效果提升7%、速度增加220%,OCR开源神器PaddleOCR再迎升级

-
论文地址:https://arxiv.org/abs/2109.03144
-
项目地址:https://github.com/PaddlePaddle/PaddleOCR
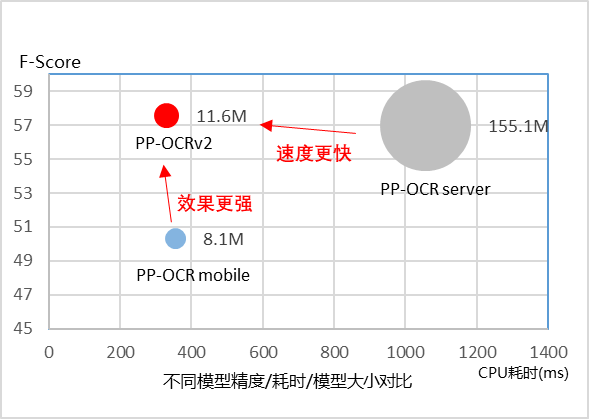
从效果上看,PP-OCRv2 主要有三个方面提升:
-
在模型效果上,相对于 PP-OCR mobile 版本提升超 7%;
-
在速度上,相对于 PP-OCR server 版本提升超过 220%;
-
在模型大小上,11.6M 的总大小,服务器端和移动端都可以轻松部署。
为了让读者了解更多技术细节,飞桨 PaddleOCR 原创团队针对 PP-OCRv2 进行了更加深度的独家解读,希望可以对大家的工作学习有所帮助。
PP-OCRv2 五大关键技术改进点深入解读
全新升级的 PP-OCRv2 版本,整体框架图保持了与 PP-OCR 相同的 Pipeline,如下图所示:
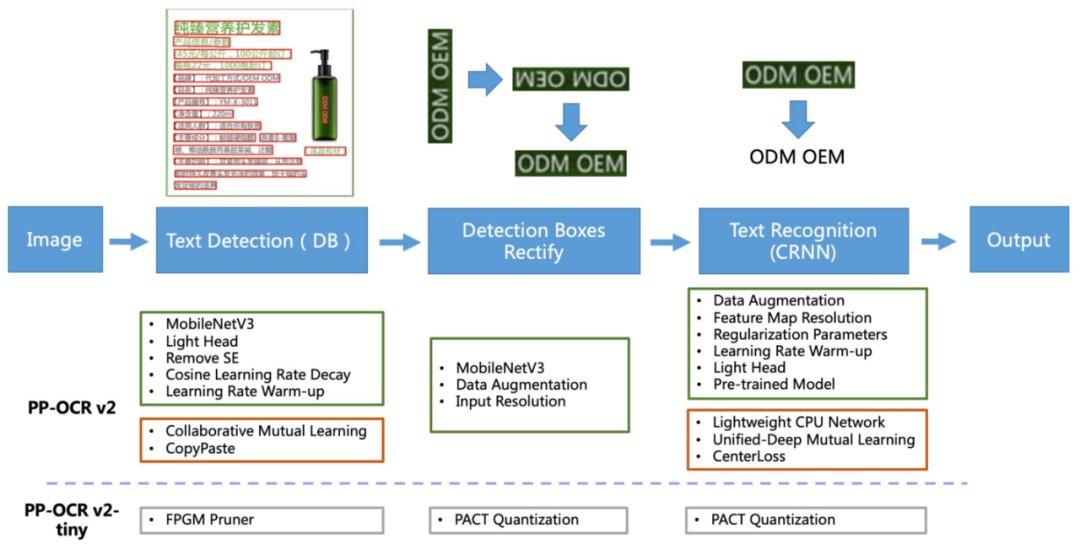
在优化策略方面,主要从五个角度进行了深入优化(如上图红框所示),主要包括:
检测部分优化两项:
-
采用协同互学习(Collaborative Mutual Learning, CML) 知识蒸馏策略
-
CopyPaste 数据增广策略
识别部分优化三项:
-
LCNet 轻量级骨干网络(Lightweight CPU Network)
-
UDML 知识蒸馏策略
-
Enhanced CTC loss 改进
下面展开详细介绍。
检测模型优化:采用 CML 知识蒸馏策略
