一种企业级应用软件 UI 搜索分页技术的实现

搜索分页技术往往和另一个术语Lazy Loading(懒加载)联系起来。今天由Jerry首先介绍S/4HANA,CRM Fiori和S4CRM应用里的UI搜索分页的实现原理。后半部分由SAP成都研究院菜园子小哥王聪向您介绍Twitter的懒加载实现。
关于王聪的背景介绍,您可以参考他的前一篇文章:SAP成都研究院非典型程序猿,菜园子小哥:当我用UI5诊断工具时我用些什么。
S/4HANA Fiori应用搜索分页实现原理
以S/4HANA Product Master Fiori应用为例,如果什么搜索条件都不指定,默认会返回25条数据,并且在UI上显示该系统总的product数量,在Jerry使用的系统里总共存在140个product。
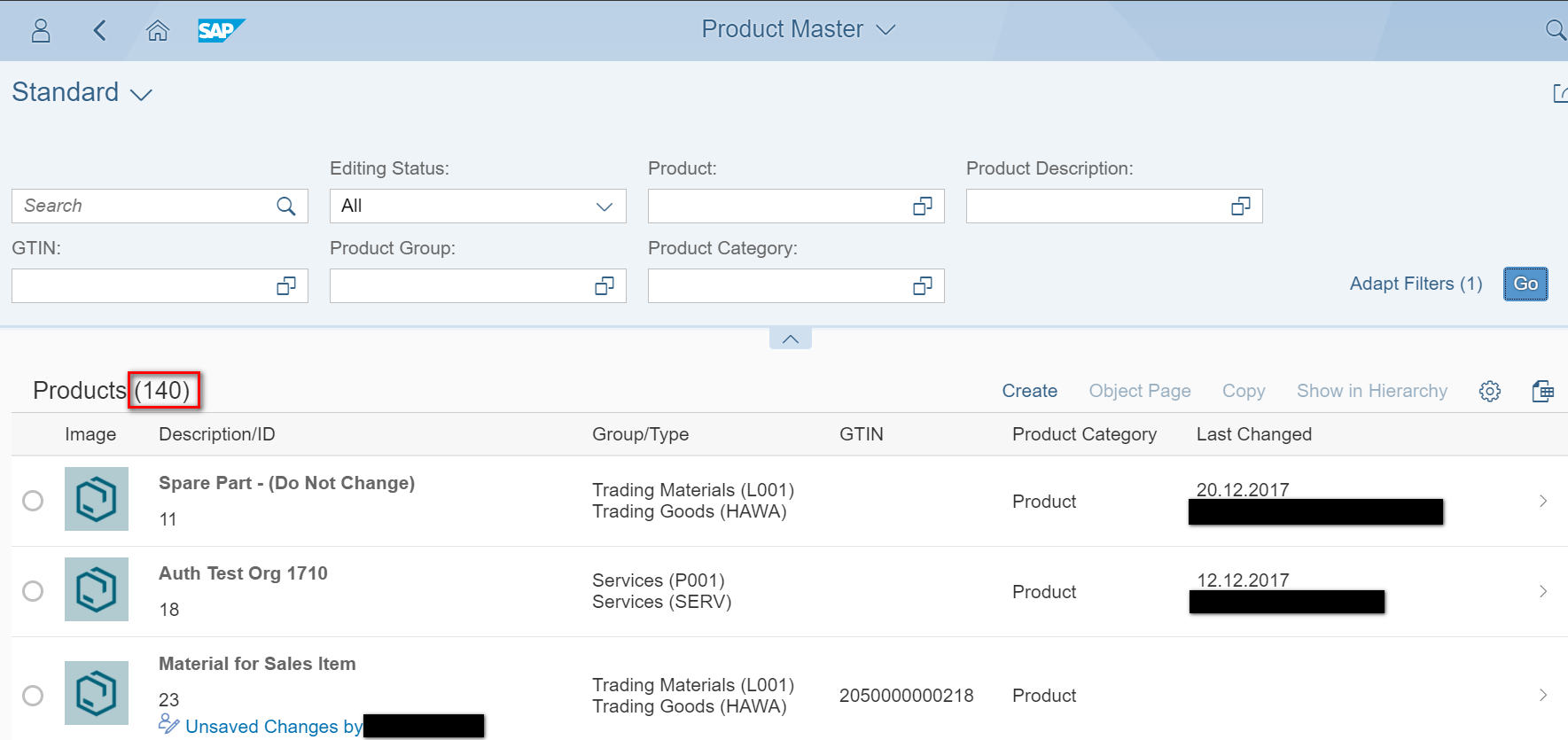
该搜索分页的实现归功于OData请求的参数,skip=0&top=25,意为从请求命中的第0条记录开始, 总共返回25条记录。而另一个参数inlinecount,其工作原理可以类比ABAP Open SQL的关键字SELECT COUNT(*),用于统计数据库表的条目数。
