通用语义分割研究历程

前言
语义分割的目标是输入图像的每个像素分配一个标签,即像素级别的物体分类任务;主要是通过算法模型对输入图像的像素进行预测并分类,生成语义标签。
通用语义分割研究历程
1、FCN
FCN:Fully Convolution Network(FCN),也称全卷积网络,2014年,作为语义分割在深度学习领域的开山之作,它第一次将语义分割任务分解成编码器、解码器两大部分;
特点:它将图像分类网絡的最后一层全连接层替换为一系列反卷积层,使得经过下采样的特征图层可以通过反卷积层上采样恢复回输入图像分辨率,从而完成像素级别的物体分类任务。自此,语义分割网络的基本结构大都沿用FCN采用的编码器-解码器(Encoder-Decoder)的结构。
模型思路:该方法将 VGG 基本分类网络作为编码器,将输入的图片经过编码器中的多个卷积层来进行特征提取和下采样操作之后,其分辨率降低为原始输入图片的 1/32 从而得到编码 器输出特征图,然后在解码器阶段通过上采样算法将所得到的特征图恢复到原始图片大 小,得到分割结果。
FCN 对细节信息的不足导致类别之间的边界轮廓等分割不明显。整体网络对小目标物体的分割效果不佳,同时类别之间的上下文关系并没有很好地捕获,导致各个类别之间容易产生混淆。
2、UNet
UNet:随后Olaf Ronneberger 等人提出的UNet,在编码器和解码器之间,通过采用跳跃连接将编码器获取的低级特征信息(Low-level,表征图像的纹理、色彩、明暗、轮廓等信息)和解码器获取的高级特征信息(High-level,富含语音信息、表征物体类别的信息)进行拼接,从而弥补了由于快速下采样而导致的图像边缘细节信息丢失的问题。
U-net 网络在定位准确性和获取上下文信息中需要权衡,影响了模型的效果。同时,U-net 网络在分割的过程中存在很多以像素为中 心的重叠区域,导致计算量大,冗余计算多。
3、SegNet
SegNet:2015 年,Badrinarayanan 等人在 FCN 的基础上提出面向城市道路环境的语义分割模型 SegNet。它将反卷积替换为反池化层,利用编码器阶段带索引的池化信息去恢复特征图。
特点:池化层记录像素点的空间位置,为解码器能够快速有效地找回对应的位置提供便利,从而快速有效地找回位置实现精准的上采样。
模型结构:
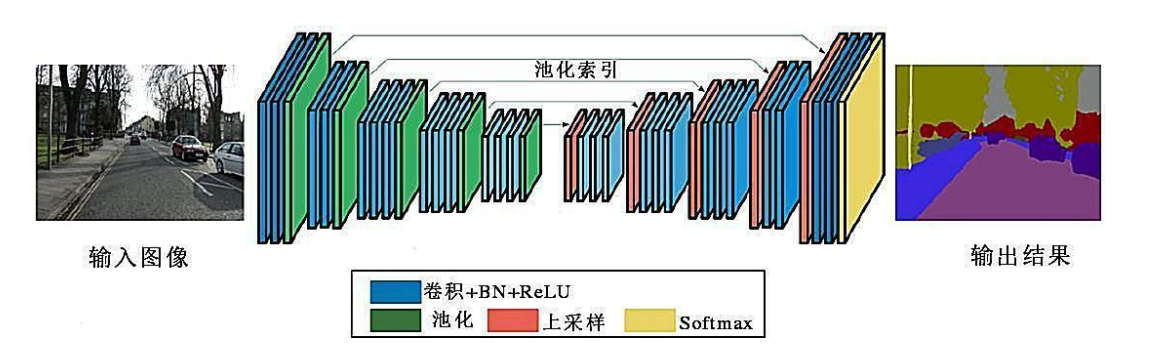
但是由于 SegNet 对特征信息并没有很好地融合,物体边界轮廓的分割效果较差。
4、RefineNet
RefineNet:为了更好地融合特征,2017 年 Lin 等人提出了 RefineNet 网络模型,该模型的主要思想是将不同分辨率的特征图以特定的方式进行融合,使用这种融合方式主要是为 了解决小目标物体的分割精度低的问题。
