浅识XPath(熟练掌握XPath的语法)【python爬虫入门进阶】(03)

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
本文是爬虫专栏的第三篇,重点介绍网页解析神器XPath。
干货满满,建议收藏,需要用到时常看看。 小伙伴们如有问题及需要,欢迎踊跃留言哦~ ~ ~。
前言(为什么写这篇文章)
前面两篇文章我们分别介绍了爬虫程序的标准步骤,以及如何熟练的使用Requests库拉取网页数据。这一篇文章就重点介绍解析网页数据利器XPath。由于其比较重要,接下来我会用两篇文章进行介绍。
XPath介绍
XPath(XML Path Language)是一门XML文档中查找信息的语言,XPath可用来在XML(包括HTML)文档中对元素和属性进行查找以及遍历。后面会详细介绍XML和HTML文档的结构组成
XPath开发工具
既然XPath是用来解析网页的数据,就必须要能够通过一定的规则匹配到所需要爬取的数据。这里就要用到XPath的开发工具。
-
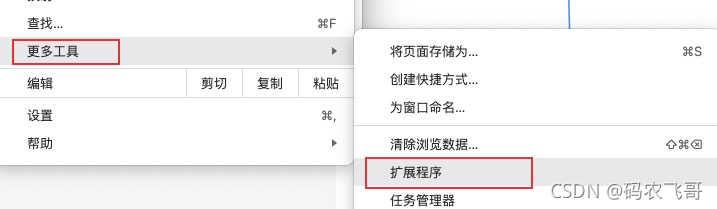
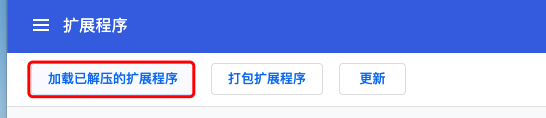
Chrome插件 XPath Helper 密码: 166h
下载好之后:设置---> 更多工具--->扩展程序--->加载已解压的扩展程序

-
Firefox插件 XPath Checker
XML文档介绍
在正式介绍XPath之前还是让我们来重新认识一个XML文档,XML是一种可扩展的标记语言(Extensible Markup Language)
它主要用来来传输数据,它的标签需要我们自行定义。
