大数据入门(五)-分布式计算框架MapReduce

【摘要】
1 概述
源自于Google的MapReduce论文,发表于2004年12月。
Hadoop MapReduce是Google MapReduce的克隆版
优点
海量数量离线处理 易开发 易运行 ...
1 概述
源自于Google的MapReduce论文,发表于2004年12月。
Hadoop MapReduce是Google MapReduce的克隆版
优点
海量数量离线处理
易开发
易运行
缺点
实时流式计算
2 MapReduce编程模型
wordcount词频统计

MapReduce执行流程
- 将作业拆分成Map阶段和Reduce阶段
- Map阶段: Map Tasks
- Reduce阶段、: Reduce Tasks
MapReduce编程模型执行步骤
- 准备map处理的输入数据
- Mapper处理
- Shuffle
- Reduce处理
- 结果输出

- InputFormat
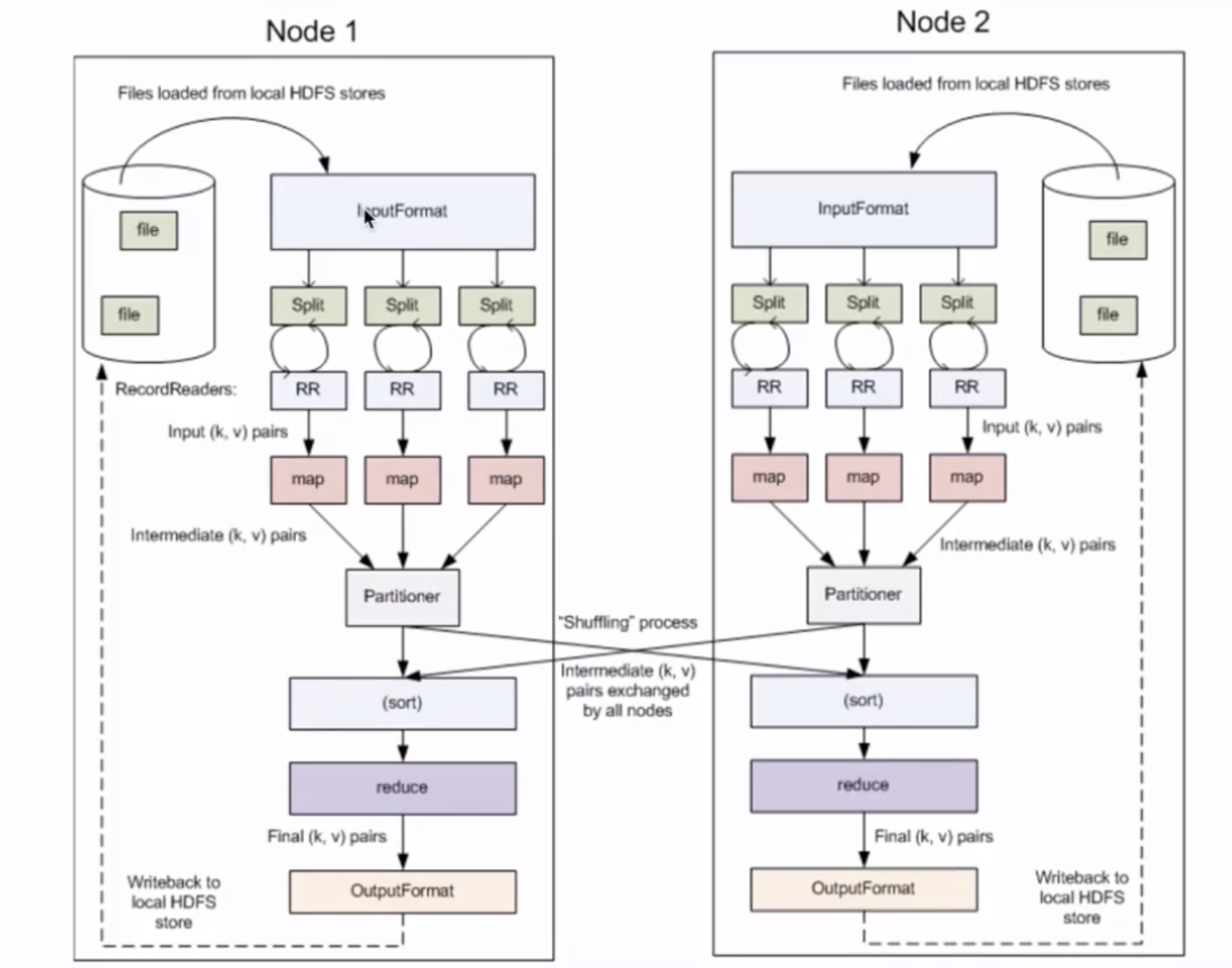




OutputFormat
OutputFormt接口决定了在哪里以及怎样持久化作业结果。