如下图所示,标准的蒸馏方法是通过一个大模型作为 Teacher 模型来指导 Student 模型提升效果,而后来又发展出 DML 互学习蒸馏方法,即通过两个模型结构相同的模型互相学习。这两种算法都是两个模型之间,而最新在 PP-OCRv2 中使用的是三个模型之间的 CML 协同互蒸馏方法,既包含两个相同结构的 Student 模型之间互学习,同时还引入了较大模型结构的 Teacher 模型。
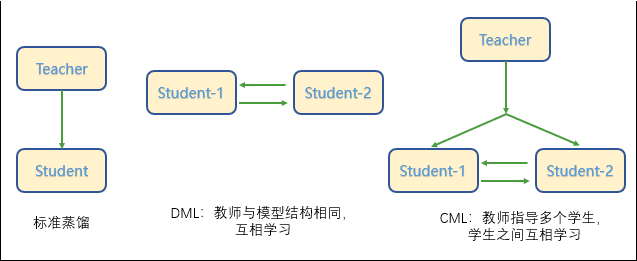
这样,CML 的核心思想结合了①传统的 Teacher 指导 Student 的标准蒸馏与 ②Students 网络之间的 DML 互学习,这种思想其实也是和实际学校里面鼓励大家互相讨论同时教师指导的模式比较相似,可以让 Students 学的效果更好。
具体的网络结构和精心设计关键的三个 Loss 损失函数如下图所示:
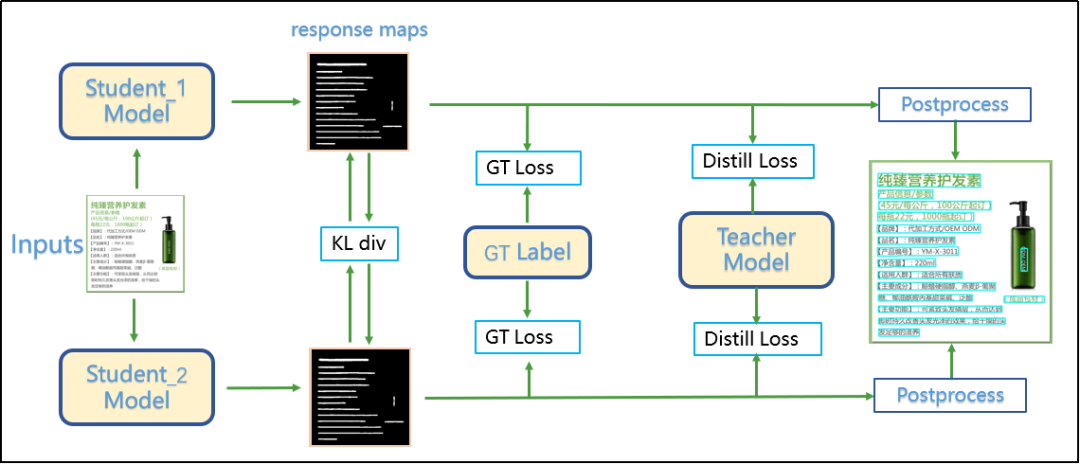
① DML Loss:对于一张输入训练图片,分别送到两个 Student 网络,这里采用的是 DBNet 检测模型,输出对应的概率图(response maps),然后对比两个网络之间的 DML loss,这里采用的是散度的方法,对应的公式如下所示,其中 S1 和 S2 对应两个 Student 网络,KL 是散度计算公式:
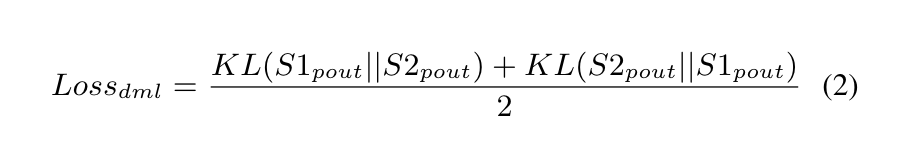
② GT Loss:标准的 DBNet 训练任务如下图所示:
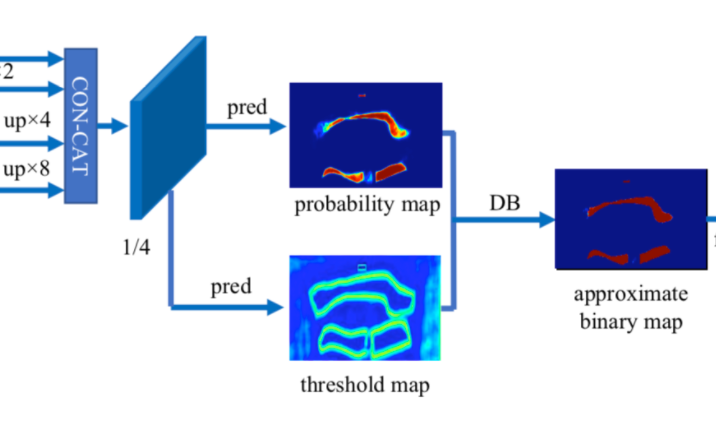
其输出主要包含以上三种 feature map,具体如下表所示:

