进一步了解XPath(利用XPath爬取飞哥的博客)【python爬虫入门进阶】(04)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
本文是爬虫专栏的第四篇,重点介绍lxml库与XPath搭配使用解析网页提取网页内容。
干货满满,建议收藏,系列文章持续更新。 小伙伴们如有问题及需要,欢迎踊跃留言告诉我哦~ ~ ~。
前言(为什么写这篇文章)
上一篇文章我们简单的介绍了Html与xml的基本概念,并且重点介绍了XPath的语法。这篇文章就让我们来实战一下: 通过本文你将学会如何 如何利用lxml库来加载和解析网页,然后搭配XPath的语法定位特定元素及节点信息的知识点。
@[toc]
lxml库的介绍
lxml库是一个HTML/XML的解析器,主要功能是如何解析和提取HTML/XML的数据。
lxml和正则一样,也是用C语言实现的,是一款高性能的Python HTML/XML解析器。利用前面学习的XPath的语法来快速定位网页上的特定元素以及节点信息。
利用pip安装lxm库
pip install lxml
利用lxml库解析HTML片段
lxml库可以解析传入的任何一段XML或者HTML片段,当然前提是你的XML或者HTML片段没有语法错误。
#lxml_test.py
from lxml import etree
text = """
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全网ID名:<b>码农飞哥</b></strong></p>
<p style="text-align:right;"><strong>扫码加入技术交流群!</strong></span></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;">个人微信号<img src="https://img-blog.csdnimg.cn/09bddad423ad4bbb89200078c1892b1e.png"/></div>
</div>
"""
# 利用etree.HTML将字符串解析成HTML文档
html = etree.HTML(text)
print("调用etree.HTML=", html)
# 将Element对象序列化成字符串
result = etree.tostring(html)
print("将Element对象序列化成字符串=", result)
result2 = etree.tostring(html, encoding='utf-8').decode()
print(result2)

从上面的输出结果可以看出etree.HTML(text) 方法可以将字符串解析成HTML文档,也就是一个Element对象。etree.tostring(html) 可以将HTML文档序列化成字符串,序列化之后的结果是一个 bytes 对象,中文是不能正常显示的。需要通过指定编码方式为utf-8,并且调用decode()方法中文才能正常输出,并且输出的HTML是有格式的。即不是打印成一行。
利用lxml库加载html文件
lxml库不仅仅可以解析XML/HTML片段,还可以解析完整的HTML/XML文件 。下面创建了一个名为test.html文件。然后通过 etree.parse方法进行解析。
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全网ID名:<b>码农飞哥</b></strong></p>