HTML文档(网页)
HTML文档也就是我们前面反复提到的网页,它是一种超文本标记语言,主要用来在浏览器上展示数据以及构建页面样式。它本质上跟XML类似,也是通过各种标签包装数据。不过它的标签不是我们自行定义的。
XML和HTML的区别
| 数据格式 | 描述 | 设计目的 |
|---|---|---|
| XML | Extensible Markup Language(可扩展标记语言) | 用于传输数据,重点是数据的内容 |
| HTML | HyperText Markup Language (超文本标记语言) | 用于显示数据和页面样式 |
| HTML DOM | Document Object Model for HTML (文档对象模型) | 通过HTML DOM,可以访问所有HTML元素,连同它们所包含的文本和属性,可以对其中的内容进行修改和删除,同时也可以创建新的元素 |
XML文档示例
<?xml version="1.0" encoding="UTF-8"?>
<responseXML>
<!--注释-->
<Detail>
<CardNo>11111</CardNo>
<CardPwd lang="en">2222</CardPwd>
</Detail>
</responseXML>
其中:
<?xml version="1.0" encoding="UTF-8"?> 命名空间节点
<responseXML> 文档节点即根节点
<CardNo>1111</CardNo>是元素节点,元素节点直接包含数据,没有子节点。
lang="en" 表示属性节点。