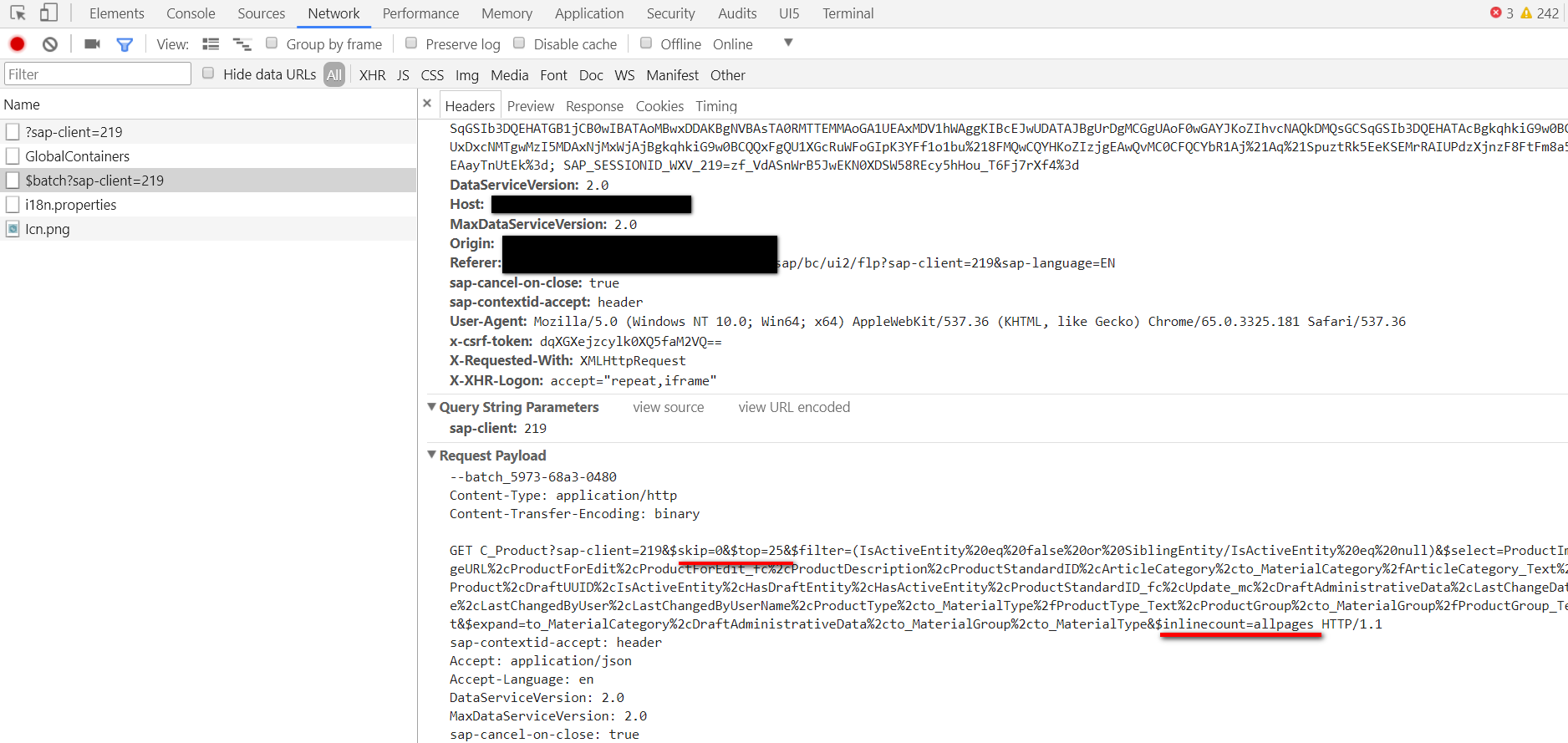
一旦用鼠标滚轮向下移动页面至屏幕底部,会自动触发一个新的OData请求,参数为$skip=25&top=25。 这样,从第26到第50个product也从数据库表中读取出来显示在Fiori UI上。
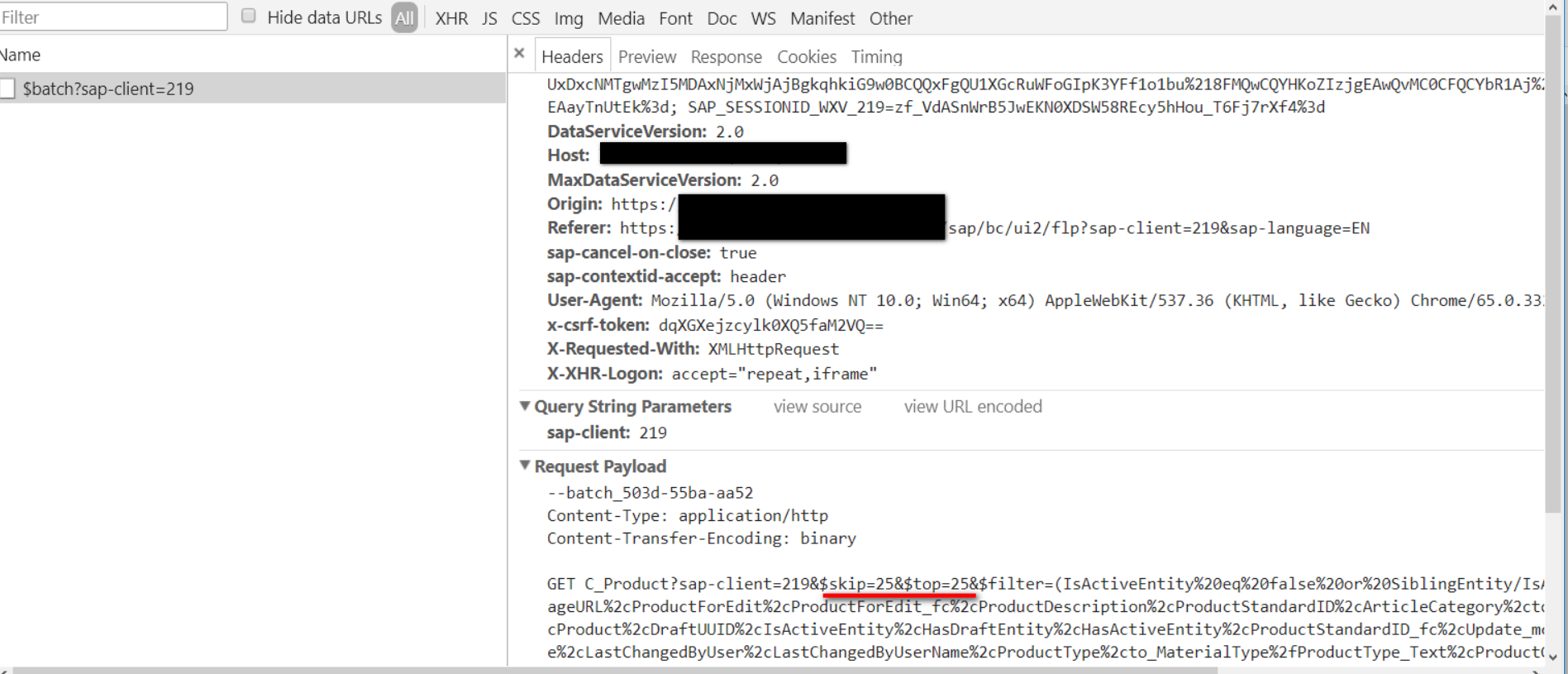
为什么分页的尺寸为25?在Fiori UI列表实现文件sap.m.ListBase.js里,默认的分页尺寸(GrowingThreshold)为20,这说明一定存在某个配置,或者在Product Master应用某处的JavaScript代码将这个分页尺寸从20改成了25。

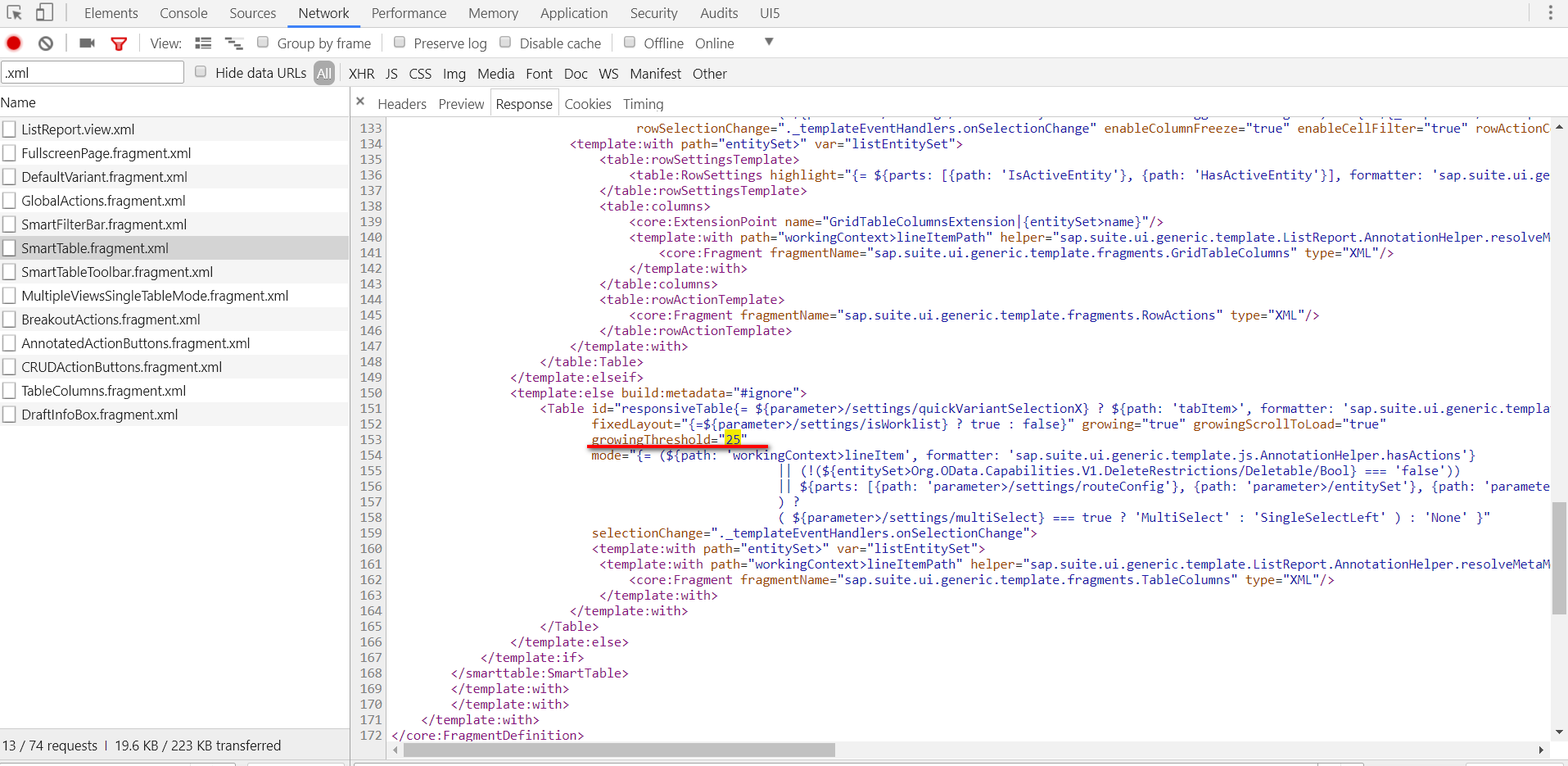
由于篇幅限制,Jerry直接揭晓答案了。S/4HANA里的Fiori应用都是使用Smart Template技术实现的,其列表区域的实现位于SmartTable.fragment.xml这个模板文件里,growingThreshold指定为25。因为从时间序列上来说SmartTable.fragment.xml后于sap.m.ListBase.js加载,所以对于分页尺寸的定义其优先级更高。