<p style="text-align:right;"><strong>扫码加入技术交流群!</strong></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;">个人微信号<img src="https://img-blog.csdnimg.cn/09bddad423ad4bbb89200078c1892b1e.png"/></div>
</div>
然后创建一个html_parse.py的文件进行解析,需要注意的是该文件跟test.html文件在同一个目录下。
# html_parse.py
from lxml import etree
#读取外部文件 test.html
html = etree.parse('./test.html')
result = etree.tostring(html, encoding='utf-8').decode()
print(result)
解析结果是:

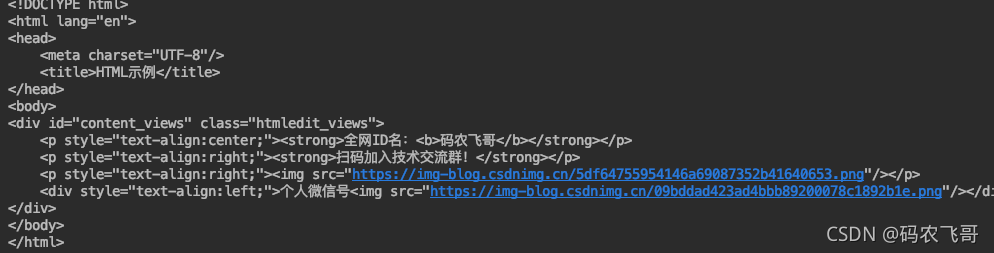
可以看出如果被解析的HTML文件是一个标准的HTML代码片段的话则可以正常加载,因为这里parse方法默认使用的是XML的解析器。
但是当HTML文件是一个标准的完整的HTML文件则XML解析器是不能解析。现在将test.html 改下图2的代码,如果直接使用XML解析器解析就会报下面的错误。
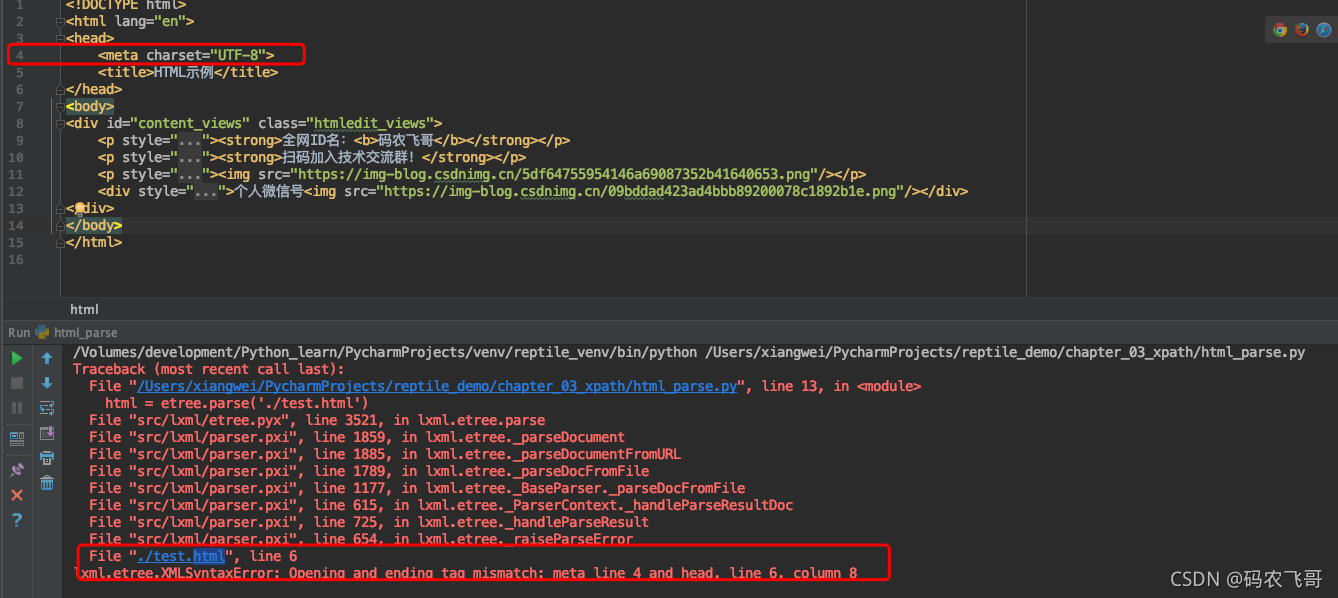
针对HTML文件需要通过HTMLParser方法设置HTML解析器。然后在parse方法指定该解析器,就像下面代码所示的一样。
from lxml import etree
# 定义解析器
html_parser = etree.HTMLParser(encoding='utf-8')
# 读取外部文件 test.html
html = etree.parse('./test.html', parser=html_parser)
result = etree.tostring(html, encoding='utf-8').decode()
print(result)
运行结果是:
实战开始
了解了lxml方法的基本使用之后,接下来我们就以码农飞哥的博客 为例。这里我们的需求是爬取他博客下所有文章(暂不包括文章内容),然后将爬取的数据保存到本地txt文件中。首先让我们来看看他的博客长啥样。涉及前面几篇博客知识点这里不再详细介绍了。这里重点介绍如何通过XPath来快速定位特定的元素和数据。

第一步: 获得文章的分组
首先获取文章的分组,还是使用万能的XPath Helper, 通过F12调出调试窗口,可以看出每个文章分组都是放在<div class="article-item-box csdn-tracking-statistics xh-highlight"></div> 。所以,通过 //div[@class="article-item-box csdn-tracking-statistics"] 表达式就可以获取所有的文章分组。
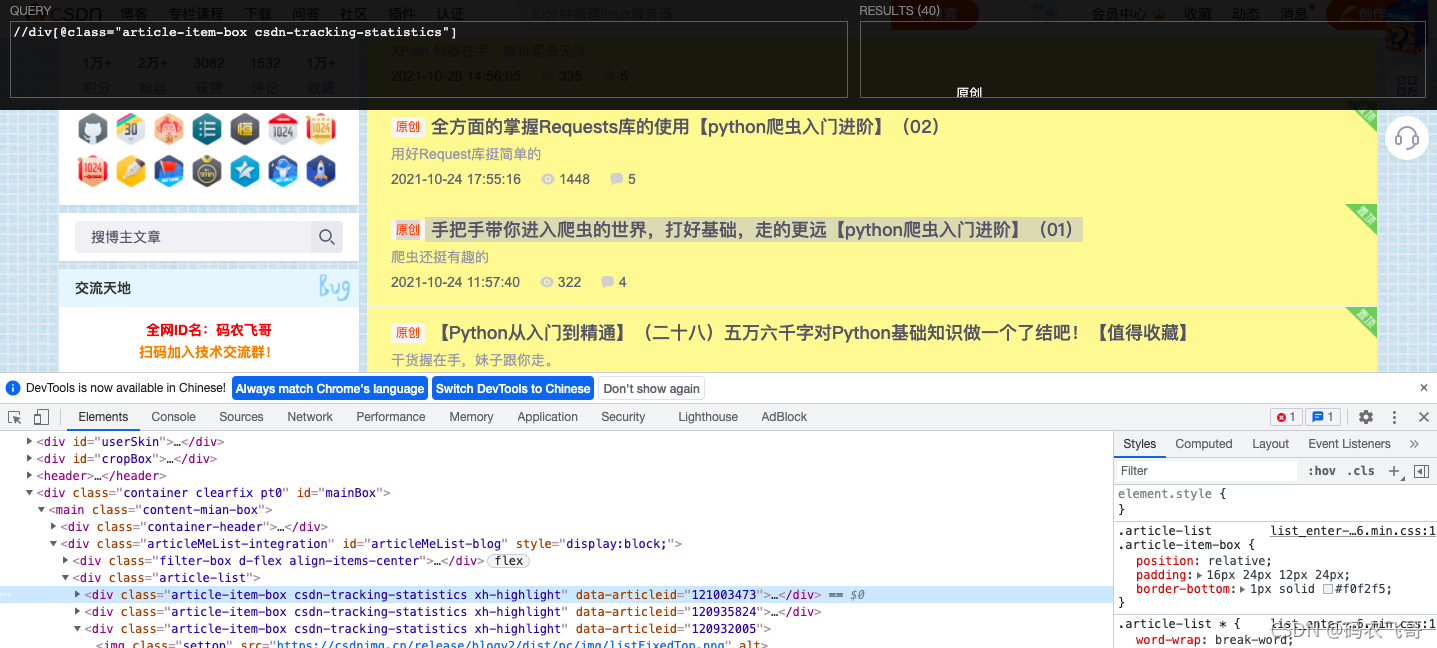
代码示例如下:
from lxml import etree
import requests
response = requests.get("https://feige.blog.csdn.net/", timeout=10) # 发送请求
html = response.content.decode()
html = etree.HTML(html) # 获取文章分组