从上面的示例就可以清晰的看出XML文档就是由一个个节点组成。在XPath中,有七种类型的节点(Node),分别是元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。最外面的节点被称为文档节点或根节点。
HTML的示例
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>HTML示例</title>
</head>
<body>
<div id="content_views" class="htmledit_views">
<p style="text-align:center;"><strong>全网ID名:<b>码农飞哥</b></strong></p>
<p style="text-align:right;"><strong>扫码加入技术交流群!</strong></span></p>
<p style="text-align:right;"><img src="https://img-blog.csdnimg.cn/5df64755954146a69087352b41640653.png"/></p>
<div style="text-align:left;"></div>
</div>
</body>
</html>
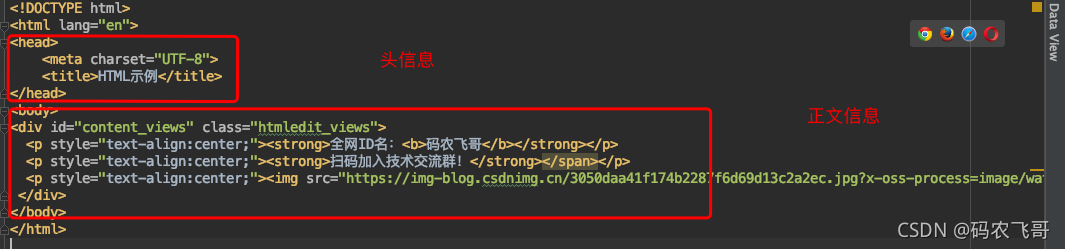
一个标准的HTML主要包括Head元素以及Body元素。head元素内主要包括标题<title> 等信息,body 元素内主要就页面的主内容了。用DOM树表示上面的HTML的结构就如下图所示。
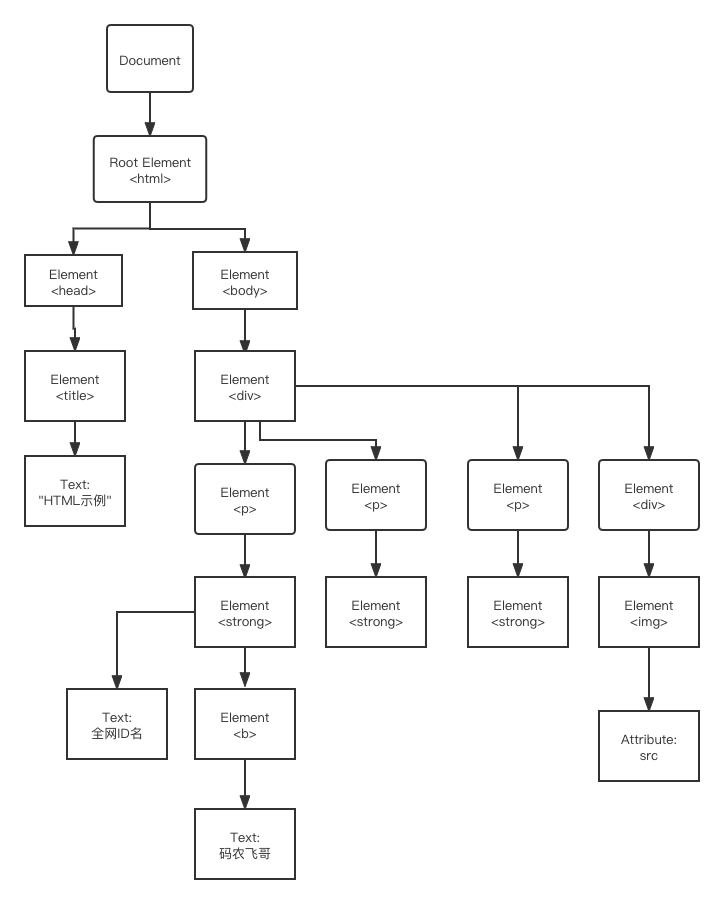
HTML元素的关系
如上图所示,我们可以整理出HTML元素的关系。
