2021年大数据Spark(七):应用架构基本了解

Spark 应用架构-了解
Driver 和Executors
从图中可以看到Spark Application运行到集群上时,由两部分组成:Driver Program和Executors。
第一、Driver Program
- 相当于AppMaster,整个应用管理者,负责应用中所有Job的调度执行;
- 运行JVM Process,运行程序的MAIN函数,必须创建SparkContext上下文对象;
- 一个SparkApplication仅有一个;
第二、Executors
- 相当于一个线程池,运行JVM Process,其中有很多线程,每个线程运行一个Task任务,一个Task运行需要1 Core CPU,所有可以认为Executor中线程数就等于CPU Core核数;
- 一个Spark Application可以有多个,可以设置个数和资源信息;

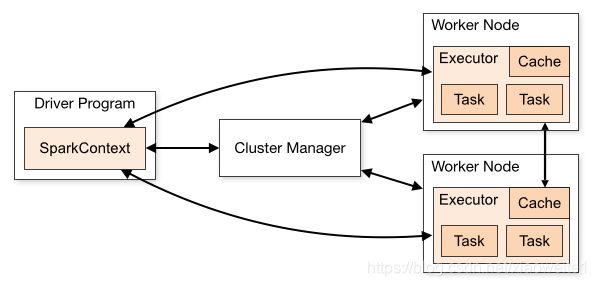
Driver Program是用户编写的数据处理逻辑,这个逻辑中包含用户创建的SparkContext。SparkContext 是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互,包括向它申请计算资源等。 Cluster Manager负责集群的资源管理和调度,现在支持Standalone、Apache Mesos和Hadoop的 YARN。Worker Node是集群中可以执行计算任务的节点。 Executor是在一个Worker Node上为某应用启动的一个进程,该进程负责运行任务,并且负责将数据存在内存或者磁盘上。Task 是被送到某个Executor上的计算单元,每个应用都有各自独立的 Executor,计算最终在计算节点的 Executor中执行。
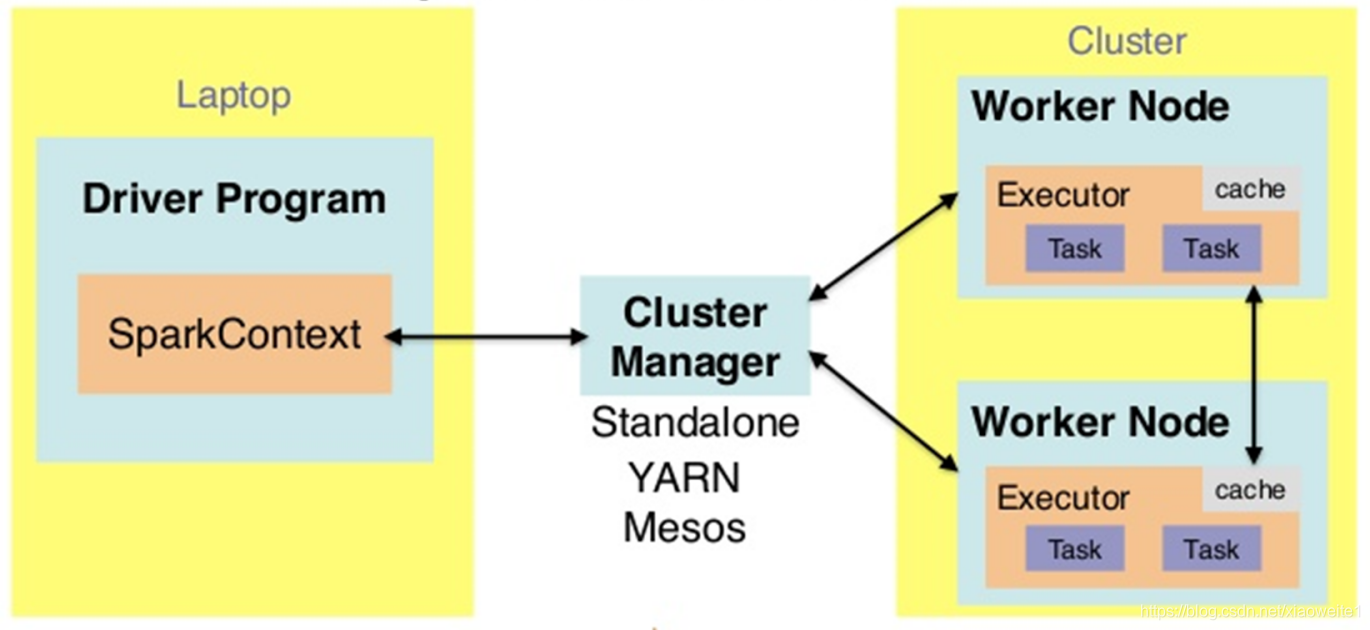
用户程序从最开始的提交到最终的计算执行,需要经历以下几个阶段:
1)、用户程序创建 SparkContext 时,新创建的 SparkContext 实例会连接到 ClusterManager。 Cluster Manager 会根据用户提交时设置的 CPU 和内存等信息为本次提交分配计算资源,启动 Executor。
2)、Driver会将用户程序划分为不同的执行阶段Stage,每个执行阶段Stage由一组完全相同Task组成,这些Task分别作用于待处理数据的不同分区。在阶段划分完成和Task创建后, Driver会向Executor发送 Task;
3)、Executor在接收到Task后,会下载Task的运行时依赖,在准备好Task的执行环境后,会开始执行Task,并且将Task的运行状态汇报给Driver;
4)、Driver会根据收到的Task的运行状态来处理不同的状态更新。 Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor 所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)、Driver 会不断地调用Task,将Task发送到Executor执行,在所有的Task 都正确执行或者超过执行次数的限制仍然没有执行成功时停止;
Job、DAG和Stage
还可以发现在一个Spark Application中,包含多个Job,每个Job有多个Stage组成,每个Job执行按照DAG图进行的。
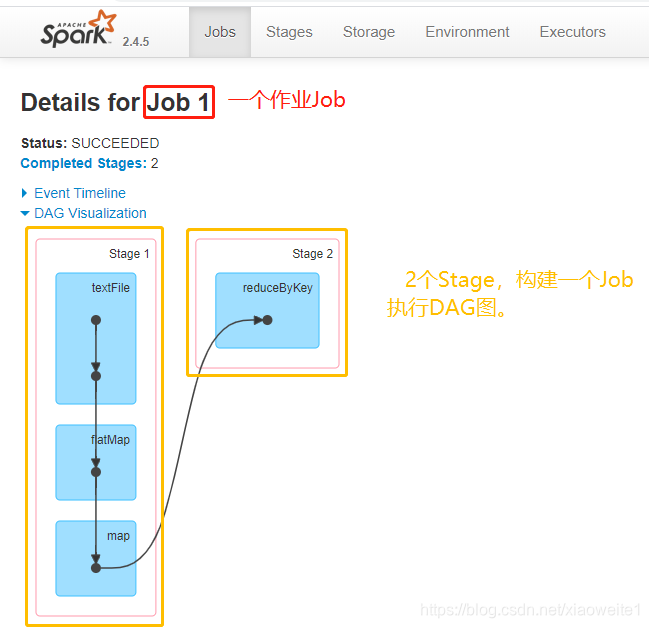
其中每个Stage中包含多个Task任务,每个Task以线程Thread方式执行,需要1Core CPU。