li_temp_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
print(li_temp_list)
运行结果是:

这里通过html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]') 方法得到40个Element对象。这40个Element对象就是我们需要爬取的当前页面的所有文章。 每个Element对象就是下面这样的内容。

接下来通过result = etree.tostring(li_temp_list[0], encoding='utf-8').decode() 方法序列化Element对象,得到的结果是:
<div class="article-item-box csdn-tracking-statistics" data-articleid="121003473">
<img class="settop" src="https://csdnimg.cn/release/blogv2/dist/pc/img/listFixedTop.png" alt=""/>
<h4 class="">
<a href="https://feige.blog.csdn.net/article/details/121003473" data-report-click="{"spm":"1001.2014.3001.5190"}" target="_blank">
<span class="article-type type-1 float-none">原创</span>
浅识XPath(熟练掌握XPath的语法)【python爬虫入门进阶】(03)
</a>
</h4>
<p class="content">
XPath 利器在手,解析爬虫无忧
</p>
<div class="info-box d-flex align-content-center">
<p>
<span class="date">2021-10-28 14:56:05</span>
<span class="read-num"><img src="https://csdnimg.cn/release/blogv2/dist/pc/img/readCountWhite.png" alt=""/>335</span>
<span class="read-num"><img src="https://csdnimg.cn/release/blogv2/dist/pc/img/commentCountWhite.png" alt=""/>5</span>
</p>
</div>
</div>
第二步: 获取文章的链接
从上面的代码我们可以看出文章的链接在<a href="https://feige.blog.csdn.net/article/details/121003473"> 中,而a元素的父元素是h4元素,h4元素的父元素是 <div class="article-item-box csdn-tracking-statistics">元素。
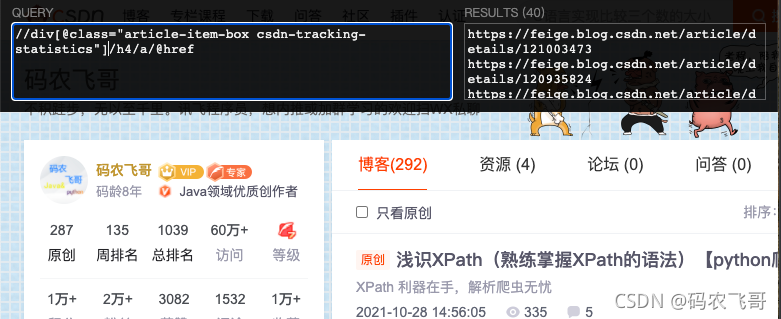
换成XPath的表达式就是//div[@class="article-item-box csdn-tracking-statistics"]/h4/a/@href ,即首先通过//div[@class="article-item-box csdn-tracking-statistics"] 选取所有的<div class="article-item-box csdn-tracking-statistics"> 然后通过/h4找到他的子元素h4,在通过/a找到h4的子元素a。最后就是通过/@href 找到链接内容。