Hadoop为不同类型的格式提供了一系列的类和接口,实现自定义操作只要继承其中的某个类或接口即可。你可能已经熟悉了默认的OutputFormat,也就是TextOutputFormat,它是一种以行分隔,包含制表符界定的键值对的文本文件格式。尽管如此,对多数类型的数据而言,如再常见不过的数字,文本序列化会浪费一些空间,由此带来的结果是运行时间更长且资源消耗更多。为了避免文本文件的弊端,Hadoop提供了SequenceFileOutputformat,它将对象表示成二进制形式而不再是文本文件,并将结果进行压缩。
3 核心概念
Split
InputFormat
OutputFormat
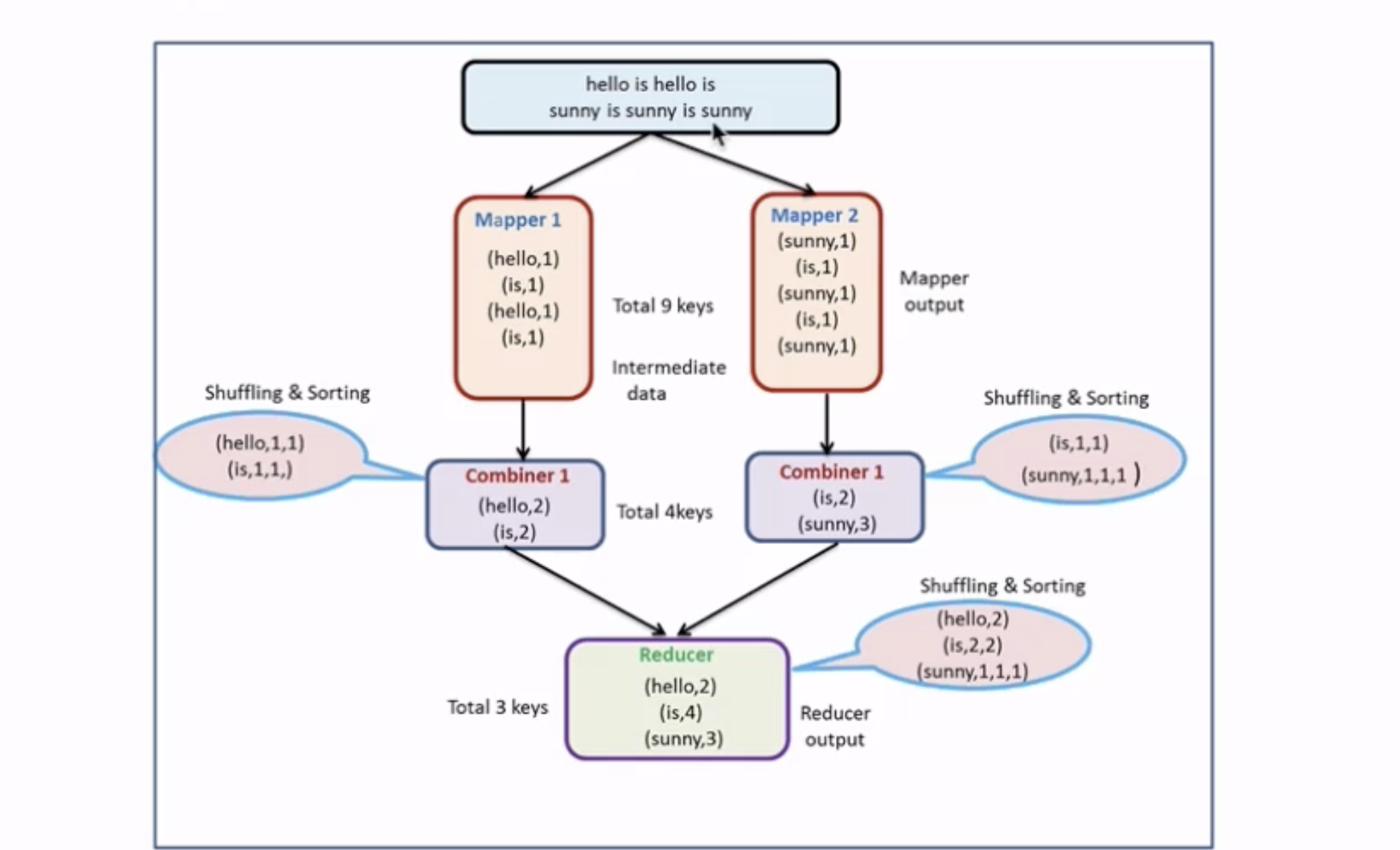
Combiner