父节点(Parent)
除了根节点之外,每个元素都有一个父节点。就像每个孩子都有一个父亲一个意思。
子节点(Children)
一个元素可以有零个,一个或者多个子节点,就像每个父亲都可能有零个,一个或者多个孩子
同胞(Sibling)
拥有相同的父节点的元素,就是拥有相同父亲的兄弟
先辈(Ancestor)
某个节点的父节点的父节点,就是祖父级别,就是爷爷辈
后代(Descendant)
某个节点的子,子的子,等等,就是孙子辈
选取节点
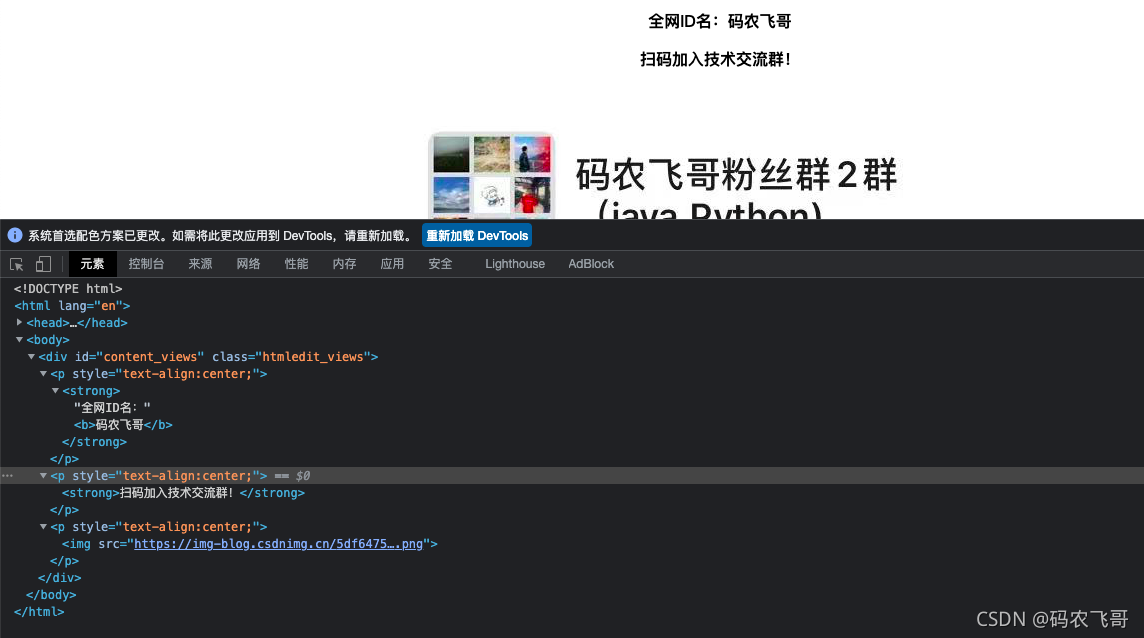
XPath使用路径表达式在XML文档(HTML文档)中选取节点,节点通过沿着路径或者跳跃(step)选取。下面就罗列比较常用的路径表达式。下面的示例还是以前面提到的HTML为例。这里将代码放在了一个XPath.html文件中。然后访问该文件。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| … | 选取当前节点的父节点 |
| @ | 选取属性 |
实例
/html获取根节点下的 html 节点
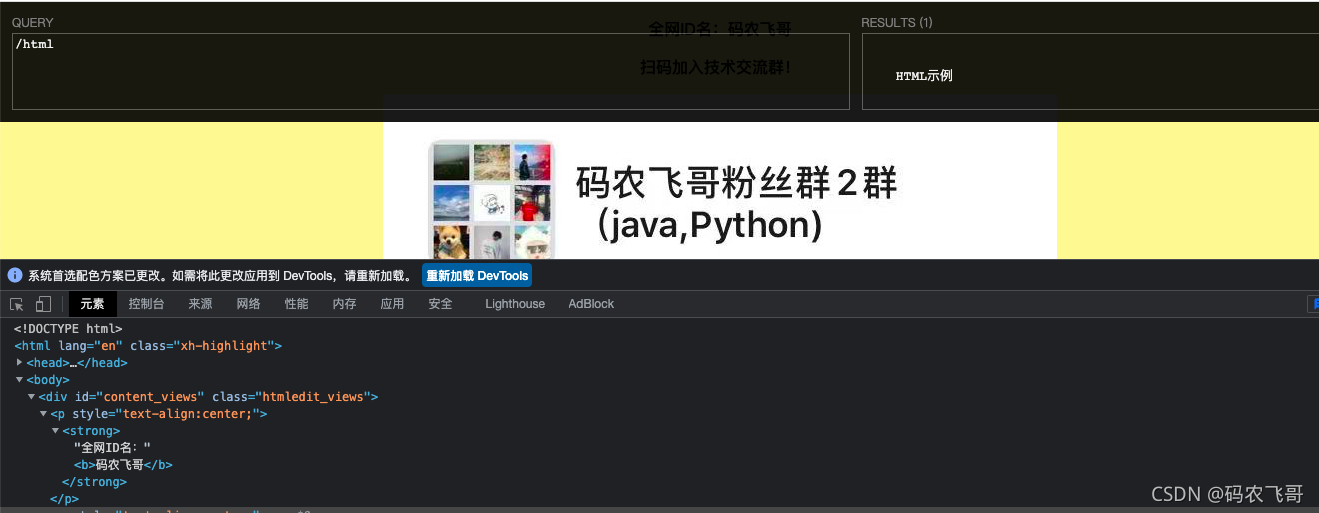
//div匹配所有的div标签以及其子节点,而不管它们在文档中的位置。
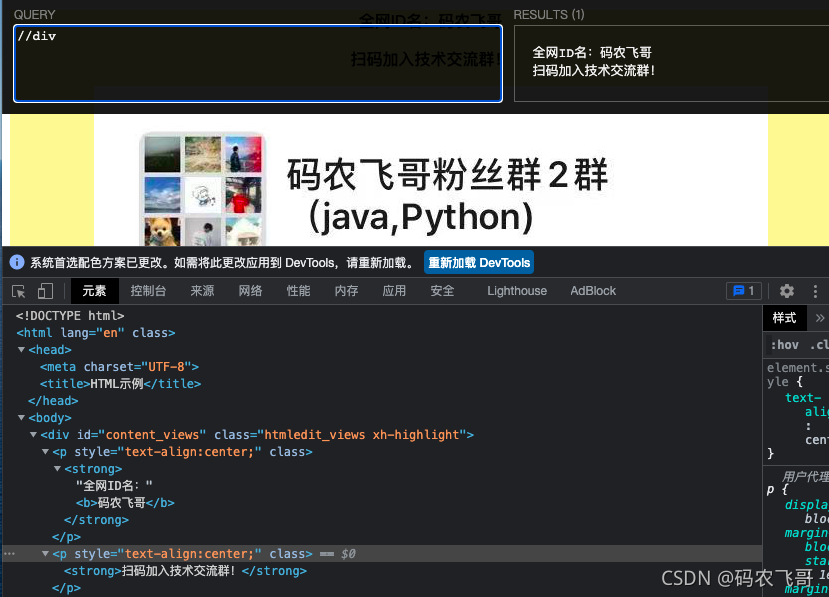
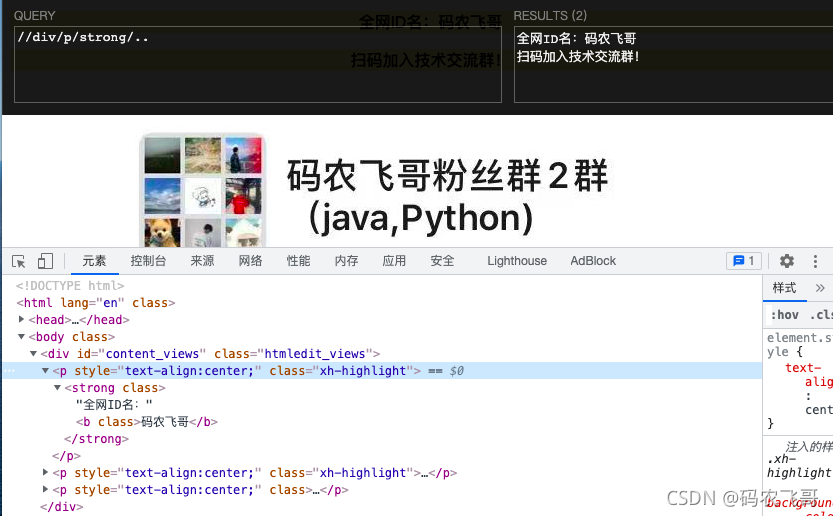
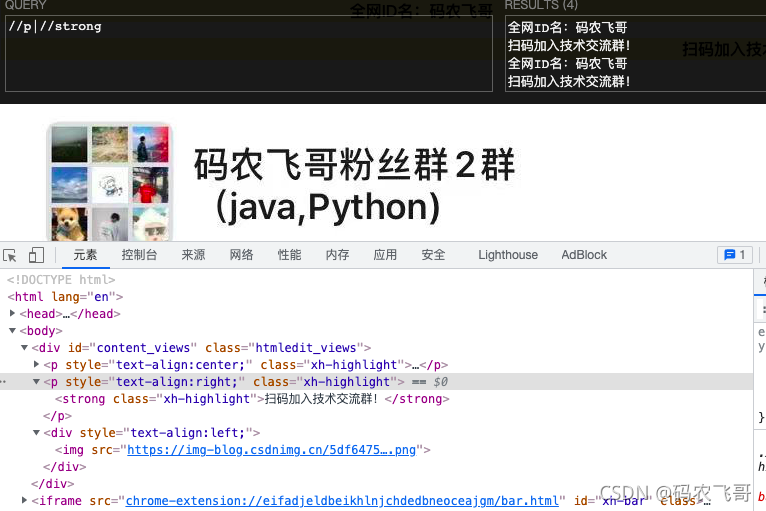
//div/p/strong/.匹配strong 当前这个元素
