Tomcat和搜索引擎网络爬虫的攻防

不知道广大程序员朋友们注意到一个现象么?使用百度是无法搜索到淘宝网的网页。为什么会造成这种现象?这就要从网络爬虫说起了。
咱们程序员假如自己搭设个人网站,在上面分享少量自己的技术文章,面临的一个重要问题就是让搜索引擎能够搜索到自己的个人网站,这样才能让更多的读者访问到。
而搜索引擎如百度和微软Bing搜索,Google搜索等通过什么方式才能收录我们的个人网站呢?
答案是搜索引擎的网络爬虫。 网络爬虫是一个很形象的名词,是属于搜索引擎的工具,只有被这些网络爬虫“爬过”的内容才有机会出现在对应搜索引擎的搜索结果中。
个人站长对网络爬虫是又爱又恨。一方面,网络爬虫可以让我们的个人网站出现在搜索结果里,对我们的个人网站进行扩散。另一方面,假如网络爬虫太多太频繁地访问个人网站,会肯定程度上影响正常使用户的请求解决。
于是就有了文章开头我提到的百度搜不到淘宝产品信息的文章。
在浏览器里输入https://www.taobao.com/robots.txt,
能看到淘宝网的一个文件robots.txt:

随意选一段解释:这个robots.txt的意思是,淘宝网做出了规定,假如网络请求来自百度爬虫(Baiduspider), 那么只允许(allow)百度爬虫读取article, oshtml和/ershou, 不允许读取的是product。
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Allow: /ershou
Disallow: /product/
Disallow: /
那么淘宝网怎样知道一个请求是来自百度爬虫,还是来自真正的使用户访问呢?答案就是HTTP请求的User-agent字段。
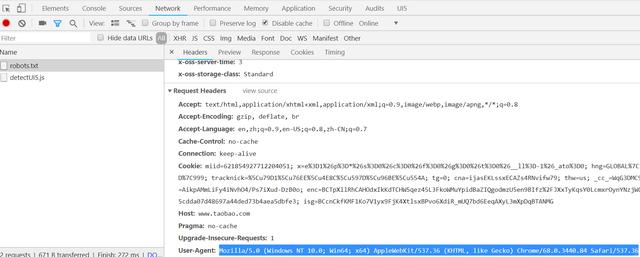
下图是我使用Chrome访问淘宝网的HTTP请求的User-agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.84 Safari/537.36
再回到Tomcat。假如有大量来自网络爬虫的读取请求,Web服务器需要为每一个请求创立一个session。当Session数量变得巨大时,消耗的服务器内存和资源也是巨大的。
因而,Tomcat对于来自网络爬虫的请求,用同一个session来解决。
我们打开Tomcat的源代码来学习。
Tomcat的源代码可以到其官网去下载:
https://tomcat.apache.org/download-70.cgi
点这个链接:

我下载的是7.0.90版本,只有7MB大。
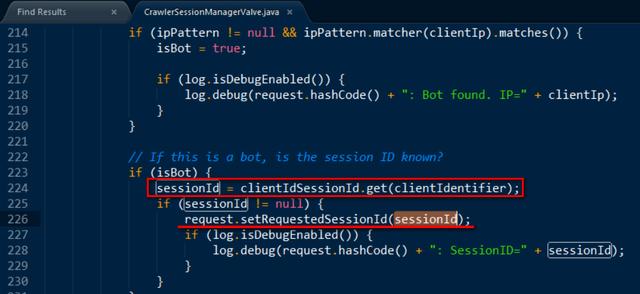
这里需要注意,即便Spider显式的传了一个 sessionId过来,也会弃使用,而是根据client Ip 来进行判断,即对于 相同的 Spider 只提供一个Session。
在下载好的源代码文件夹里,找到这个子文件夹:\apache-tomcat-7.0.90-src\java\org\apache\catalina\valves
打开CrawlerSessionManagerValve.java:
可以看到从第192行代码开始都是Tomcat使用来检测进来的网络请求能否是网络爬虫:

通过这个类里定义的正则表达式检测HTTP请求的user-agent字段来判断究竟该请求能否来自网络爬虫:
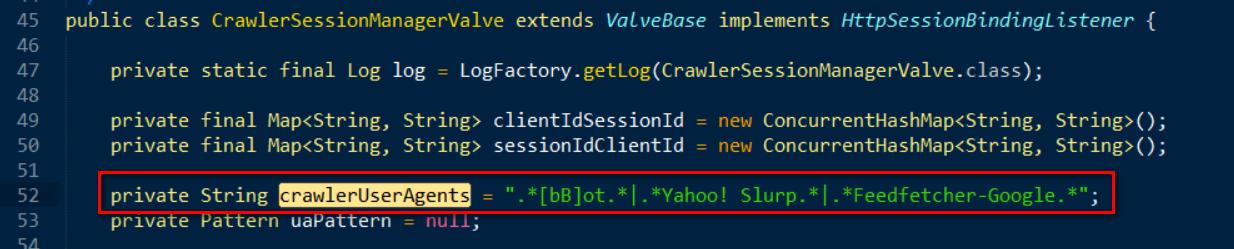
“.[bB]ot.|.Yahoo! Slurp.|.Feedfetcher-Google.”
一旦正则表达式在第205行匹配成功,将第206行的标志位设成true。

假如检测到是网络爬虫,则使用clientIdSessionId.get这个API获取Tomcat专门为网络爬虫预留的sessionId, 而后在第226行把该sessionId分配到进来的网络爬虫请求,这样就避免了白费太多的资源申请session来服务海量的网络爬虫请求,节省了Web服务器的资源。
要获取更多Jerry的原创技术文章,请关注公众号"汪子熙".

- 点赞
- 收藏
- 关注作者
评论(0)