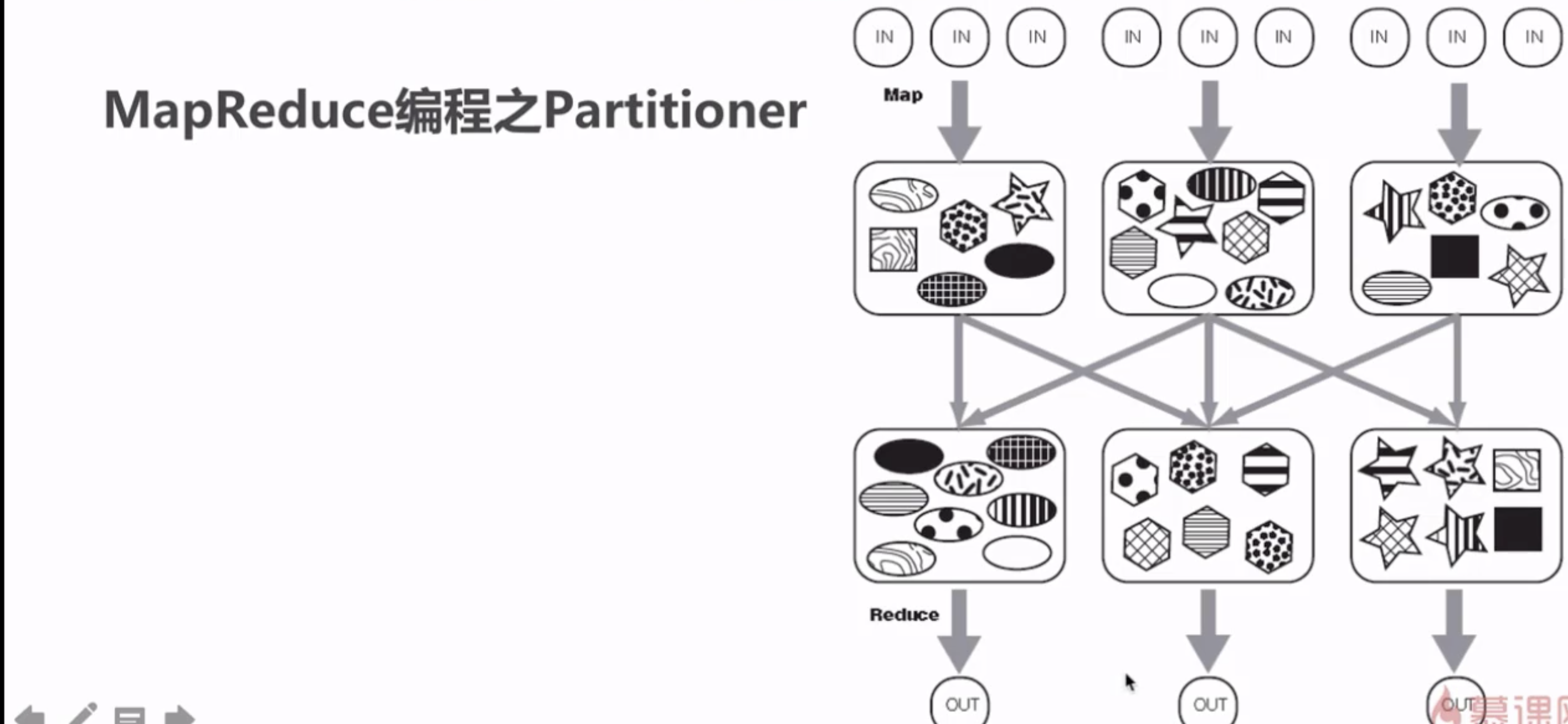
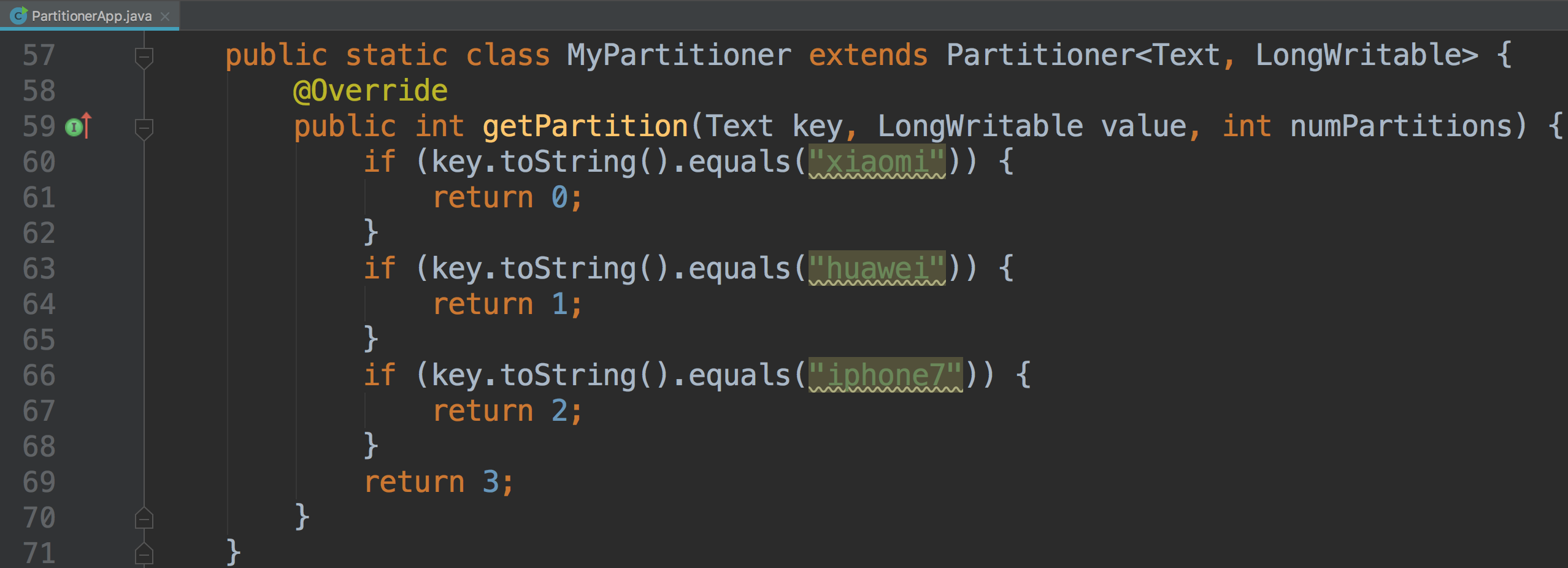
Partitioner

3.1 Split

3.2 InputFormat
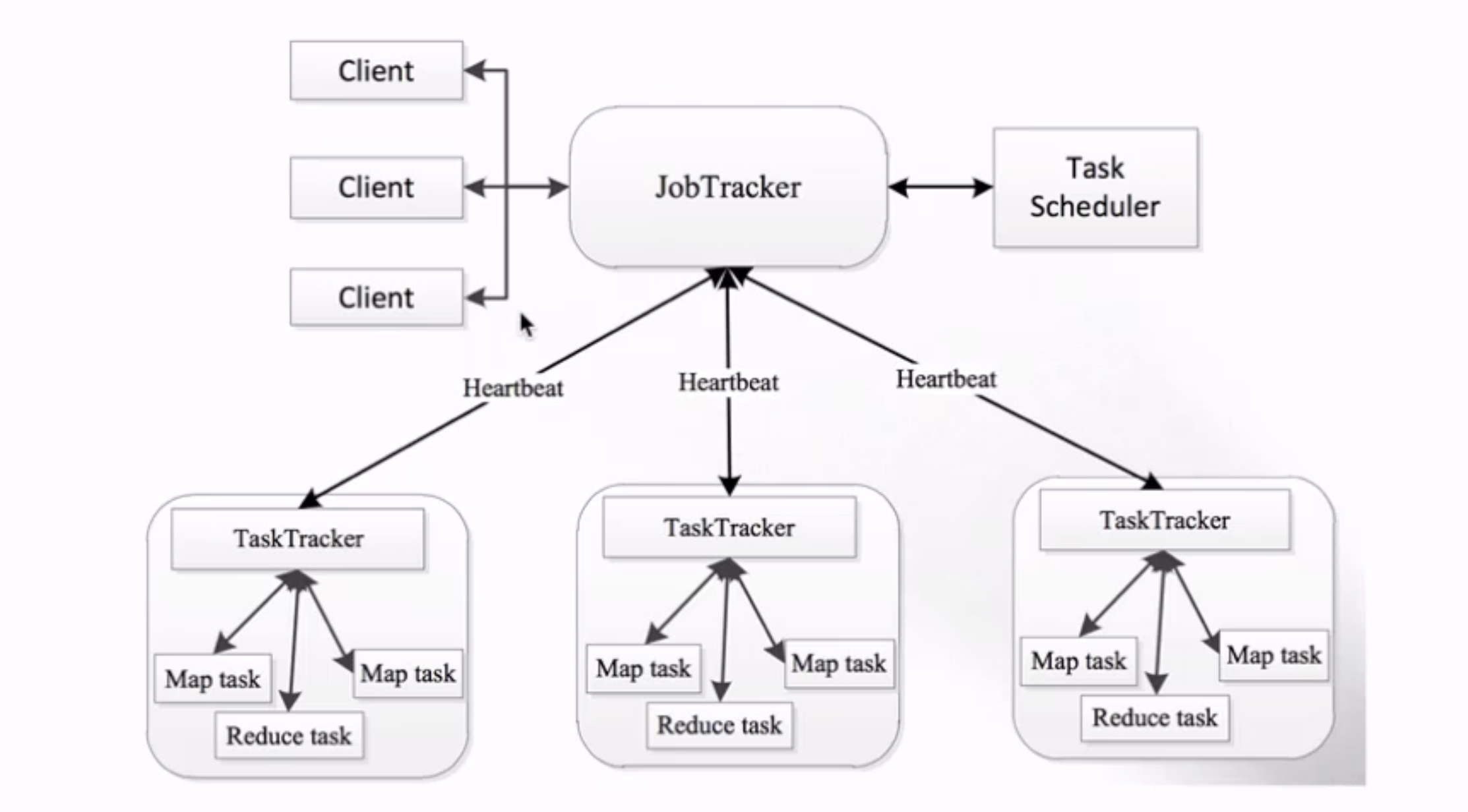
4 MapReduce 1.x 架构




