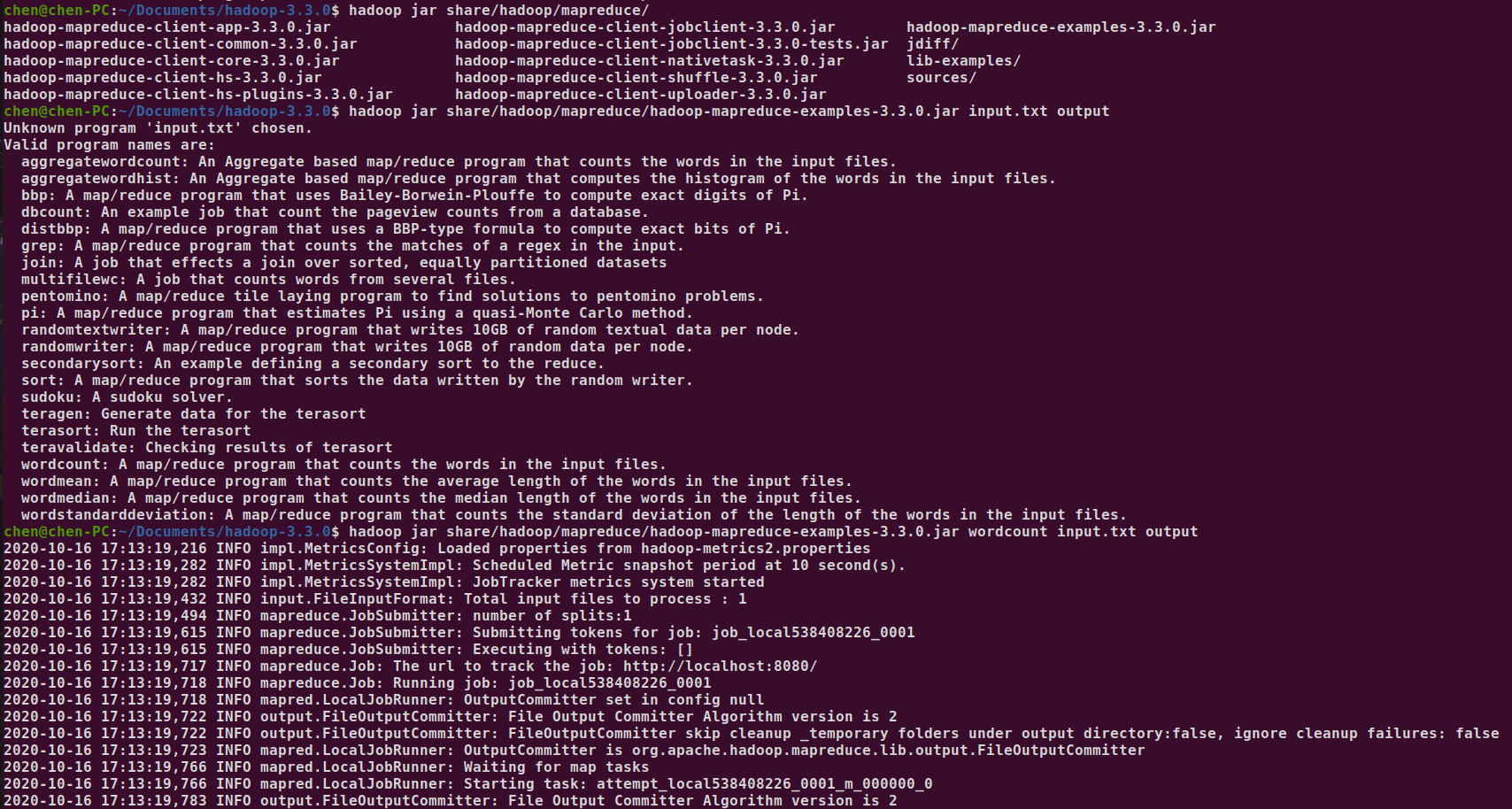
下面将外部已经创建好的文件夹包括里面的文件送入hadoop的hdfs里,使用put命令(test.txt 是一篇纯英文的新闻)
命令为 hadoop fs -put <待传入的文件> <保存路径>

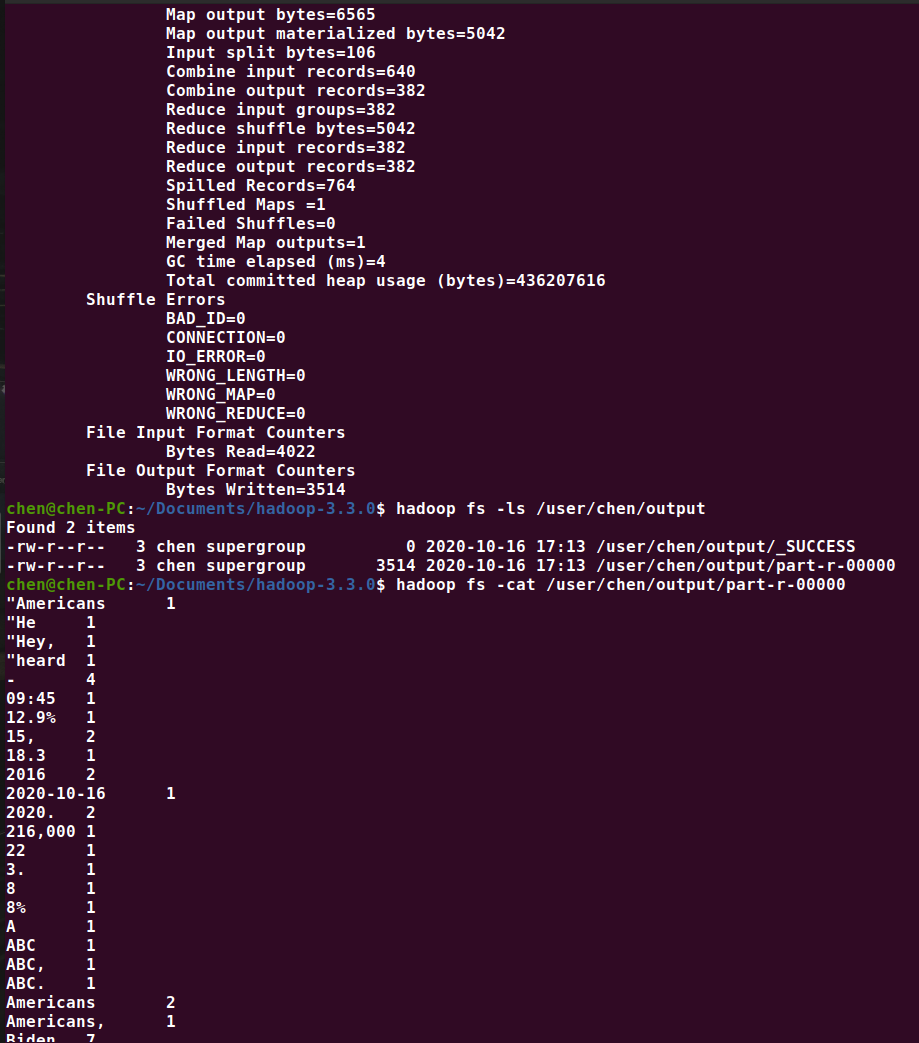