不过第一步我们已经获取到了<div class="article-item-box csdn-tracking-statistics"> 元素的Element对象。所以,这里就不需要在重复写//div[@class="article-item-box csdn-tracking-statistics"]了,只需要通过. 代替,表示在当前目录下找。参考代码如下:
#省略第一步的代码
href = li_temp_list[0].xpath('./h4/a/@href')[0]
print(href)
得到的结果是:https://feige.blog.csdn.net/article/details/121003473 。需要注意的是.xpath方法返回的是一个列表,所以需要提取其第一个元素
第三步:获取标题内容
按照获取链接的思想,我们同样可以获取标题内容。标题的内容就直接在a标签里。这里只需要多一步就是通过text()方法提取a标签的内容。表达式就是//div[@class="article-item-box csdn-tracking-statistics"]/h4/a/text()。
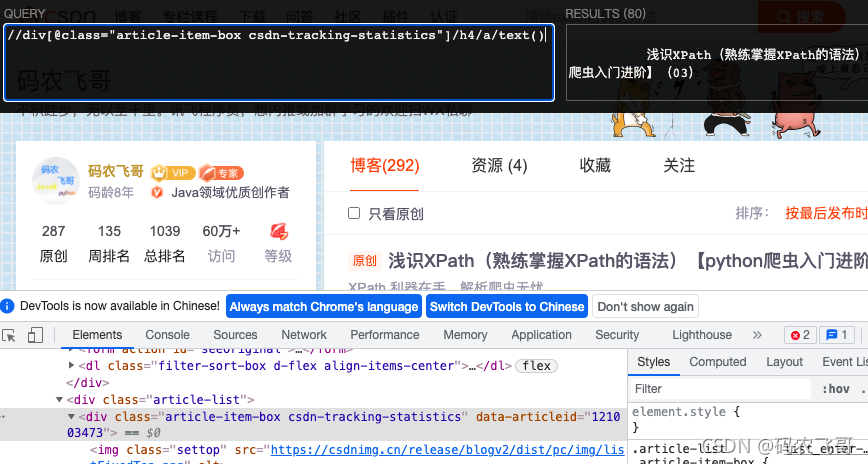
参考代码是:
title_list = li_temp_list[0].xpath('./h4/a/text()')
print(title_list)
print(title_list[1])
运行结果是:
['\n ', '\n 浅识XPath(熟练掌握XPath的语法)【python爬虫入门进阶】(03)\n ']
浅识XPath(熟练掌握XPath的语法)【python爬虫入门进阶】(03)
因为列表中的第一个元素是\n,所以需要获取第二个元素。
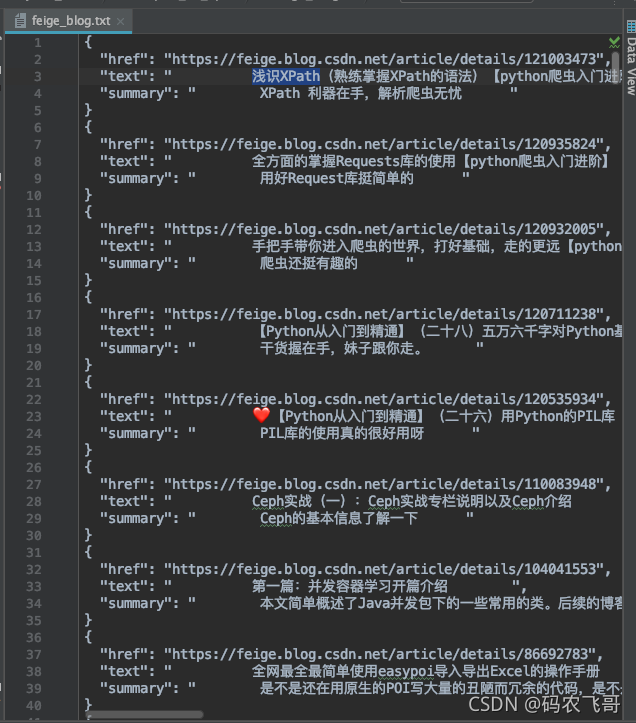
完整的参考代码
import requests
from lxml import etree
import json
import os
class FeiGe:
# 初始化
def __init__(self, url, pages):
self.url = url
self.pages = pages
self.headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36"}
def get_total_url_list(self):
"""
获取所有的urllist
:return:
"""
url_list = []
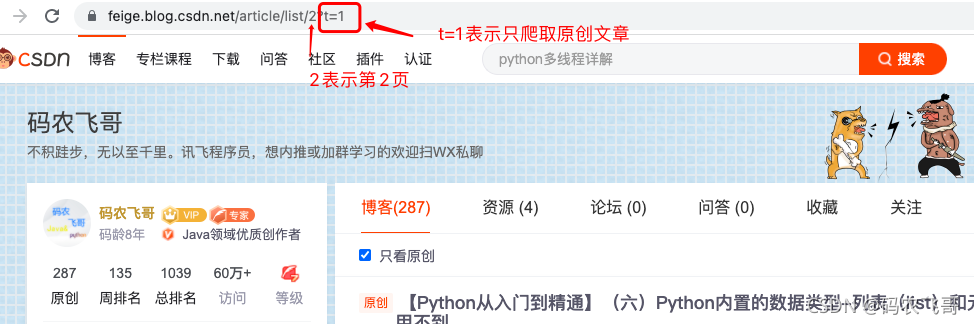
for i in range(self.pages):
url_list.append(self.url + "/article/list/" + str(i + 1) + "?t=1")
return url_list
def parse_url(self, url):
"""
一个发送请求,获取响应,同时etree处理html
:param url:
:return:
"""
print('parsing url:', url)
response = requests.get(url, headers=self.headers, timeout=10) # 发送请求
html = response.content.decode()
html = etree.HTML(html)
return html
