2021年大数据Spark(二):四大特点

目录
Spark 四大特点
Spark 使用Scala语言进行实现,它是一种面向对、函数式编程语言,能够像操作本地集合一样轻松的操作分布式数据集。Spark具有运行速度快、易用性好、通用性强和随处运行等特点。

速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
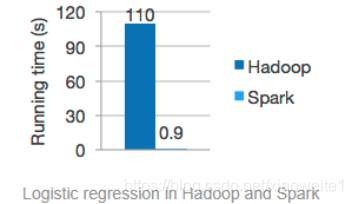
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- 其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;


- 其二、Spark Job调度以DAG方式,并且每个任务Task执行以线程(Thread)方式,并不是像MapReduce以进程(Process)方式执行。

2014 年的如此Benchmark测试中,Spark 秒杀Hadoop,在使用十分之一计算资源的情况下,相同数据的排序上,Spark 比Map Reduce快3倍!

易于使用
Spark 的版本已经更新到 Spark 2.4.5(截止日期2020.05.01),支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。
通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。其中,Spark SQL 提供了结构化的数据处理方式,Spark Streaming 主要针对流式处理任务(也是本书的重点),MLlib提供了很多有用的机器学习算法库,GraphX提供图形和图形并行化计算。

运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。

对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。

文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115577438

- 点赞
- 收藏
- 关注作者
评论(0)