下面运行测试程序 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount input.txt output,成功的话,会打印日志信息,失败则会报错。
如果成功,在 hdfs 的 output 目录下会生成一个 SUCCESS 文件,另一个文件是处理输出结果。
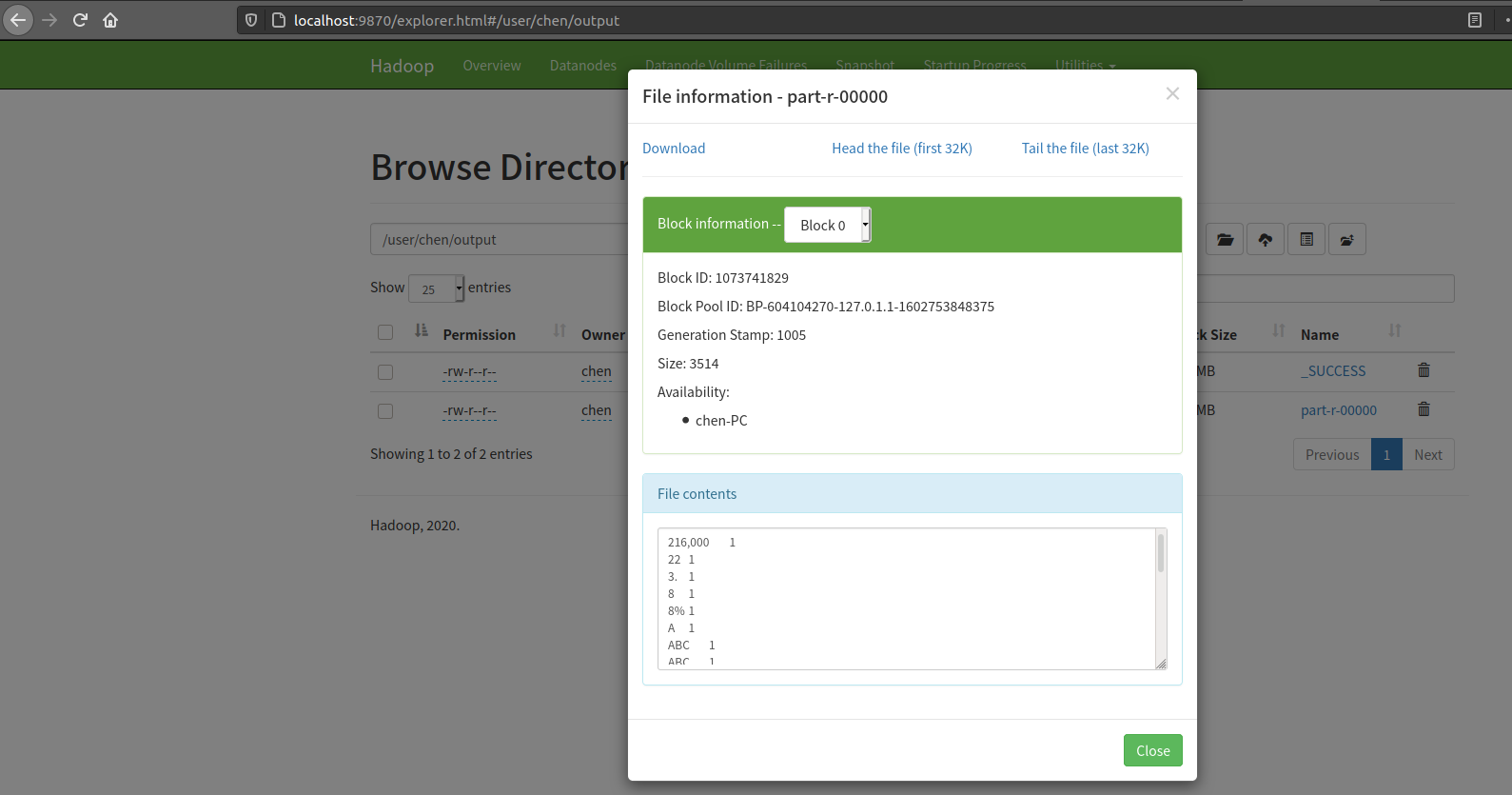
除了命令行查看,我们还可以使用管理网页的方式,进行查看 http://localhost:9870/explorer.html
比如我们要查看 datanode 的 /user/chen/output 目录下的文件,除了一级一级点进去,还可以直接输入 http://localhost:9870/explorer.html#/user/chen/output 进行访问

- 点赞
- 收藏
- 关注作者
评论(0)