GT Loss 可以表示为:
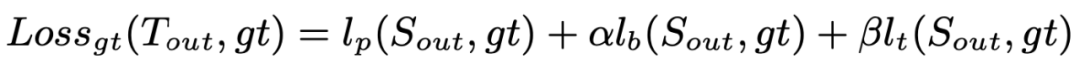
③ Distill Loss:第三部分是来自 teacher 的监督信号,其只对特征 Probability map Binary map 做蒸馏。另外,从实际经验看,对 Teacher 的输出做膨胀操作 (f_dila()), 可以增强 Teacher 的表达能力,提升 Teacher 精度约 2%,从而提升蒸馏效果,对应的函数可以表示为:
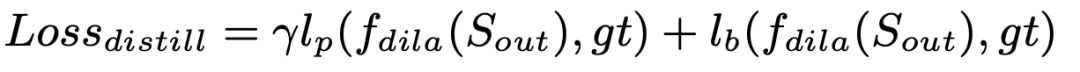
其中 是默认超参设置为 5,分别是交叉熵 loss 和 Dice Loss,是膨胀函数。
④ 最终,所有的 Loss 函数加起来,就是最终的 Loss 函数,如下所示:
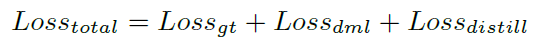
这里,关于三个 Loss 函数的权重分配,也可以再调整或者学习一些超参,有兴趣的开发者可以继续尝试。
检测模型优化:CopyPaste 数据增广策略
在实际的检测模型训练过程中,经常会遇到两个问题:①样本丰富度不足,主要体现在标注大量数据成本很高,而且对于采集过程和采集的丰富多样性也有要求; ②模型对环境鲁棒性较差,相同的文字分布,在不同背景下的检测结果却相差较多。
这样很容易想到采用数据增广作为提升模型泛化能力重要的手段,CopyPaste 是一种新颖的数据增强技巧,已经在目标检测和实例分割任务中验证了有效性。利用 CopyPaste,可以合成文本实例来平衡训练图像中的正负样本之间的比例。