如果您想通过自己调试找到这个答案,锻炼自己的分析能力,可以参考我的调试过程:
How does UI5 AutoGrowing list(Lazy Load behavior) work
以及使用Smart Template开发Fiori应用的介绍:
Jerry的通过CDS view + Smart Template 开发Fiori应用的blog合集
再来看看搜索分页的后台处理。在Netweaver事务码ST05的数据库跟踪视图里,能清晰观察到这个分页效果:每次到数据库的查询只命中并返回25条记录,如下图三条高亮的跟踪记录所示。

从前台通过UI5库文件发送的带有 top参数的OData请求,被后台接收并维护于io_query_options参数中:
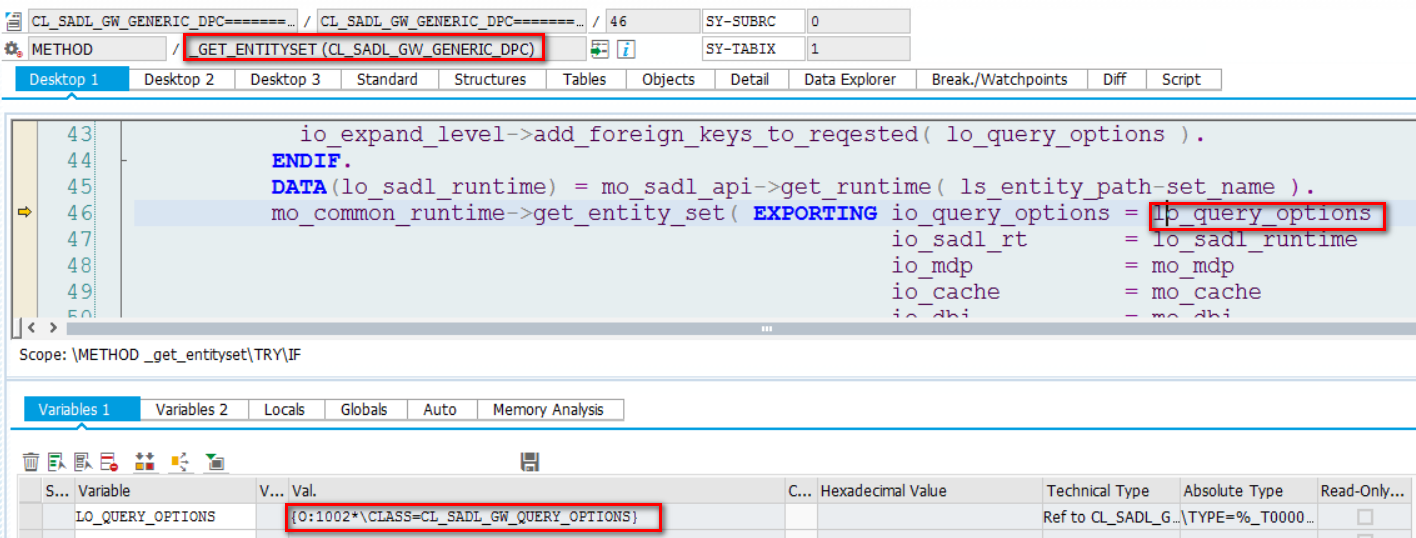
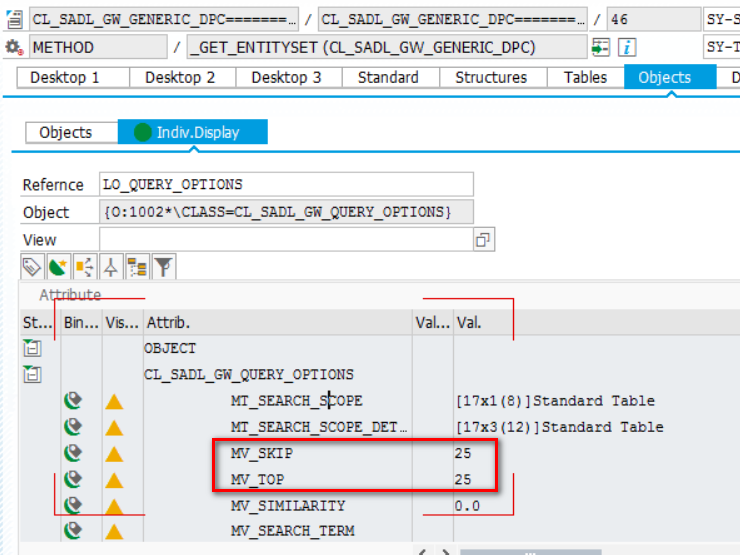
而最终在数据库查询层面的分页处理,是由ABAP Open SQL的关键字OFFSET实现的。