由于这样的融合操作使得整体网络结构 较复杂,不免会有参数量大的缺点。
5、DeepLab v1
DeepLab V1:提出的膨胀卷积(空洞卷积)在不增加模型复杂的的情况下增大了模型的感受野,并在最终的分类阶段结合条件随机场(Conditional Random Field,CRF)来修正分割结果。
空洞卷积结构应用于语义分割领域最具有代表性的工作是由谷歌公司提出的 DeepLab 系列模型。2014 年提出的 DeepLab v1 模型使用不同采样率的空洞卷积来聚 合不同尺度的感受野从而解决多尺度目标的分割问题。为了得到更加精细的结果,在后 处理环节使用了条件随机场算法。同时,在论文中也引入了多尺度训练的技巧,为之后 的方法提高语义分割精度提供了参考。
6、DeepLab v2
DeepLab V2 :在DeepLab V1基础上通过编码器和解码器中加入ASPP(Atrous Spatial Pyramid Pooling)模块,使得网络可以提取不同大小特征图的信息进而增加感受野,从而提升分割表现。
2017 年,Chen 通过改进 DeepLab v1 模型提出了 DeepLab v2 模型,模型中通过带空洞卷积的空间池化金字塔 ASPP(Atrous Sptial Pyramid Pooling)结构进一步聚合不 同尺度的感受野并捕捉图像的上下文信息。同样地,同年所提出的 DeepLab v3 模型通过将全局平均池化和 1 *1卷积引入到 ASPP 结构中来捕获全局信息。但是 DeepLab v3 模型分辨率恢复环节较为粗糙,同时由于采用空洞卷积来聚合感受野信息,这极大的增加了内存消耗。
7、PSPNet
PSPNet:通过“不同尺寸的池化层”并利用“金字塔池化结构”更好地提取局部上下文信息和全局信息从而达到良好地分割变现。
2017 年 Zhao 等人提出的 PSPNet 网络通过 使用不同内核大小的池化层完成多尺度信息的融合,并使用全局池化层为整个网络提供 相应的全局信息,有利于细节信息的把握。另外,网络中加入了额外的深度监督损失。
8、DeepLab v3
DeepLab 的 v3+:为改进 DeepLab v3 网络模型的缺点,2018 年 DeepLab 的 v3+网络模型被提出, 新版本的网络结构以改进版的 Xception作为基础网络,并在 DeepLab v3 的基础上加 入解码器,在解码器中直接将编码器的输出上采样4倍,使其分辨率和低层特征图一致, 对物体边缘信息有很好的保留。
模型结构:
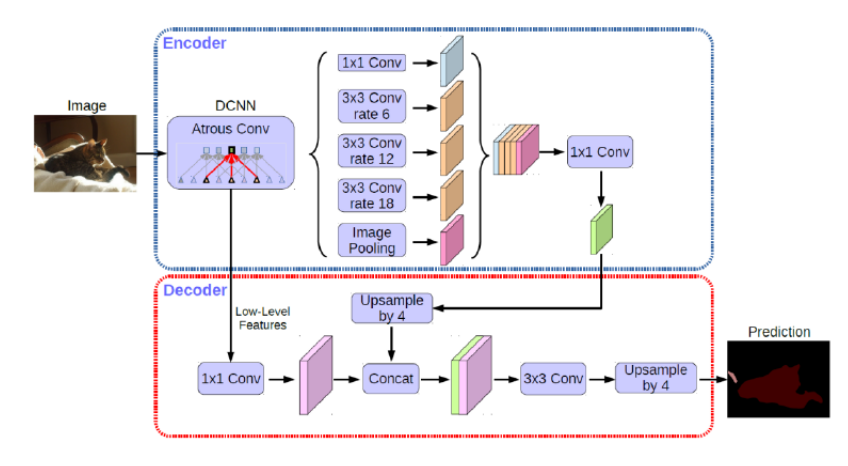

- 点赞
- 收藏
- 关注作者
评论(0)