可以看到Spark为应用程序提供了非常详尽的统计页面,每个应用的Job和Stage等信息都可以在这里查看到。通过观察应用详情页的各个信息,对进一步优化程序,调整瓶颈有着重要作用,后期综合项目案例详细讲解。
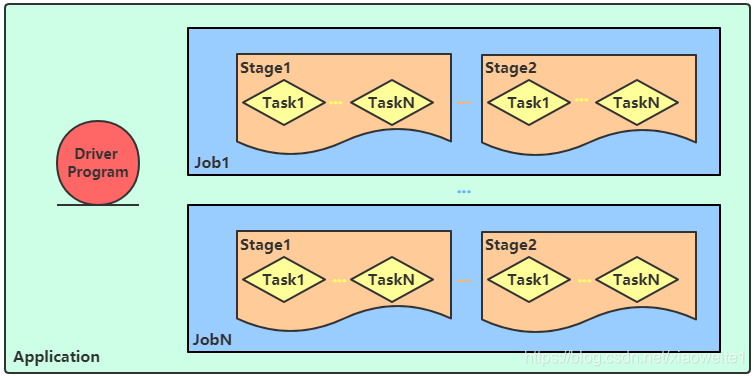
Spark Application程序运行时三个核心概念:Job、Stage、Task,说明如下:
- Task:被分配到各个 Executor 的单位工作内容,它是 Spark 中的最小执行单位,一
般来说有多少个 Paritition(物理层面的概念,即分支可以理解为将数据划分成不同
部分并行处理),就会有多少个 Task,每个 Task 只会处理单一分支上的数据。 - Job:由多个 Task 的并行计算部分,一般 Spark 中的 action 操作(如 save、collect,后面进一步说明),会生成一个 Job。
- Stage:Job 的组成单位,一个 Job 会切分成多个 Stage,Stage 彼此之间相互依赖顺序执行,而每个 Stage 是多个 Task 的集合,类似 map 和 reduce stage。
文章来源: lansonli.blog.csdn.net,作者:Lansonli,版权归原作者所有,如需转载,请联系作者。
原文链接:lansonli.blog.csdn.net/article/details/115586793

- 点赞
- 收藏
- 关注作者
评论(0)