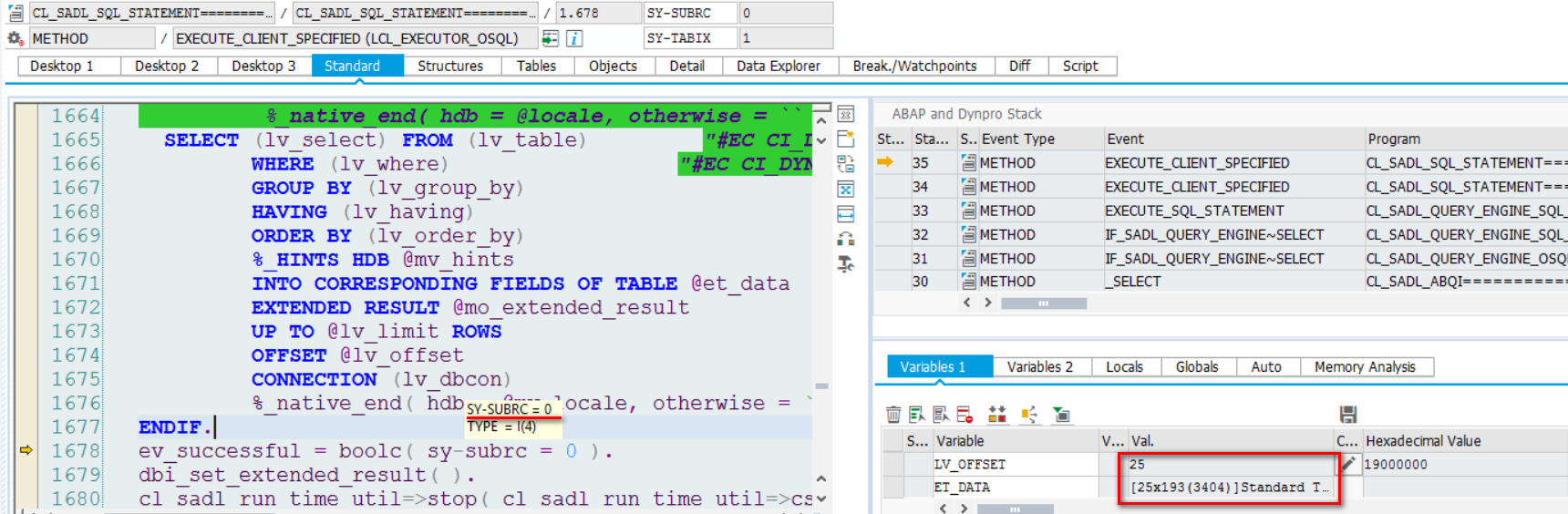
上图第1674行@lv_offset的值,是基于UI传入的 top计算而得。
CRM Fiori应用搜索分页实现原理
CRM Fiori应用的前台搜索分页实现原理和S/4HANA Fiori应用类似,只是分页尺寸变成了20。
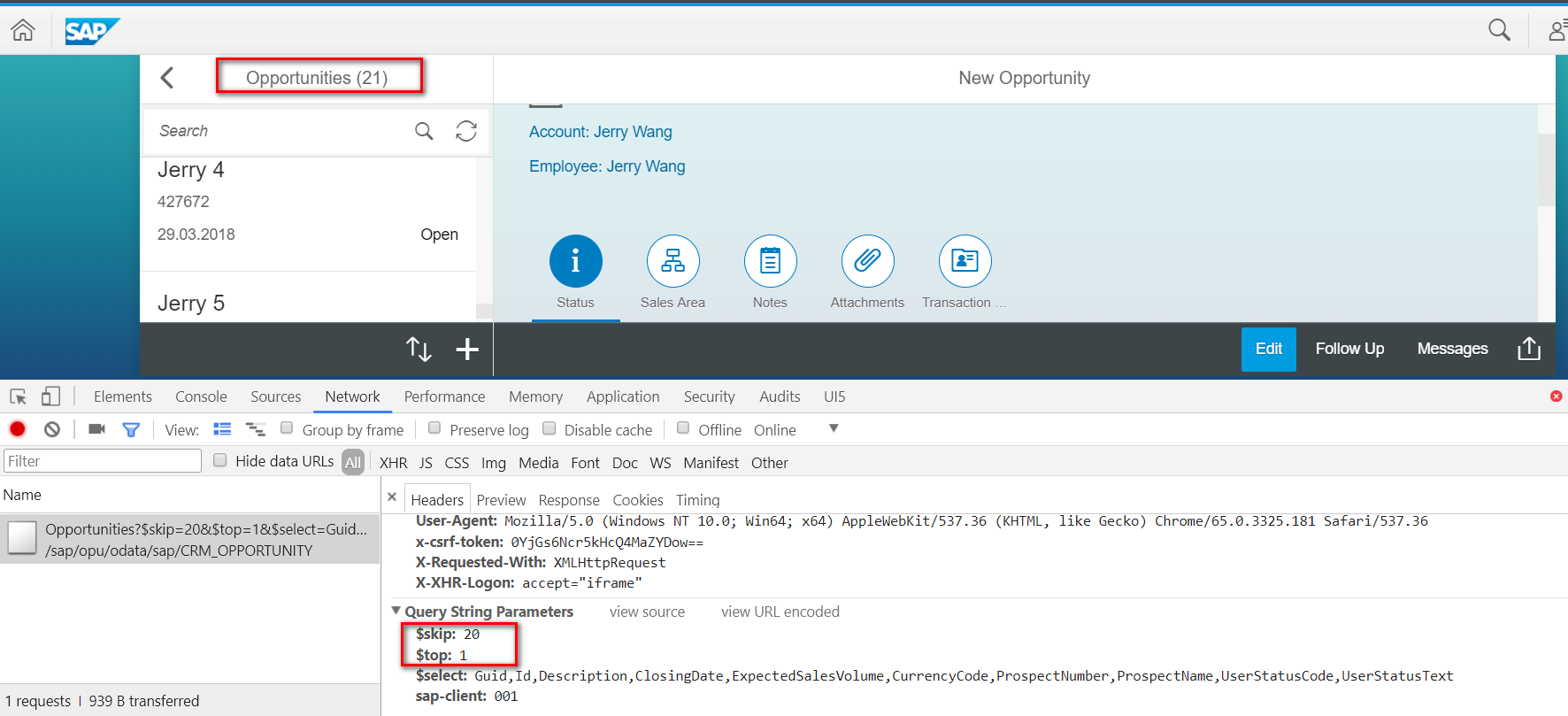
上图的 top参数同S/4HANA应用的行为相同,传递到后台并得到处理:


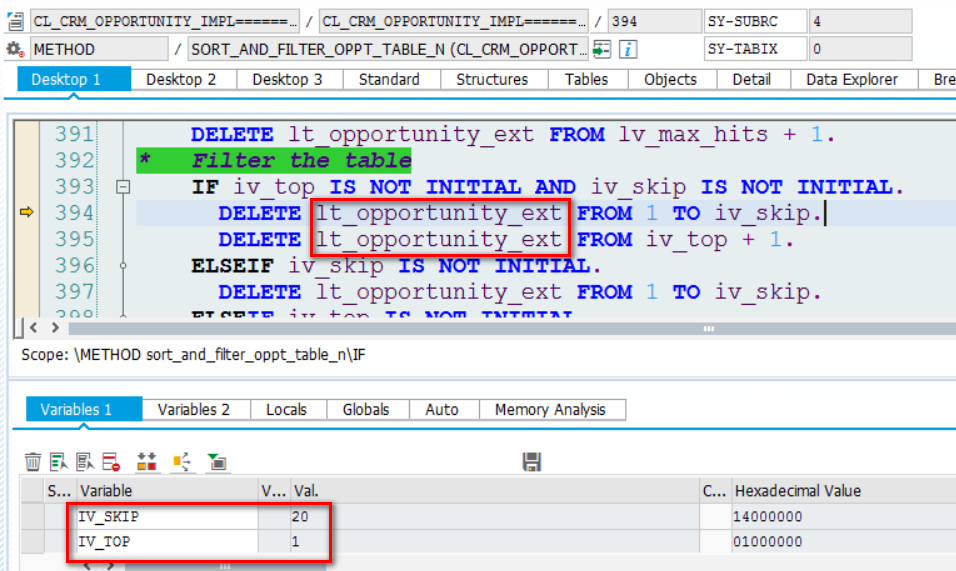
CRM Fiori后台的搜索分页处理和S/4HANA Fiori的区别:并未使用ABAP的OFFSET关键字,而由应用开发人员自行实现。
(1) 首先将所有满足搜索条件的记录的GUID全部从数据库取出,从数据库层返回到ABAP层。在我这个测试系统里,总共有21条记录,全部返回到了ABAP层:
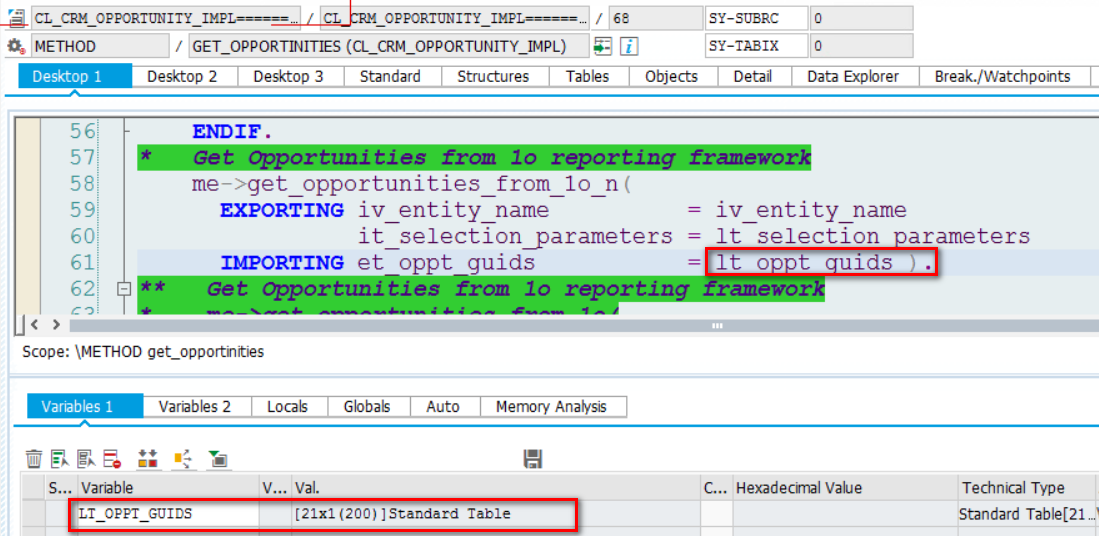
(2) 由应用开发人员根据 top值,将多余的记录丢弃掉,保证最后只返回20条记录给UI。