相比而言,传统图像旋转、随机翻转和随机裁剪是无法做到的。CopyPaste 主要步骤包括:
-
随机选择两幅训练图像;
-
随机尺度抖动缩放;
-
随机水平翻转;
-
随机选择一幅图像中的目标子集;
-
粘贴在另一幅图像中随机的位置。
这样就比较好地提升了样本丰富度,同时也增加了模型对环境的鲁棒性。如下图所示,通过在第二张图中裁剪出来的文本,随机旋转缩放之后粘贴到第一张图像中,进一步丰富了文本在不同背景下的多样性。

经过以上两个检测方向的优化策略,PP-OCRv2 检测部分的实验效果如下表所示:

可以看到,由于蒸馏和数据增强不影响模型的结构,所以整体的模型大小和预测速度没有变化,但是精度指标上,以 Hmean 计算,增加了 3.6%,还是比较明显的。
识别模型优化:自研 LCNet 轻量级骨干网络
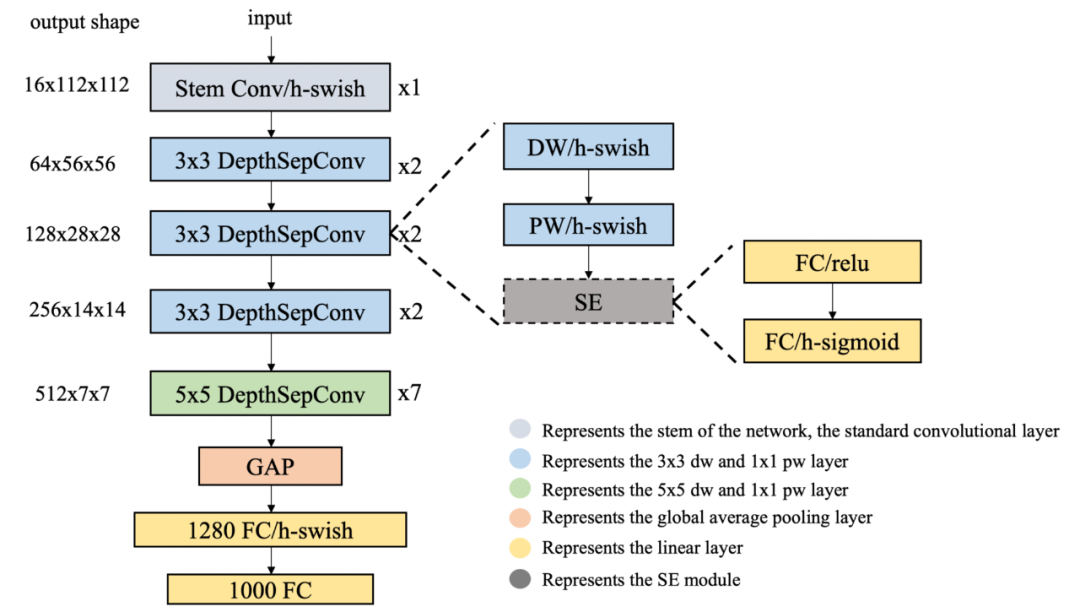
这里,PP-OCRv2 的研发团队提出了一种基于 MobileNetV1 改进的新的骨干网络 LCNet,主要的改动包括:
-
除 SE 模块,网络中所有的 relu 替换为 h-swish,精度提升 1%-2%;
-
LCNet 第五阶段,DW 的 kernel size 变为 5x5,精度提升 0.5%-1%;
-
LCNet 第五阶段的最后两个 depthSepconv block 添加 SE 模块,精度提升 0.5%-1%;
-
GAP 后添加 1280 维的 FC 层,增加特征表达能力,精度提升 2%-3%。
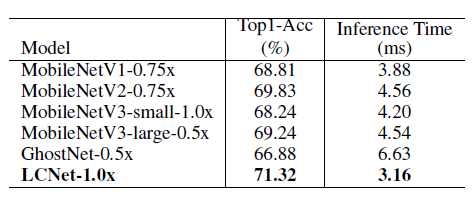
在 ImageNet-1k 数据集上验证,可以看到,LCNet 不仅在精度上遥遥领先其它的轻量级骨干网络,同时在 CPU 上的预测速度也取得了明显的优势。
识别模型优化:UDML 知识蒸馏策略
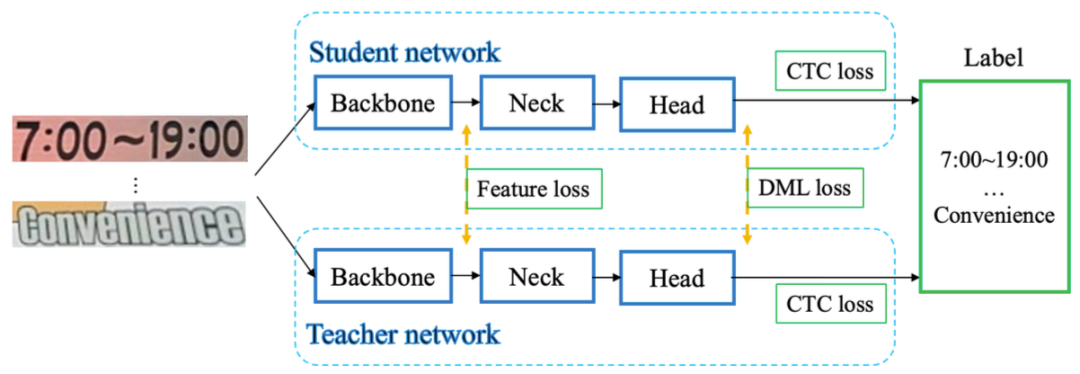
在标准的 DML 知识蒸馏的基础上,新增引入了对 Feature Map 的监督机制,新增 Feature Loss,然后结合 CRNN 基础的 CTC Loss 和蒸馏引入的 DML Loss,最终分别计算再求和之后,所有的 Loss 函数可以表示为:

