使用ABAP编程实现对微软Office Word文档的操作

SAP ABAP里提供了一个标准的类CL_DOCX_DOCUMENT,提供了本地以".docx"结尾的微软Office word文档的读和写操作。
本文介绍了ABAP类CL_DOCX_DOCUMENT的简单用法。

Office OpenXML
从微软 Office2007开始, 当我们新建一个word文档时,其扩展名从“.doc"变为了".docx",后者是基上遵循了一个开源的规范:Office openXML格式。
例如下图,我创建了一个最简单的word文档,包含了一个Header 区域,一个由三行彩色文字组成的段落,还有一张图片。
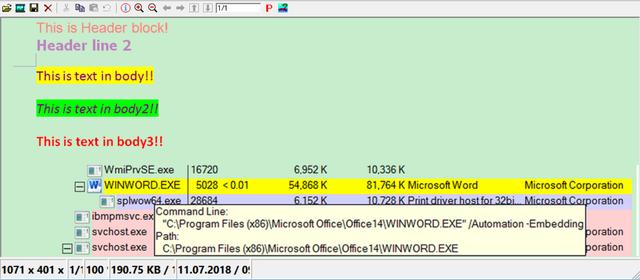
我们把这个文档保存到本地,将其扩展名从.docx改成.zip, 然后双击,就可以用解压软件比如winrar打开。
于是发现这一个最简单的word文档实际上由如此多的xml和文件夹构成。
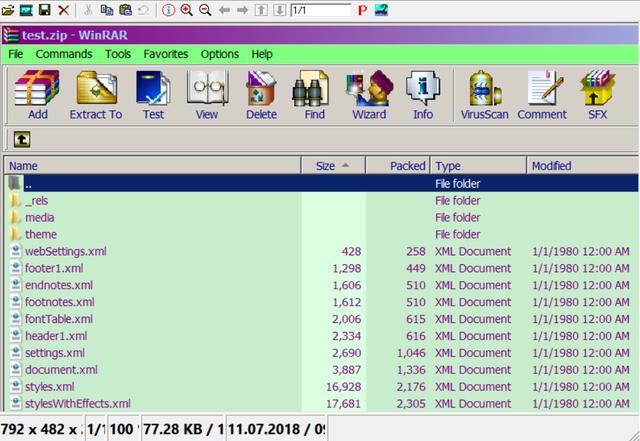
使用CL_DOCX_DOCUMENT读取word文件内容
示例代码如下:
DATA: lv_content TYPE xstring,
lo_document TYPE REF TO cl_docx_document.
PERFORM get_doc_binary USING 'C:Usersi042416Desktop est.docx' CHANGING lv_content.
lo_document = cl_docx_document=>load_document( lv_content ).
CHECK lo_document IS NOT INITIAL.
DATA(lo_core_part) = lo_document->get_corepropertiespart( ).
DATA(lv_core_data) = lo_core_part->get_data( ).
DATA(lo_main_part) = lo_document->get_maindocumentpart( ).
DATA(lo_image_parts) = lo_main_part->get_imageparts( ).
DATA(lv_image_count) = lo_image_parts->get_count( ).
DO lv_image_count TIMES.
DATA(lo_image_part) = lo_image_parts->get_part( sy-index - 1 ).