def get_title_href(self, url):
"""
获取一个页面的title和href
:param url:
:return:
"""
html = self.parse_url(url)
# 获取文章分组
li_temp_list = html.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
total_items = []
# 遍历分组
for i in li_temp_list:
href = i.xpath('./h4/a/@href')[0] if len(i.xpath('./h4/a/@href')) > 0 else None
title = i.xpath('./h4/a/text()')[1] if len(i.xpath('./h4/a/text()')) > 0 else None
summary = i.xpath('./p')[0] if len(i.xpath('./p')) > 0 else None
# 放入字典
item = dict(href=href, text=title.replace('\n', ''), summary=summary.text.replace('\n', ''))
total_items.append(item)
return total_items
def save_item(self, item):
"""
保存一个item
:param item:
:return:
"""
with open('feige_blog.txt', 'a') as f:
f.write(json.dumps(item, ensure_ascii=False, indent=2))
f.write("\n")
def run(self):
# 找到url规律,url_list
url_list = self.get_total_url_list()
os.remove('feige_blog.txt')
for url in url_list:
# 遍历url_list发送请求,获得响应
total_item = self.get_title_href(url)
for item in total_item:
print(item)
self.save_item(item)
if __name__ == '__main__':
fei_ge = FeiGe("https://feige.blog.csdn.net/", 8)
fei_ge.run()
运行结果是:
该类主要分为几大块。
- 初始化方法
__init__(self, url, pages)主要设置需要爬取的博客的域名,以及博客的页数,以及初始化请求头。 - 获取所有页数的链接的方法
get_total_url_list(self),这里需要注意的链接的规律。

parse_url(self, url)方法主要就是根据传入的url获得该url的html页面。get_title_href(self, url)方法主要分为两块,第一块就是调用parse_url(self, url) 方法得到链接对应的html页面。第二块就是解析HTML页面以定位到我们需要的数据的元素,并将元素放在列表total_items中返回。save_item(self, item)方法就是将第四步返回的total_items中的数据保存到feige_blog.txt文件中。run(self)方法是主入口,统筹调用各个方法。
总结
本文通过码农飞哥演示了如何在实战中使用XPath来爬取我们想要的数据。

- 点赞
- 收藏
- 关注作者
评论(0)