至此S/4HANA和CRM Fiori应用的搜索分页原理介绍完毕。更多细节,请参考我的博客:
Search Paging implementation in S/4HANA and CRM Fiori application
S4CRM应用的搜索分页实现原理
S4CRM,全称为S/4HANA for Customer Management,UI开发技术仍然采用WebClient UI。和S/4HANA基于UI5的前端技术截然不同,WebClient UI走的是服务器端渲染的BSP路线。严格意义上讲,WebClient UI不存在数据库层面的搜索分页,其分页行为仅仅体现在服务器端渲染上。
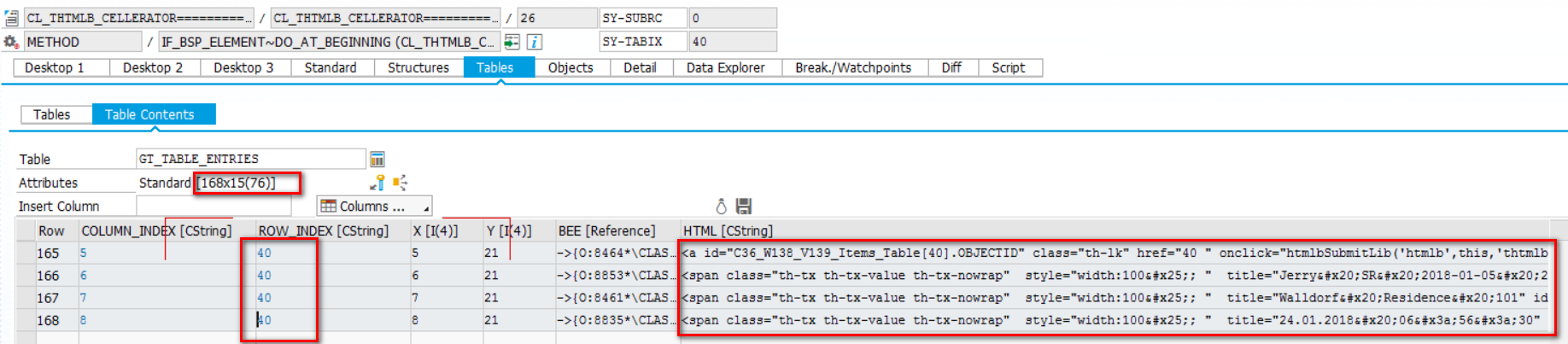
下图例子里,我指定Max Number of Results为200,意思是期望满足搜索条件的记录里,显示200条到UI上。

从搜索结果能看出分页效果。全部200条记录已经从数据库查询出来并保存到应用程序的内存里。如下图所示:
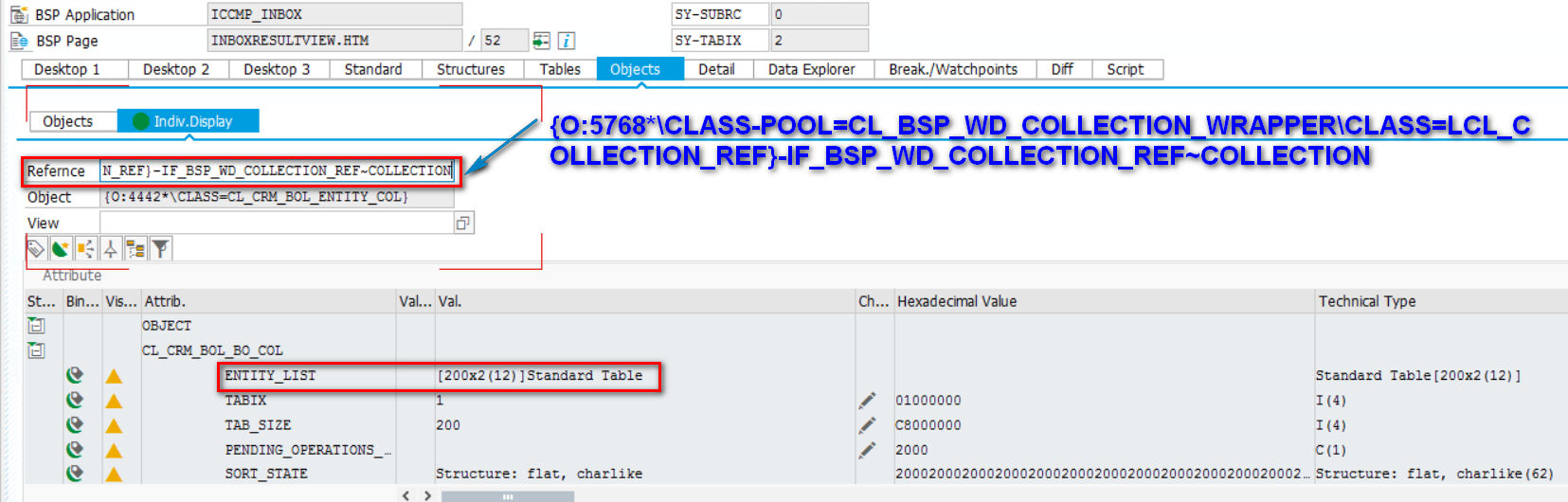