另外,在训练过程中通过增加迭代次数,在 Head 部分添加 FC 网络等 trick,平衡模型特征编码与解码的能力,进一步提升了模型效果。
识别模型优化:Enhanced CTC loss 改进
考虑到中文 OCR 任务经常遇到的识别难点是相似字符数太多,容易误识。因此借鉴 Metric Learning 的想法,引入 Center Loss,进一步增大类间距离,核心思路如下图公式所示:

同时,Enhance-CTC 的初始化过程对结果也有较大影响,主要包括:
-
基于原始的 CTCLoss,训练一个网络;
-
提取出训练集中识别正确的图像集合,计为 G;
-
将 G 中的图片依次输入网络, 提取 80 个 timestamp 的 xt 和 yt 的对应关系,其中 yt 计算方式如下:
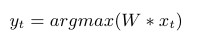
-
将相同 yt 对应的 xt 聚合在一起,取其平均值,作为初始 center。
这样,经过以上三个检测方向的优化策略,PP-OCRv2 检测部分的实验效果如下:

可以看到,经过一系列优化,虽然识别模型的大小有所增加,但是整体的精度和速度都取得了明显的提升。
并且,经过以上五个方向的优化,最终 PP-OCRv2 仅以少量模型大小增加的代价,全面超越 PP-OCR,取得了良好的效果,如下图所示:
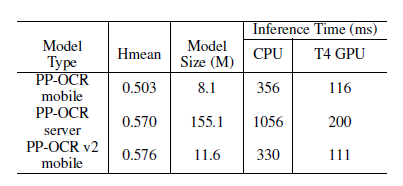
飞桨产业级模型库中的 PP 系列模型
除了 PP-OCRv2,为了更好地满足企业用户实际的产业需求,飞桨陆续发布了 PP 系列模型,可以满足用户在物品识别、目标检测、人像分割、文本识别、图像超分、自然语言处理等一系列任务。由于篇幅所限,概要介绍如下,有需求的用户可以到 Github 了解更多:
(1)PP-ShiTu(即将发布):超轻量通用图像识别系统,高效解决商品识别、车辆识别等场景中的识别问题,并可快速迁移到其他图像识别任务中。