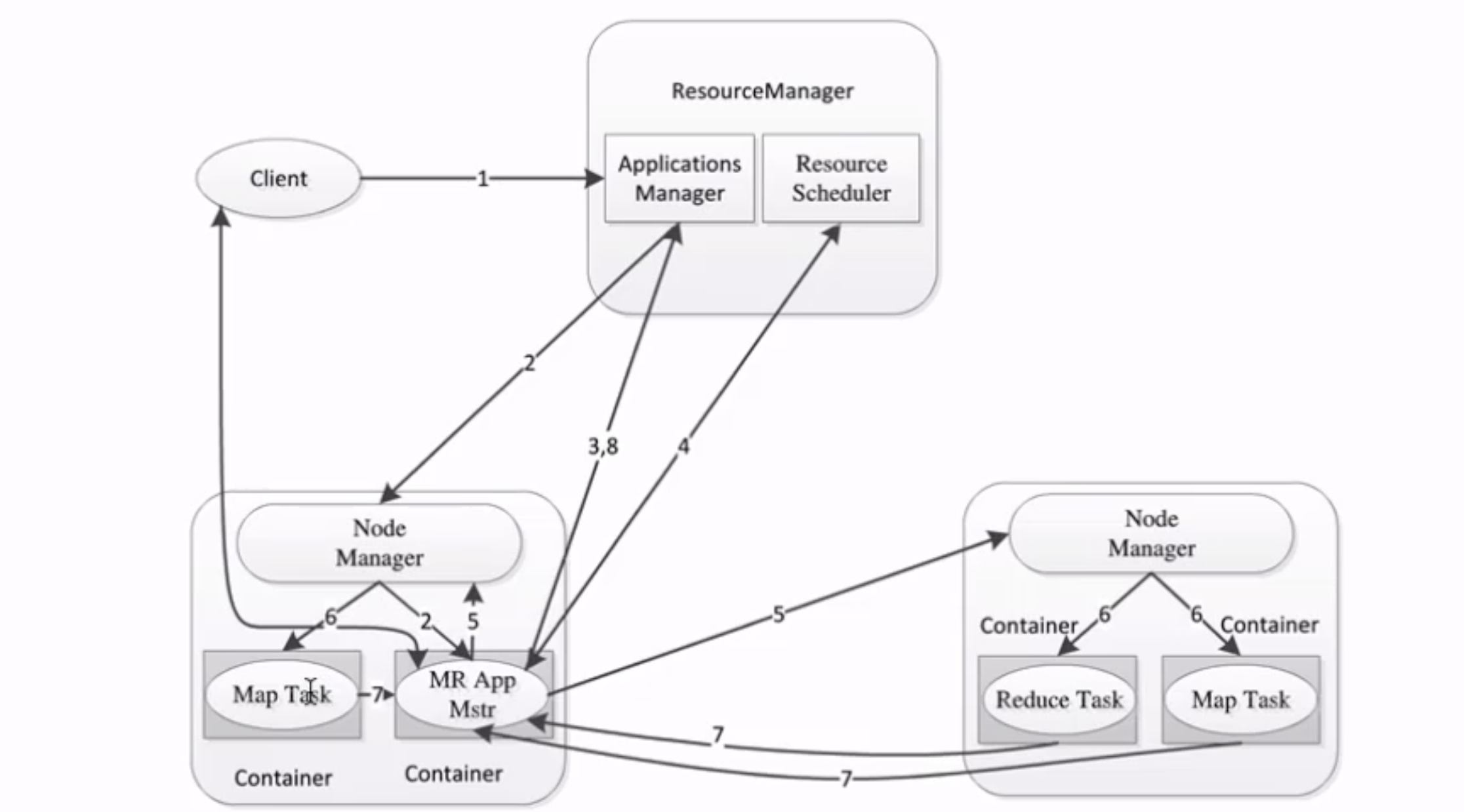
5 MapReduce 2.x 架构
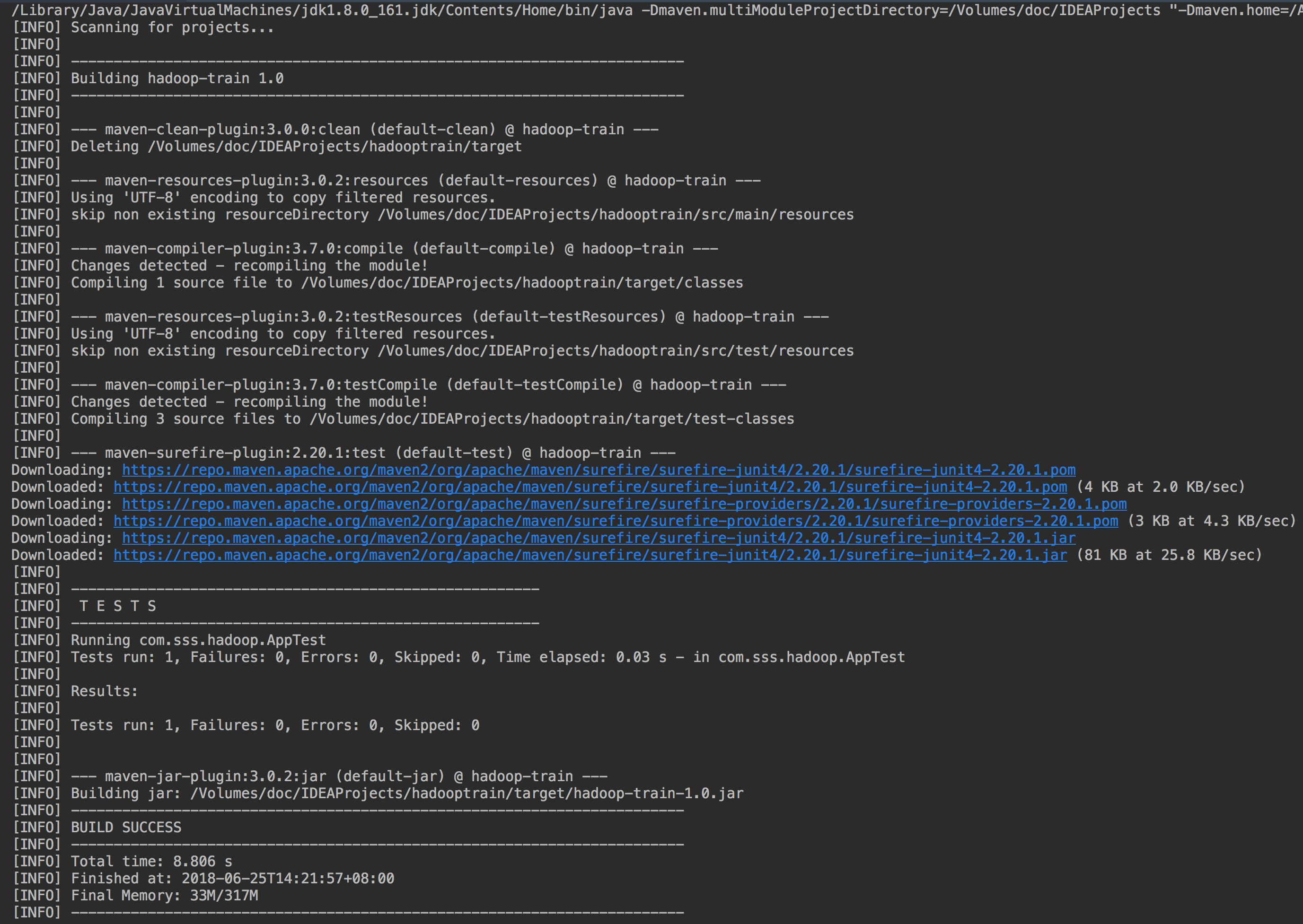
6 Java 实现 wordCount




7 重构
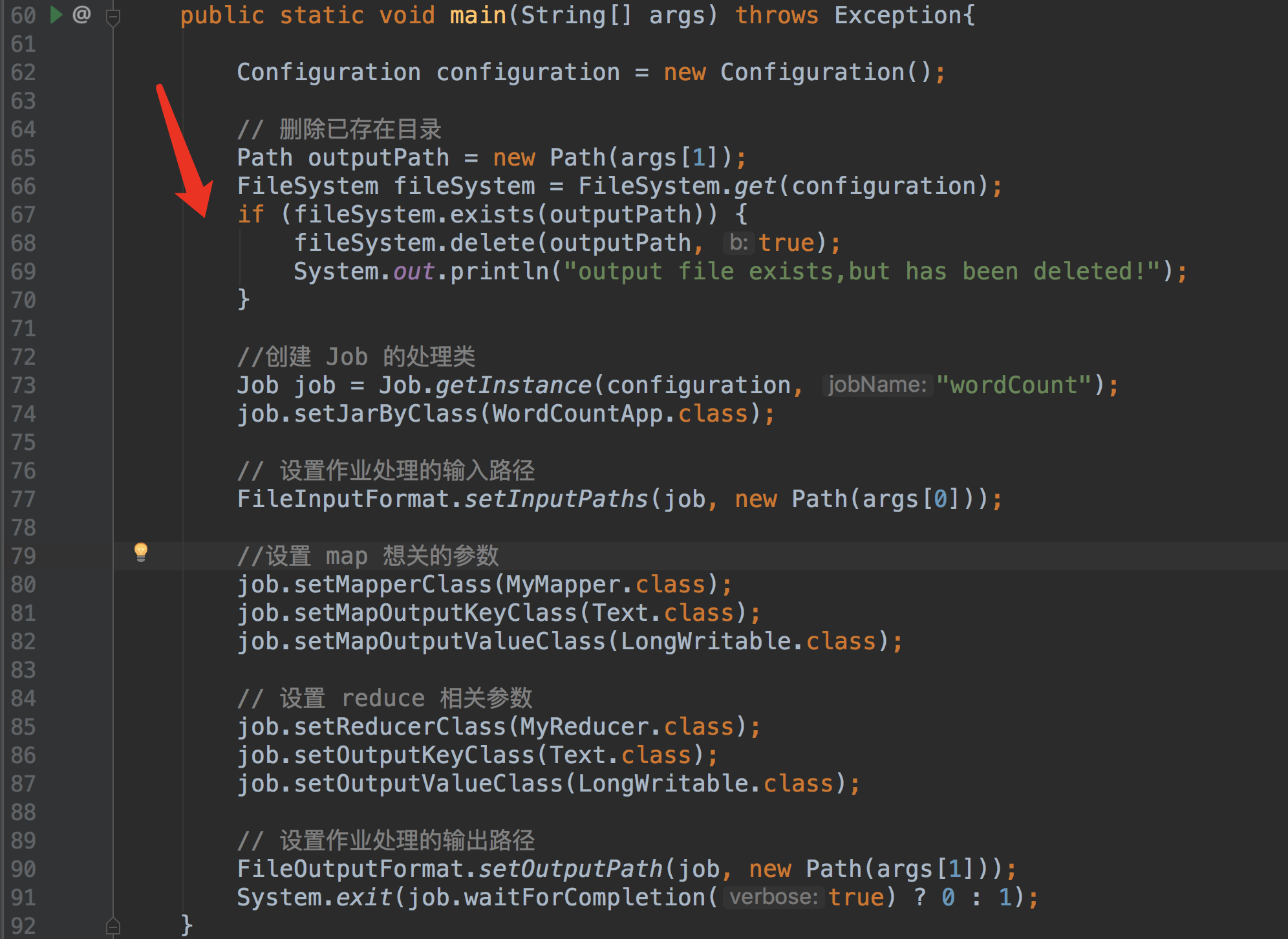
8 Combiner编程
9 Partitoner
文章来源: javaedge.blog.csdn.net,作者:JavaEdge.,版权归原作者所有,如需转载,请联系作者。
原文链接:javaedge.blog.csdn.net/article/details/121426613

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)