DATA(lv_image_data) = lo_image_part->get_data( ).
ENDDO.
DATA(lo_header_parts) = lo_main_part->get_headerparts( ).
DATA(lv_header_count) = lo_header_parts->get_count( ).
DO lv_header_count TIMES.
DATA(lo_header_part) = lo_header_parts->get_part( sy-index - 1 ).
DATA(lv_header_data) = lo_header_part->get_data( ).
ENDDO.
上述代码的简要说明
1. 将word文档的二进制内容传入方法cl_docx_document=>load_document,得到一个文档对象引用,然后就可以借助该对象引用调用各种方法了。
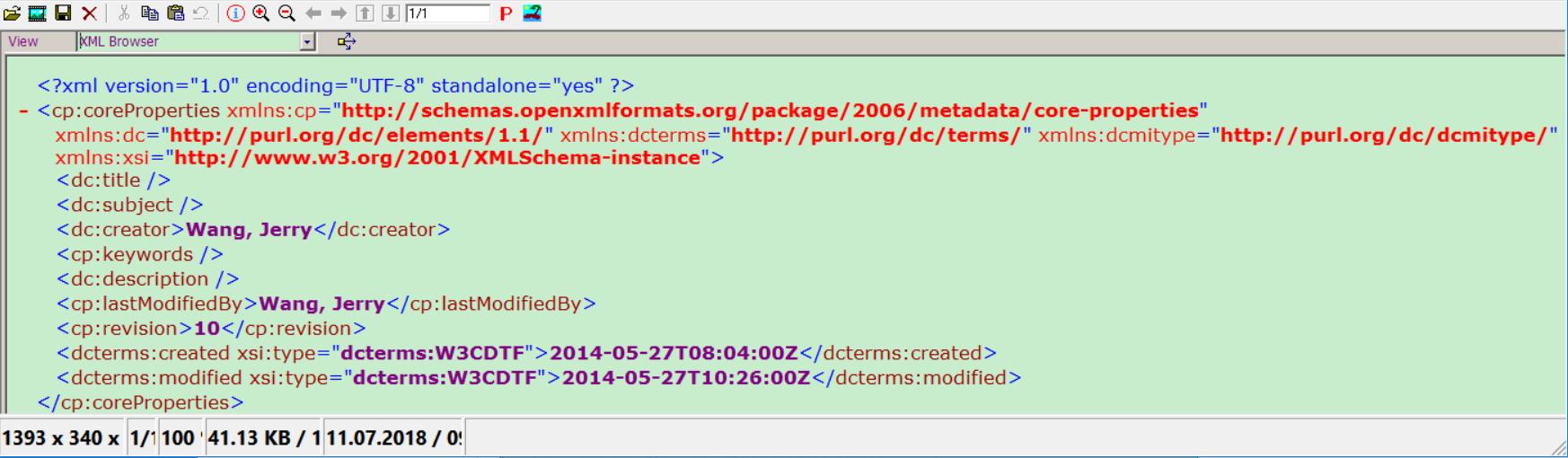
2. word文档的创建者,创建时间,最后修改时间等信息都存储在所谓的“Core property part”内,可以通过方法lo_document->get_corepropertiespart获得"Core property part"的引用,再使用该引用调用方法get_data获得实际内容。
下图是get_data返回的内容的一个例子,可以看出是xml格式。
3. 现在我们准备读取word文档的正文了。使用方法lo_document->get_maindocumentpart得到word文档正文,文字的字体类型,颜色也包含在内。如下图所示:
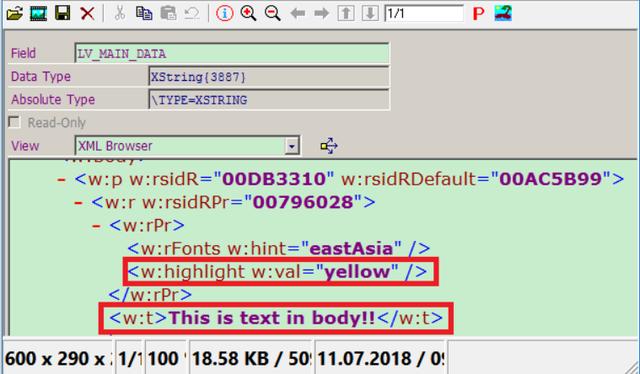
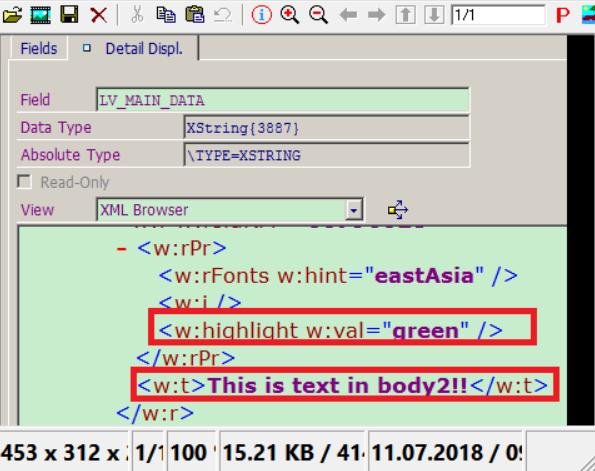
4. Word文档里插入的图片的二进制内容当然也是可以读取出来的。使用方法:lo_image_parts->get_part返回。
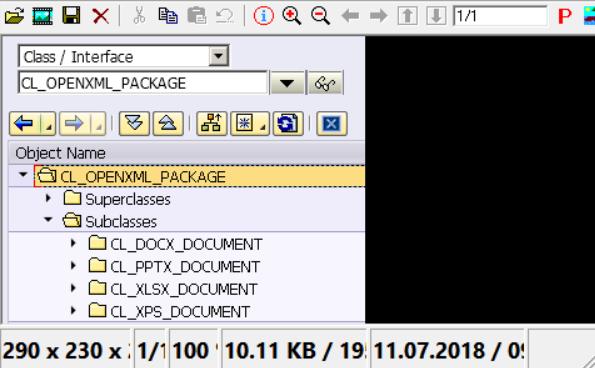
同样的思路,微软Office 2007之后版本的其他格式的办公文档,比如Powerpoint和Excel等,均遵循Office OpenXML标准,因此将其后缀名改为.zip后同样可以看到大量xml和文件夹。ABAP也同样提供了标准代码来读写这些Office文档,例如CL_PPTX_DOCUMENT, CL_XLSX_DOCUMENT等等,如下图所示。
要获取更多Jerry的原创技术文章,请关注公众号"汪子熙"。

- 点赞
- 收藏
- 关注作者
评论(0)