(2)PP-YOLOv2:目标检测任务上 AP 和速度等综合性能超过 YOLOv5,其中一版本可达 50.3%AP 和 50.3FPS。
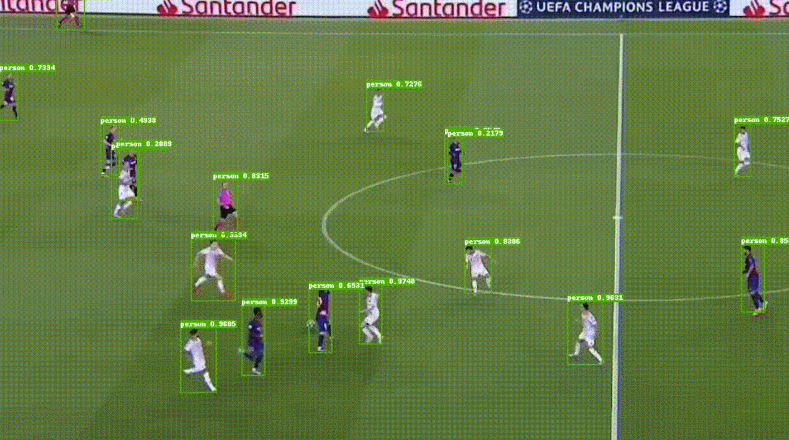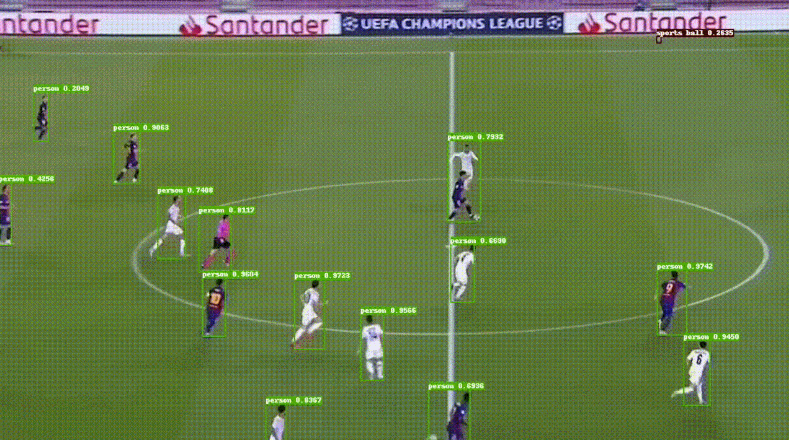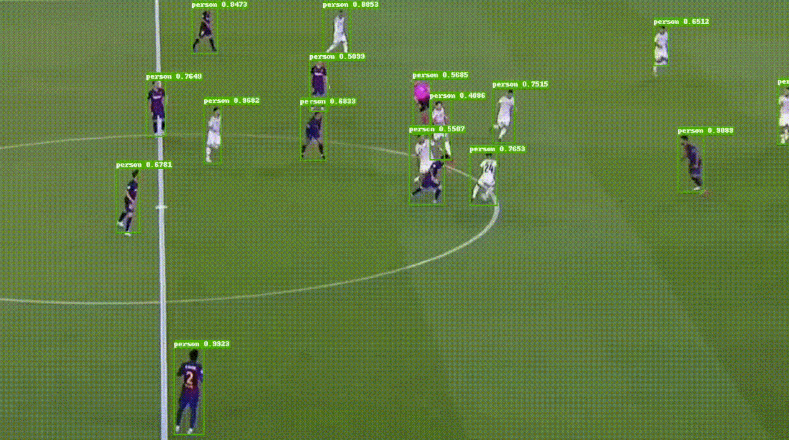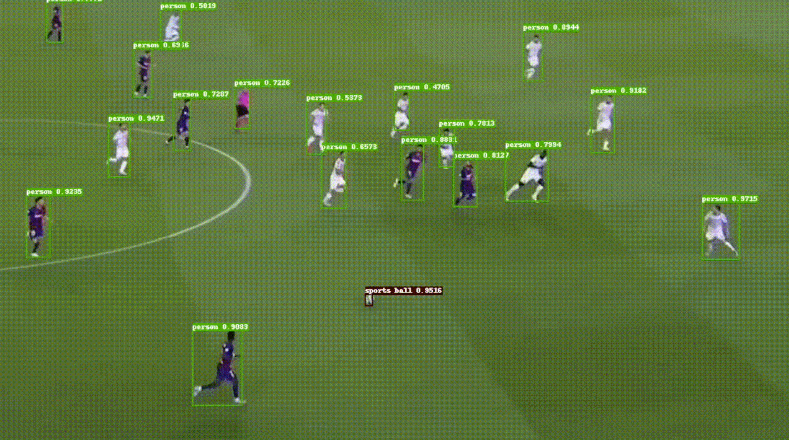
(3)PP-HumanSeg:轻量级人像分割,手机端的精度和速度表现都很出色。