WebClient UI仅仅将第一页的HTML源代码在ABAP后台渲染出来然后显示给用户。当用户点了屏幕下方的“2”页码时,不会有任何的数据库查询发生,服务器做的事情仅仅是将第二页对应的HTML源代码渲染出来。
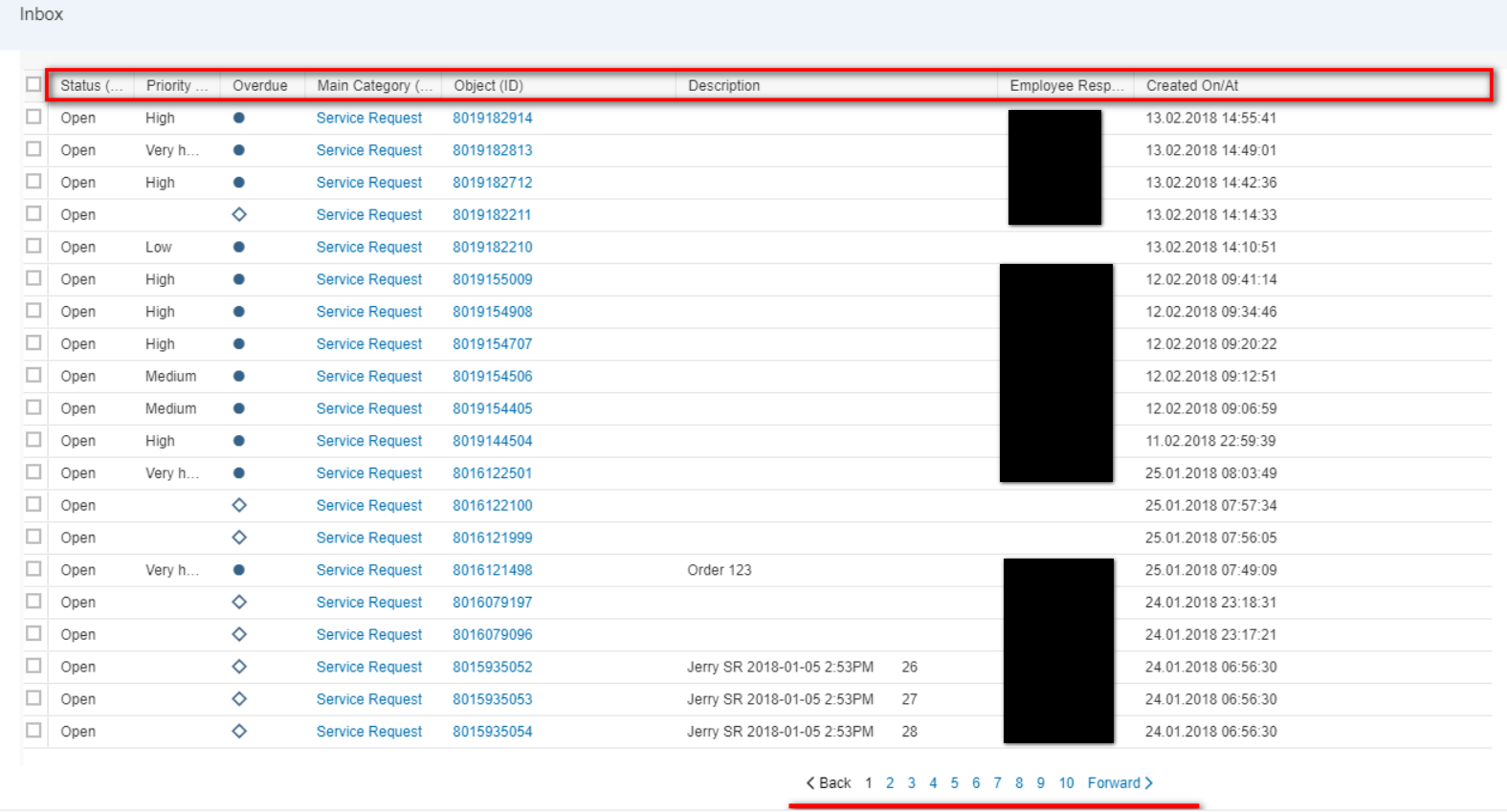
服务器怎么知道应该渲染第二页的源代码呢?这个信息也是点了“2”页码后,从前台传给ABAP服务器的:
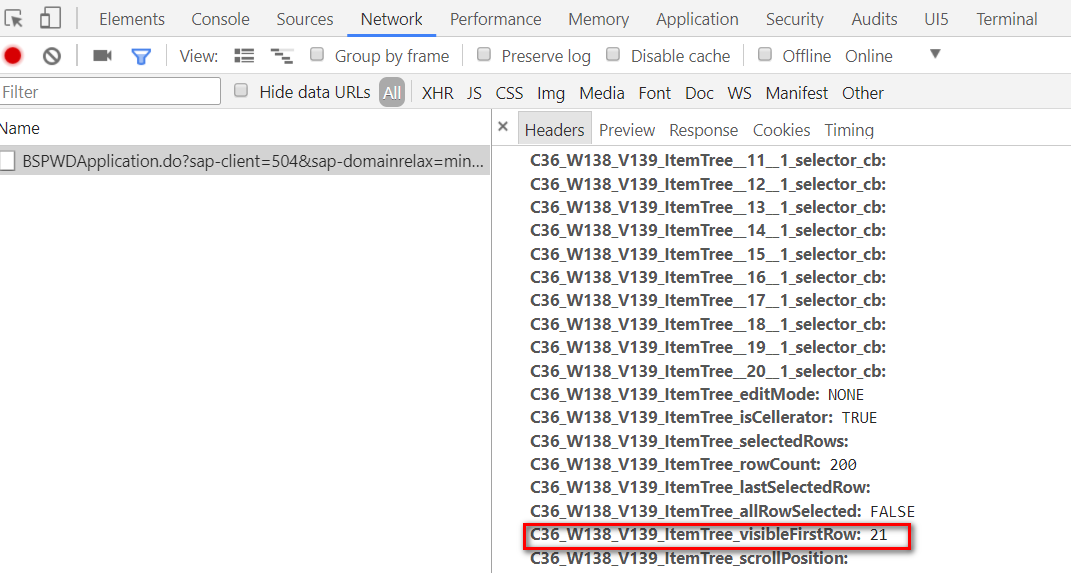
ABAP后台拿到这个visibleFirstRow参数后,知道从搜索结果记录里的第21条开始渲染,一直到第40条。

更多渲染细节,请参考我的博客:
Paging Implementation in S/4HANA for Customer Management
了解了咱们SAP的搜索分页实现原理后,让我们再来看看其他厂商是怎么做的。
像国内的知乎,简书,新浪微博这些网站,其列表显示均实现了懒加载。菜园子小哥王聪对这些实现也很好奇。为什么最后选择了Twitter去研究?这就得从他和基友老金的故事说起。
下面是菜园子小哥王聪的讲解。还是老规矩,您可以点击文末的"阅读原文”,获取王聪的中英德三个版本的讲解文章。
