2021年大数据Spark(一):框架概述

目录
Spark框架概述
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据出来框架。Spark生态栈也称为BDAS,是伯克利AMP实验室所开发的,力图在算法(Algorithms)、机器(Machines)和人(Person)三种之间通过大规模集成来展现大数据应用的一个开源平台。AMP实验室运用大数据、云计算等各种资源以及各种灵活的技术方案,对海量数据进行分析并转化为有用的信息,让人们更好地了解世界。
Spark的发展历史,经历过几大重要阶段,如下图所示:
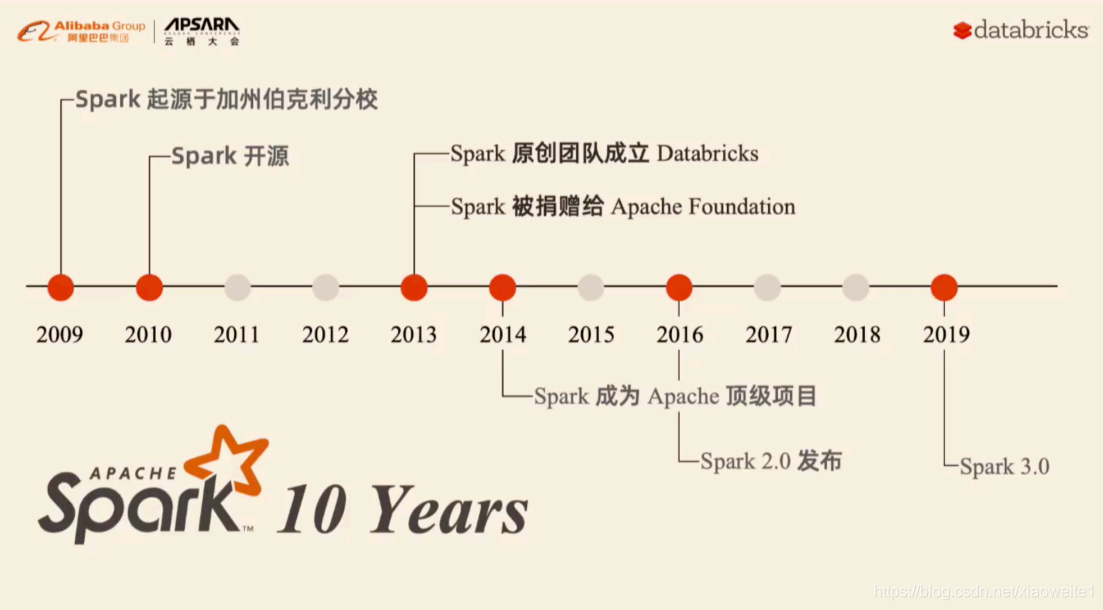
Spark 是一种快速、通用、可扩展的大数据分析引擎,2009 年诞生于加州大学伯克利分校 AMPLab,2010 年开源, 2013年6月成为Apache孵化项目,2014年2月成为 Apache 顶级项目,用 Scala进行编写项目框架。
Spark 是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
分布式内存迭代计算框架
官方网址:http://spark.apache.org/、https://databricks.com/spark/about

官方定义:

Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念,原文开头对其的解释是:
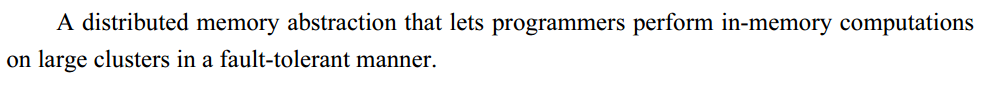
翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做
内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平
台都围绕着RDD进行。

文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115569198

- 点赞
- 收藏
- 关注作者
评论(0)