(4)PP-Structure:支持文档版面分析、结构化和表格识别,是目前业界最丰富的文档分析解决方案。

(5)PP-VSR:视频超分 SOTA 模型,REDS、Vid4 数据集精度达到最优,效果惊艳。

快速打造明星模型背后的强力支撑:
面向产业用户需求的设计理念和飞桨动静统一的开发体验
源于多年的产业实践,飞桨深刻洞察企业对于产业模型的需求,核心就是以下两个要点:
-
模型效果好,满足业务需求;
-
预测部署方便,速度快,节省资源。
这两个需求对应到深度框架的编程模式来看的话,分别就是动态图编程(调试方便)和静态图部署(性能好)。这里介绍一下:动态图和静态图是深度学习框架常用的两种模式。
在动态图模式下,代码编写运行方式符合 Python 程序员的习惯,易于调试,但在性能方面, Python 执行开销较大,与 C++ 有一定差距。相比动态图,静态图在部署方面更具有性能的优势。静态图程序在编译执行时,预先搭建好的神经网络可以脱离 Python 依赖,在 C++ 端被重新解析执行,而且拥有整体网络结构也能进行一些网络结构的优化。
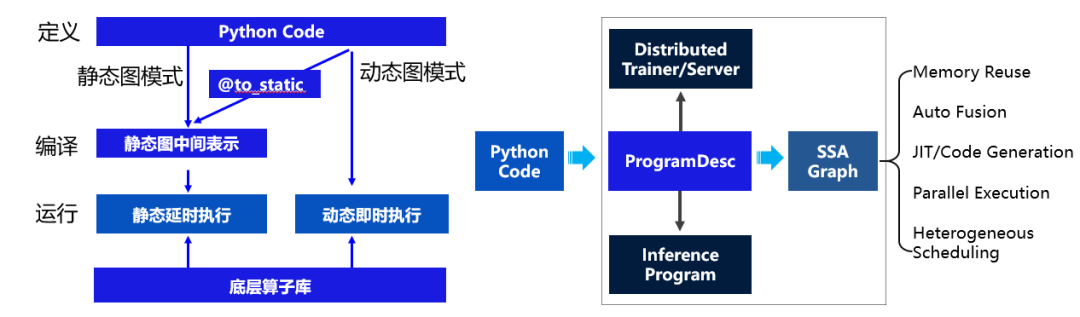
飞桨核心框架设计过程中,也是敏锐地抓住用户真实的需求,提供了动静统一的能力,支持用户使用动态图编写组网代码。预测部署时,通过动静转换接口,会对用户代码进行分析,自动转换为静态图网络结构,兼顾了动态图易用性和静态图部署性能两方面的优势。
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/120584803

- 点赞
- 收藏
- 关注作者
评论(0)