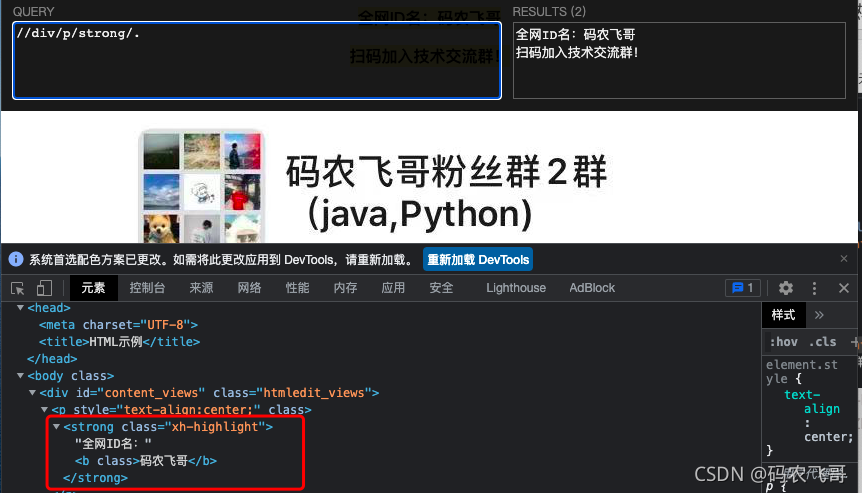
//div/p/strong/..匹配div元素下的p元素的strong元素的父节点
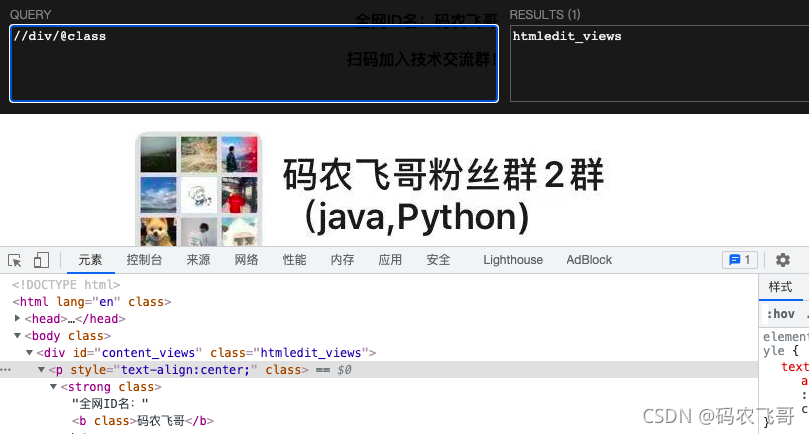
//div/@class匹配div节点下名为class属性。
谓语
谓语用来查找某个特定的节点或者包含某个指定值的节点,被嵌在方括号中。
| 路径表达式 | 结果 |
|---|---|
| //div/p[1] | 选取属于div子元素的第一个p元素 |
| //div/p[last()] | 选取属于div子元素的最后一个p元素 |
| //div/p[last()-1] | 选取属于div子元素的倒数第二个p元素 |
| //div/p[position()<3] | 选取最前面的两个属于div元素的子元素的p元素 |
| //b[@class] | 选取拥有class属性的b元素 |
| //p[@style=“text-align:right;”] | 选取包含属性style="text-align:right;"的p元素 |
通配符
XPath 通配符可用来获取未知的XML元素(包括HTML元素)
| 通配符 | 描述 |
|---|---|
| * | 匹配任何元素节点 |
| @* | 匹配任何属性节点 |
| node() | 匹配任何类型的节点。 |
举例
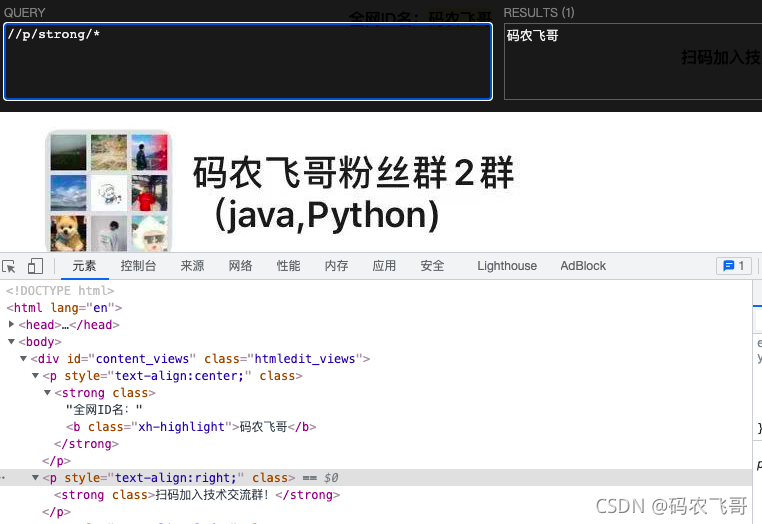
//p/strong/*选取属于p元素的子元素strong元素的所有子元素。不包括strong元素本身。
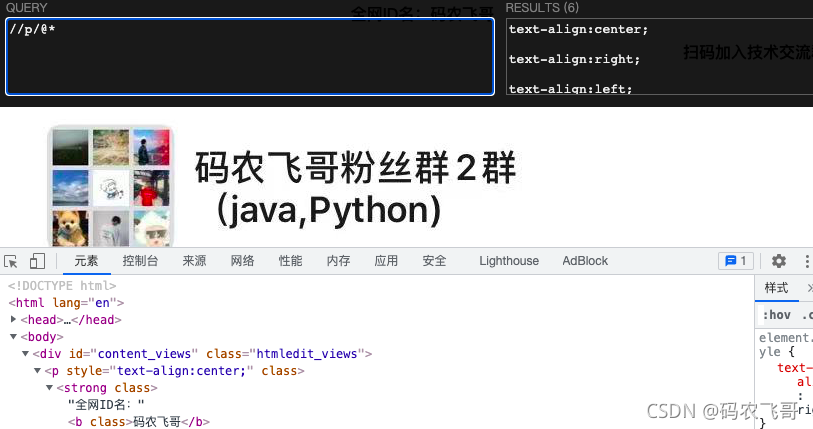