懒加载,看看Twitter是怎么做的
老金痛恨Twitter。
老金是我在德国读书时的好基友,在国内时就酷爱文学创作。但他却从未开通个博客什么的,坚持使用新浪“长微博”功能写文章。用他的话说,这代表新锐文学的姿态。到了德国之后,老金发现人家老外不用微博,人家用Twitter。新锐的他自然要入乡随俗,可正准备舞文弄墨,却发现Twitter里并没有个东西叫“Long Twitter”,140个字符啥也干不了。于是老金愤而卸载Twitter,逢人便感慨西方文学这下是要彻底完了。
看着老金整天闷闷不乐,我便安慰他说什么长微博,不就是文字变图片嘛。Twitter没这东西,看小爷我的本事啊。我给你写个App,名字就叫“大Twitter”,图标我都给你设计好了。

然后我用了两个晚上搞了个小工具,把大段文字转成图片,然后直接发到Twitter上。

可没想到,老金刚用了半天就找到我,说自己写的东西不知道为什么全被打上了马赛克,并信誓旦旦对“秦老师”发誓说自己没写什么大尺度的东西。我问他秦老师是谁?他说是印度著名诗人秦戈尔老师啊!善良的我并没有当面给他指出那位老师不姓秦这件事,只想着好好的图片怎么会被打码了呢?