//p/@*选取属于p元素的所有属性。
选取若干路径
通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
| 路径表达式 | 结果 |
|---|---|
//div/p|//div/div |
选取div元素的所有p和div元素 |
//p | //strong |
选取文档中所有的p元素和strong元素 |
XPath的运算符
下面列出了可用在 XPath 表达式中的运算符:
| 运算符 | 描述 | 实例 | 结果 |
|---|---|---|---|
| |
计算两个节点集 | //p | //strong |
+ |
加法 | 6+4 | 10 |
- |
减法 | 5-2 | 3 |
* |
乘法 | 10*10 | 100 |
| div | 除法 | 8 div 4 | 2 |
| = | 等于 | style=“text-align:right;” | 匹配属性等于text-align:right;的style属性 |
| < | 小于 | ||
| < = | 小于等于 | ||
| > | 大于 | ||
| > = | 大于等于 | ||
| or | 或 | ||
| and | 与 | ||
| mod | 计算除法的余数 | 5 mod 2 | 1 |
总结
本文详细介绍了XPath的语法内容,在运用到Python抓取时要先转换为xml。
粉丝专属福利
软考资料:实用软考资料
面试题:5G 的Java高频面试题
学习资料:50G的各类学习资料
脱单秘籍:回复【脱单】
并发编程:回复【并发编程】
👇🏻 验证码 可通过搜索下方 公众号 获取👇🏻

- 点赞
- 收藏
- 关注作者
评论(0)