我拿来一看,原来是老金实在憋了太久,这一次足足写了8400多个字,生成的图片尺寸过大,被鸡贼的Twitter给压缩了,于是便模糊得像打了码一样。心灰意冷的老金决定与Twitter恩断义绝,连账户都注销了。
虽然我也不怎么用Twitter,但作为一个程序员我对它还是很有兴趣的。作为同类产品中的佼佼者,Twitter自然是有它的优势。其中比较有特色的一点就是其懒加载的机制。今天我们就通过Debug的方式来对其探究一番。
一些你需要知道的概念
时间轴(Time Line): Twitter中最最重要的部分。一条条的推文组合在一起,就成了页面上中间那条长长的时间轴。
位(Position): 一条推文的标识符,说白了就是推文的ID。新推文的Position比老推文的要大,所以我觉得Position很有可能代表着“这是Twitter有史以来的第xxx条推文”。可我随便找到的一个Position却着实大得让我怀疑自己的猜测。

千里之行,始于Network
首先我们在开发者工具的Network工具中截取一条当用户滚动加载时发出的请求。结果发现它长下面这个样子。
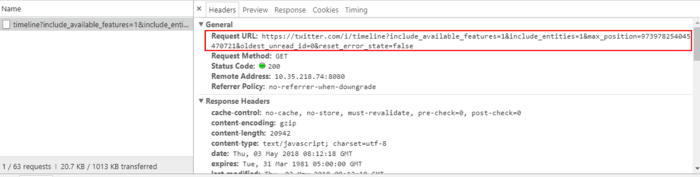
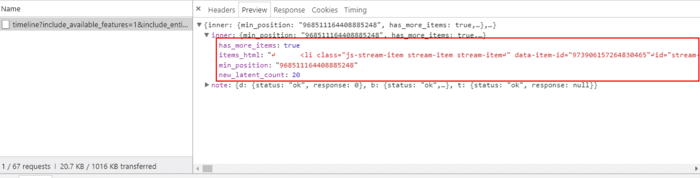
在这里我们可以发现几个有意义的信息:
- max_position:翻遍Header信息以及请求参数,这是唯一一个跟所要请求的内容相关的东西。具体含义后面再讲。
- has_more_items:顾名思义,服务器通过这个字段告诉前端是否还有更早的内容。
- items_html:格式化之后发现,这个部分就是我们所请求到的推文内容。显然Twitter使用到的是后端渲染的技术,将推文内容渲染好直接发给前端进行展示。
- min_position:恰好对应了请求当中的max_position。
- new_latent_count:这一次所请求到的推文的条数。
深入探究
为了搞清楚这些信息到底是怎么回事,我们通过寻找请求的发起者来深入到代码当中。原来Twitter在这里发送了一个XMLHttpRequest。无论是什么请求,总归要有一个处理的方法,我们在Call Stack中层层向上追溯,然后找到了请求的定义位置。

这里我们进入到请求成功的方法中继续探索。最终到达终点,items_html被添加到了时间轴当中。
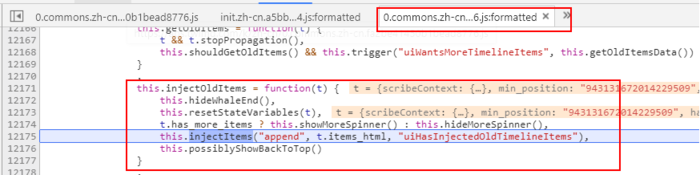

那min_position和max_position呢?我们回到刚才定义请求的位置继续向上追溯,找到了getOldItems的方法。当用户在时间轴上向下滚动鼠标到最后时,就会调用到这个方法,而在其中会把上一次响应当中的min_position赋值给这一次请求当中的max_postion。


至此我们可以将整个Twitter的懒加载流程串接起来:
- 用户向下滚动时间轴,发出请求,通知服务器“我已经把第A条看完啦,快让我看更之前的内容”。
- 服务器返回从A再往前的20条内容,并告诉用户“喏,现在发给你直到第B条的所有内容了,慢慢看吧”。
- 用户再次看完这些内容,向下滚动时间轴,告诉服务器“到第B条的我也看完啦,B之前的你再发给我吧”。
每次不一定20条?
在研究的过程中,我发现了一个有趣的现象,就是new_latent_count绝大多数都是20,而偶尔会略小于20。由于前端请求中并不存在所要请求的条数,所以这个决策是在后端完成的。
起初我以为后端会根据需要即将响应的内容大小决定发多少条,可分析了一些例子之后发现有的时候响应明明很小,却还是发了不到20条。所以我的猜测是后端这个神奇的算法可能会判断返回的内容用户大概会浏览多久,如果比较耗时,则少返回一些。例如如果推文中有长视频,则判断为阅读耗时较长,可以少返回几条。但这只是我瞎猜的,有知道其中原理的朋友可以留言告诉我,非常感谢。
Debug之痛
坦率讲整个Debug过程花费了我很多时间,一方面是对于其代码结构的不熟悉,另一方面是minify过的js代码实在是让人头疼啊。所有的变量都长成abcd不说,到处都是用逻辑运算符写的条件判断语句,看得人口吐白沫。
不过从学习的角度讲,整个过程跑下来无论是debug能力还是代码阅读能力都会有所提升,推荐大家也试一试。
更多阅读

- 点赞
- 收藏
- 关注作者
评论(0)